
Page 61 - Vol.47
P. 61
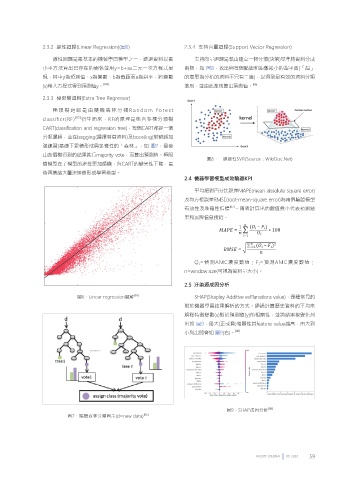
2.3.2 線性迴歸(Linear Regression)(圖6) 2.3.4 支持向量迴歸(Support Vector Regression)
線性回歸是最基本的機械學習模型之一,透過資料以最 支持向量迴歸是藉由建立一個分類(決策)基準將資料分成
小平方法算出已存在的關係並用y=b+ax二元一次方程式呈 兩類,如 圖8,找出與每個點總和距離最小的超平面(「超」
現,其中y為預測值、x為變數、b為截距而a為斜率,將變數 的意思為分析的資料不只有二維),以得到最有效的資料分類
(x)帶入方程式得到預測值y。 [04] 準則,並由此準則算出預測值。 [06]
2.3.3 極限樹迴歸(Extra Tree Regressor)
極限樹迴歸是由隨機森林分類Rand o m fo r e st
classifier(RF) [05] 衍生而來,RF的原理是集合多棵分類樹
CART(classification and regression tree),每個CART都是一個
分類邏輯,並在bagging(選擇特徵資料)及boosting(對錯誤加
強練習)基礎下累積形成具多樣性的「森林」,如 圖7,最後
由各個樹得到的結果進行majority vote,而算出預測值。極限
圖8、一維線性SVR(Source:WikiDoc.Net)
樹模型在子模型的選擇更加隨機,各CART的變異性下降,最
後再集結大量決策樹形成學習模型。
2.4 機器學習模型成效驗證KPI
平均絕對百分比誤差MAPE(mean absolute square error)
及均方根誤差RMSE(root-mean-square error)為兩個驗證模型
有效性及準確性指標 。兩者計算出的數值愈小代表預測結
[07]
果和實際值愈接近。
Q i =偵測AMC濃度數值;F i =預測AMC濃度數值;
n=window size(可視為資料量大小)。
2.5 汙染源成因分析
圖6、Linear regression圖解 [03] SHAP(Shapley Additive exPlanations value),是種常見的
對於機器學習結果解析的方式。通過計算歷史資料的平均來
解釋特徵變數(x)對於預測值(y)的相關性,並將結果視覺化列
出如 圖9,最大(正或負)相關性其feature value越高,由大到
小列出即會如 圖9(右)。 [08]
圖9、SHAP成因分析 [08]
圖7、隨機森林分類圖示(d=new data) [05]
FACILITY JOURNAL 09 2022 59