
Page 9 - Vol.45
P. 9
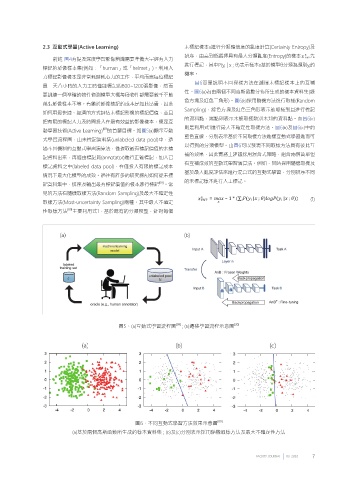
2.3 互動式學習(Active Learning) 未標記樣本x進行分類確信度的亂度計算(Certainty Entropy)及
排序,由高到低選擇具有最大分類亂度(Entropy)的樣本 先
前述 圖4有提及深度學習影像辨識需要準備大量經有人力
進行標記,其中P(y i | x ; θ)表示樣本x基於模型θ分類為類別y i 的
標記的影像樣本集(例如 : 「human」或「helmet」)。利用人
機率。
力標記影像樣本是非常耗時耗心力的工作,平均而言每位標記
圖6簡單說明不同採樣方法在選擇未標記樣本上的互補
員一天八小時的人力工時僅能標記約800~1200張影像,然而
性。圖6⒜為由兩個不同高斯函數分佈所生成的樣本資料集(綠
要訓練一個準確的物件偵測模型大概每種物件都需要數千至數
色方塊及紅色三角形)。圖6⒝採用隨機方法進行取樣(Random
萬張影像樣本不等。有鑑於影像標記的成本是如此昂貴,因此
Sampling),綠色方塊及紅色三角形表示被取樣到且進行標記
如何用最快速、經濟的方式評估未標記影像的標記價值,並且
的資料點,黑點則表示未被取樣類別未知的資料點。而圖6⒞
把有限的標記人力及時間投入在最有效益的影像樣本,便是互
則是利用式1進行最大不確定性取樣方法。圖6⒝及圖6⒞中的
[09]
動學習技術(Active Learning) 的首要目標。如圖5⒜顯示互動
藍色直線,分別表示基於不同取樣方法進樣互動式學習進而可
式學習流程圖,由未標記資料集(unlabeled data pool)中,透
以得到的分類模型。由圖6可以發現不同取樣方法具有彼此互
過不同機制的互動式學習演算法,僅提取最有標記價值的未標
補的效果,因此實務上建議採用混合式策略,組合兩個簡單但
記資料出來,再經由標記員(annotator)進行正確標記,加入已
有互補成效的互動式學習演算法。例如,同時採用隨機取樣及
標記資料之中(labeled data pool),在僅投入有限的標記成本
基於最大亂度評估來進行混合式的互動式學習,分別排序不同
情況下最大化模型的成效。過往有許多的研究探討如何從未標
的未標記樣本進行人工標記。
[09]
記資料集中,排序及輸出最有標記價值的樣本進行標記 。常
見的方法有隨機取樣方法(Random Sampling)及最大不確定性
(1)
取樣方法(Most-uncertainty Sampling)兩種。其中最大不確定
[09]
性取樣方法 主要利用式1,基於既有的分類模型,針對每個
圖5、⒜互動式學習流程圖 [09] ; ⒝遷移學習流程示意圖 [20]
圖6、不同互動式學習方法效果示意圖 [09]
⒜基於兩個高斯函數所生成的樣本資料集 ; ⒝及⒞分別表示採用隨機取樣方法及最大不確定性方法
FACILITY JOURNAL 03 2022 7