
Page 62 - Vol.47
P. 62
Tech
Notes
技術專文
3. 研究方法 RMSE、MAPE作為KPI,數值愈低者代表預測與實際數值誤差
愈小,愈適合作為AMC訓練模型。
3.1 參數相關性分析
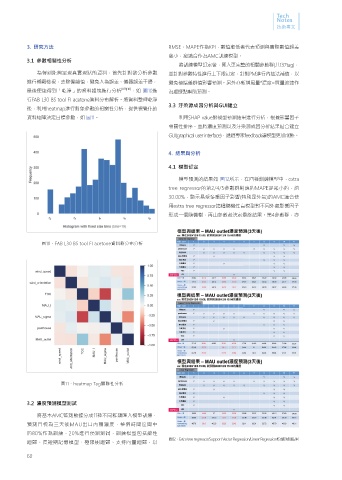
將訓練模型訂定後,匯入更完整的相關參數群(共137tag),
為得到能夠呈現真實現狀的資料,首先針對欲分析參數 並針對參數特性進行上下限訂定,針對PM進行內插法補值,以
進行概觀檢視,去除偏離值,避免人為誤差、儀器誤差干擾, 避免極端離群值影響預測。另外亦新增風量*濃度=質量流速作
最後便能得到「乾淨」的資料組塊進行分析 [09][10] ,如 圖10進 為虛擬點幫助預測。
行FAB L30 BS tool FI acetone資料分布解析。將資料整理乾淨
3.3 汙染源成因分析與GUI建立
後,利用heatmap進行對象參數的相關性分析,提供視覺化的
資料矩陣決定目標參數,如 圖11。 利用SHAP value對模型預測結果進行分析,根據影響因子
相關性排序。並將濃度預測以及汙染源成因分析結果結合建立
GUI(graphical user interface),透過專家feedback讓模型更加成熟。
4. 結果與分析
4.1 模型訂定
模型預測的結果如 圖12所示,在四種訓練模型中,extra
tree regressor的第2/4/5參數群對應的MAPE是最小的,約
30.00%,顯示易受多重因子影響(特別是外氣)的AMC適合使
用extra tree regressor這種隨機性高模型對不同外氣影響因子
形成一個隨機樹,再由多數者決定最終結果。第4參數群,亦
圖10、FAB L30 BS tool FI acetone資料群分布分析
圖11、heatmap Tag關聯性分析
3.2 濃度預測模型測試
將基本AMC監測數據分成11種不同群類匯入模型訓練,
預測目標為三天後MAU出口丙酮濃度,整個時間區間中
的80%作為訓練,20%進行預測測試,訓練模型包括線性
圖12、Extra tree regressor/Support Vector Regression/Linear Regression模型預測結果
迴歸、長短期記憶模型、極限樹迴歸、支持向量迴歸,以
60