摘要
廠務系統穩定運轉–可靠度管理
Keywords / Realtime Monitor2,Operation Stability,(N+1)Backup,Hot Standby,Cold Standby

前言
廠務系統原始的設計為符合穩定運轉之需求,因此在規劃之初便有備援運轉機制,然而以往均由工程師於每一周透過Excel運算各個系統運轉的負載與設計容量進行手動比對,因而得出目前負載量與系統容量之間關聯而判斷系統是否可以符合正常的備援機制,然則,在設備運轉的過程中卻無法即時得知目前設備的狀態,因此也就無法即時得知整體系統的運轉容量是否可以符合負載量的備援運轉需求。
為了能達到即時備援運轉監視需求,因此可靠度管理因應而產生,透過原本操作系統與即時資料庫系統運作,因此系統的運轉數值,運轉狀態等均可以透過個別技術取得;而系統整體架構則需要透過系統工程師提供的邏輯來分析架構;因此系統設計需要整合即時資訊系統與邏輯架構的討論來規劃需要的資訊,並且除了即時資訊外,其他諸如設計容量等固定參數也必須納入考量,再經過監控工程師的整合規劃與程式及系統設計;整體系統便因此而運作並提供了即時資訊,改善了原本可能發生的風險;在「 開門十件事」這個系統中的一個重要主題便是可靠度管理 ;而可靠度管理針對備援狀態及設備狀態分別管理;因此不管是整體系統或是單一設備都得到即時控管;這也提供管理者針對那些無法符合備援機制的系統做特別的管控,並事先規劃方案,以避免系統問題導致的穩定供應問題。
針對穩定運轉,除了需要分析資料取得的方式外,同時也需要針對系統架構進行邏輯分析,並透過能即時運行的資料系統進行處理,因此,來自於系統知識、運行邏輯 、資料流整合、資料結構與分析、程式設計、警報處理及例外處理等,均需要透過各個不同層面的人員提供資訊,以系統知識與運行邏輯而言,必須要由負責系統的系統工程師提供系統架構,並探討系統在何種狀況底下符合(N+1)機制,需要判斷的訊號與如何整合這些訊號並設計出適合的邏輯架構來處理,以符合各個系統的運行與處理模式。最後則需要與廠務開門十件事系統整合,以提供更多的應用來讓廠務運行更順暢、供應更穩定。
由於廠務系統眾多,因此需要分別與電力、機械、水處理、氣體供應、化學品供應等各類型系統工程師討論、並分析以取得系統邏輯與運行模式。
而針對資料流部分,以往的資料節取模式,往往讓廠務最重要的資料庫系統InSQL處於高運行負載的狀態,因此透過InSQL的架構內容研究,取得最佳的運行模式,而不依循傳統的取值方式,因此而降低了InSQL運行的負載 ,提供運作效能,同時也可以達到資料即時擷取的目的 ; 因此資料流如何整合InSQL與MS-SQL就是一個重要的課題 ; 而在資料結構方面,如何設計一套符合需求的架構,以讓系統能運行順暢,也是一項重大課題,因此MS-SQL運行過程中如何取得最佳的運轉模式就需要針對MS-SQL最佳化進行分析設計 ; 這部分需要取得InSQL相關資料及MS- SQL設計原理,以使用資料庫模式最佳化的狀態下產生出類似於SCADA提供即時資訊的運行模式,但卻不會因此而拖垮原系統,而新架構的系統也因此而能正常運作。
最後的程式設計與介面設計及警報通知,則需要了解廠務系統常用的Stored Procedure、ASP與ASP.Net技術來分析設計,一個統一而簡單的程式設計模式是極為重要的 ,當使用的技術越多越複雜,則整個系統的介面越多,也越複雜,資料交換的機制也越麻煩,同時也會引發更多的問題,這也就是我們設計這個系統的原始理念,簡化系統 、簡化設計、簡化運行以取得即時資訊,統一的架構讓系統在各個不同的廠區均可經過小調整即可適用,這是整個系統的核心信念。
最後運用於「廠務開門十件事」系統則需要再透過介面溝通的方式,來降低對原系統的衝擊同時有能整合到新的系統介面上,讓整體的系統運作更為順暢。
文獻探討
依據文獻說明[1],可靠度是有時間上的考量,在設定使用環境與時間空間的條件限制下,系統能達到所要求的功能標準,並且提供備援服務,因此在產業中可靠度工程是一種應用技術,也就是設計的初期要整合不同資訊,這些本質資訊必須被設計進去系統內,而系統內的每個元件都有使用週期或是壽命,因此為求得系統正常運轉在備援系統下,則必須要探討可靠度的影響參數,並且這些理論也廣泛應用於高科技業、機械產業、醫療產業,材料工程及各類工程應用。
產業使用可靠度分析來提升品質的手法應用很多例如偉博分析(Weibull Analysis)、失效模式分析(Failure Mode & Effect Analysis, FMEA)、失效樹(Fault Tree)等。而應用於廠務系統常用的手法就是FMEA,這個手法應用於廠務各個失效的狀態下,而本系統透過即時分析可以即時取得系統可靠度資訊,未來也可能整合各項資訊透過大數據分析或許有機會探討系統可能失效的預測,這些可透過大數據理論分析來實現。而現階段我們則是透過系統的即時監測來分析系統狀態,並且整合邏輯理論與探討並且整合系統即時資訊可由系統的運作來達到即時監控可靠度的功能 ,而當系統失效是則可記錄每次的分析資訊提供系統工程師分析故障原因,因此資料的收集變成為系統擴展一項重要的工程,並且據以整合公司現行的FMEA系統整合分析系統未來可能的變因在系統發生變故時提早預警或提醒,避免了重大災難的發生。
系統可靠度的分析方法可以採用定性評估法與定量評估法,然而要應用這些手法則是需要透過資料足量的收集 ,以下舉兩個例子來說明即時可靠度系統能提供的好處。
系統備援的概念大量運用於IT資訊產業的資訊管理,在目前大量資訊化下,系統運作大量依賴資訊系統資料提供或是指令與操作。因此,資訊系統的備援在現代的系統運作相對重要,也因此發展出各類型的備援機制,例如熱備援、冷備援、異地備援等。備援機制嚴重影響系統運作的例子層出不窮,以下的利字說明了正確備援與即時備援資訊的重要性。
2009年時[7],桃園機場的移民署境管系統當機事件讓系統的備援機制討論再次浮上檯面,因為系統當機讓整個系統花了三天的時間才復原,也因此造成重大影響;該系用儲存設備採用了磁碟陣列(RAID)技術,再加上備援系統 ,也就雙重備援系統設計,但仍發生問題,根據後續的問題探討,由於三個硬碟已經失效因此造成這個嚴重的問題 ,這並非一個特例;2007年,國際太空站也曾經發生一個具備三重備援(triple redundant)的電腦系統因其中一個電源供應器設計錯誤及後續處理人員操作錯誤,而導致其環境控制電腦系統停擺;因此可以知道除了良好的備援設計外,即時監控備援機制與人員的操作訓練也是非常重要。
由以上兩個例子來探討,系統雖然運轉在備援模式底下,但系統設備已經故障了,也就是系統已經失去備援能力,但是卻沒能即時知道也沒人處理,因此系統功能在第一階段喪失時,仍能正常運作,但第二個問題發生時,則已經失去運作的能力,也因此造成系統當機而引發了不可收拾的後果;這也就是我們所探討的,系統雖然設計在備援模式,但卻沒有正常的監視機制針對系統中的設備進行監視,當系統失去備援能力時也無法知曉,則後續發生問題時所造成的影響就是巨大的。另一個例子則說明了系統設計之初便需要重複檢視,避免不良的設計而影響到整體系統的備援功能;當然額外的問題就是操作人員的學識與訓練不足而導致的問題,一個問題的發生就是因為雙重錯誤下所導致的,因此如何讓備援系統能有效運作就依據這個方向來處理。
首先針對系統設計的問題,這個在於設計之初就必須由新工設計人員與廠務運轉人員針對設計的細節多方探討來避免因設計而導致的問題;這在台積的制度下一向被執行得很好,因為台積有優秀的設計人員也有很好的運轉工程師,兩者相互討論下,避免了因為設計不良而導致的問題;另一個操作人員訓練的問題,目前台積有規劃優秀的廠務學院,透過廠務學院的學習,並由資深人員的帶領及多次的緊急應變訓練,讓操作人員無論學識與緊急應變處置的能力都大幅提升;因此,最後一個問題就是即時狀態 ,這也就是這個系統要解決的問題,透過可靠度系統的設計,即時監視是否符合備援機制同時也提供設備是否處於不可用的狀態下,由操作人員即時監控,避免多重錯誤而導致了系統問題。
研究方法
可靠度管理係以發生狀況前能預先測知系統將處於失效狀態,這就是FMEA的應用,在台積我們有完善的FMEA系統來協助系統人員分析各項失效模式,因此透過這些失效模式分析與管理將以往發生的問題匯總並且提供設計人員在設計系統時的參考依據,以設計更為強健的系統避免任何元件的錯誤或人為MO而導致系統停機影響生產,歷史的資訊透過FMEA可提供設計者一個良好的設計參考,然而系統上線運轉時,系統的可靠度則是發生問題時才會又回到FMEA的模式探討,或有其他系統的問題透過FMEA的分析用以改善系統而達到更加強健的系統運作,然而即時的可靠度系統應由額外的設計來達到管理的目標,因此 ,以原本的設計邏輯為基礎而探討出即時監控的模型,讓系統即時運轉資訊回傳後透過良善系統的設計,以即時資訊訊分析產生必要的警告機制,如此來控管系統失效前即可妥善處理,避免災難性的狀況發生。
可靠度管理係用以監視目前系統使用比例的狀態,因此設計上除了取得即時用量資料,同時也必須要將原始設計的容量當作系統參數納入運算,以正確判斷系統是否運轉在熱備援狀態。因此,透過即時狀態取得目前系統運轉套數,再將套數乘上系統系統設計容量,這就是系統目前可供應的容量,而透過取得實際運轉負載總和就可以知道目前系統運轉需求,這個需求可以是直接取得的數值和、或是透過系統邏輯運算取得的負載值;同時透過即時資料的狀態可以判斷目前系統是否處於正常運轉狀態、正常冷備援狀態、停機狀態或是不可用狀態;因此計算系統可靠度變依據這些資料處理來運算;狀態運算會假設系統運轉在熱備援模式,因此當系統內一套設備故障時,系統仍可正常供應,也就是系統當下運轉時為(N+1)模式,而一套設備故障時則變成N模式,因此依據邏輯而運算出(N+1)及N時的扛載率就知道系統是否運轉於熱備援,也就(N+1)及N運轉時的扛載率軍必須要小於100%,這樣的狀態下就符合 (N+1)運轉模式;而(N+1)扛載率小於100%,但失去一台設備時運轉的N模式卻大於100%時,則必須要確認目前停機的設備是否可以自動啟動加入扛載,避免系統無法負擔失去一套設備時正常運轉;若有設備可以自動啟用加入扛載則稱為冷備援(Cold Standby),在這個狀態下,系統會以黃燈(Level-1)警示;若無備援設備或備援設備無法自動加入扛載,則這個狀態就不符合備援模式,系統會以紅燈(Level-3)警報。
可靠度管理採用即時資料取得方式處理邏輯判斷,對於廠務現用的系統中以採用InSQL為最佳來源,因InSQL為工業級的資料庫系統,因此可以快速取得現場資料,並且判斷取得資料的品質,因此不用再另行開發資料擷取系統 ,而取得資料之後,則透過系統工程師與監控工程師討論系統邏輯以期開發出合乎系統要求的資訊系統,這些系統可以即時判斷並且發出警報 ; 因此以下針對這些技術進行探討。
3.1.InSQL 資料擷取技術
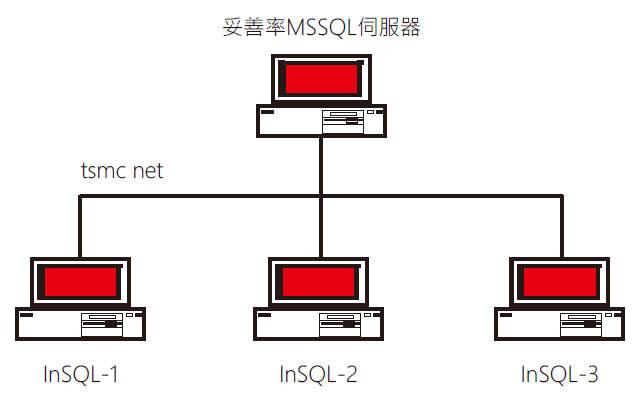
為了達到「即時」這個目的,因此針對InSQL的研究[2][3][4]是必要的,利用下圖來說明資料庫擷取模式 ; 廠務現場資料是由各類型的Sensor偵測各種物理量或是狀態,這些物理量透過傳感器轉換為電氣訊號並傳送到控制器,因此資料流由最下層的控制器收集開始,往上透過資料擷取介面,也就是一般所說的驅動軟體將資料從控制器轉出,透過InSQL資料擷取程式IDAS取得相關的資料 ; 在IDAS之後則是InSQL內部運作 ; InSQL基本上係用於儲存現場資料的資料庫系統,但有別於一般的商業用系統如Oracle, MSSQL等,資料的儲存係透過檔案方式儲存,因此其資料並非一般商用資料庫格式,而是以壓縮檔案的格式存在,並且每日產生一個目錄儲存當日資訊 ; 這也就是我們查詢Trend Chart使用的History資料表,這些資料的查詢也是透過InSQL所提供的特殊介面Stored Procedure與View來達成。這就是→圖1右側的History路徑。
圖1、InSQL即時資料庫擷取模式
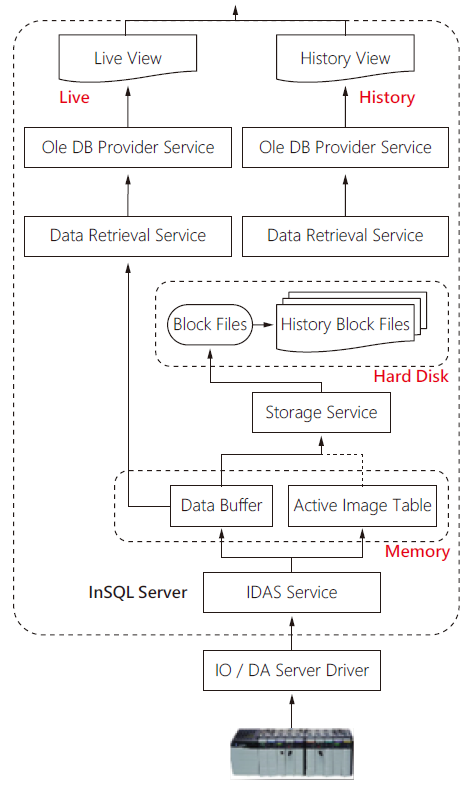
因此,以往我們針對InSQL的應用都是透過取得His -tory資料表的方式,但必須要了解的是InSQL的資料係以檔案的模式存在於硬碟空間內,因此檔案的存取雖然透過SQL介面,但仍是使用硬碟中的檔案資料,硬碟存取的問題在於機械性的動作,且因資料量龐大,因此速度上相對緩慢同時因資料量龐大,縱使InSQL有極佳的Index索引技術,但仍需要消耗大量的系統資訊,包含CPU運算時間、記憶體存取空間、硬碟運行時間,也因此而造成系統大量的負載,當運行量越大時,則系統的負載量越大,因此對於即時運行來說是一項需要很大資源的工作,甚至於可能讓系統整個過載而影響資料收集功能,這樣的情況是不能接受的,因此,對於需要即時運算的可靠度系統而言,這樣的處理模式是無法運用的。在討論了InSQL運行模式之後,我們發現了另一個資料儲區,這個資料儲區儲存了InSQL的即時資料,同時資料儲存於記憶體中,但資料僅限於即時值 ; 相對於History,這個資料儲區的取得方式使用了Live這個檢視功能,因此,我們透過取得這個檢視功能就可以即時取得InSQL內的即時資料,同時,這個檢視的內容存在於記憶體內,因此不需要存取硬碟,速度上非常快,因此消耗的電腦資訊少,因此應用在即時系統是可行的。
3.2.即時資料轉換
由於可靠度系統運行於不同的Server,因此,在取得資料的模式又是另外一個需要探討的技術 ; 如上一節所討論的,InSQL資料並不是儲存於MSSQL資料庫內,但架構卻是由MSSQL所建構起來的,因此,InSQL提供了完整的MSSQL存取介面與模式,讓使用者可以透過簡單的SQL語法即可取得需要的資料,這個部分必須要討論的是資料如何擷取→圖2。
圖2、可靠度伺服器與InSQL即時資料擷取模式
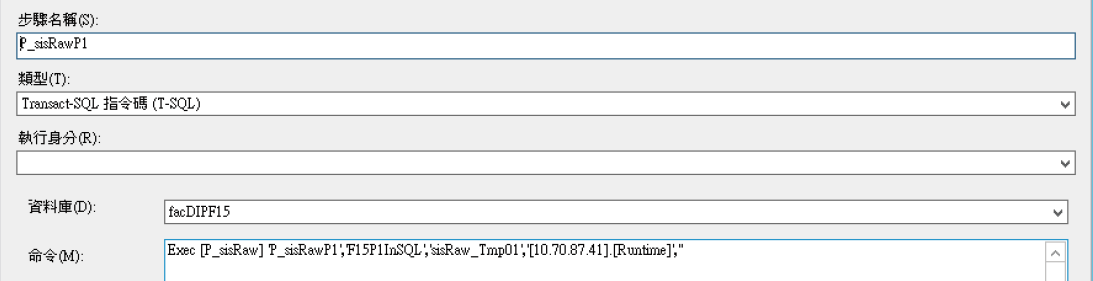
由於廠務的InSQL並不會只有一台,以各個廠區的廠務系統為例,至少都存在有兩套甚至更多的InSQL分別儲存不同廠別的資訊,因此在可靠度運算時使用到的資料可能來自不同的InSQL,同時可靠度伺服器位於MITD的VM架構內,因此良好的資料交換方式是很重要的,因為系統必須要在很短的時間內取的InSQL內的資料,並儲存到應用的MSSQL內,而這個系統的資料擷取模式都是類似的,僅只於資料庫的來源不同,因此如何設計一個共通的擷取介面是很重要的,如→圖3中說明了這個資料擷取的模式,透過這個方式,將來源InSQL所有資料儲存到一個設定好的暫存資料表,接著再處理這個資料表內的資料內容,最後將資料內容更新到應用資料表中,完成整個資料擷取的程序。如→圖4則是我們設定這個擷取程序的作業,經由設定參數則系統每分鐘從不同的InSQL取得全部的資料,這也就達成了即時資料擷取的目標。透過這個方式,每個廠區得所有InSQL資料即可全部彙總在Facility DIP資料表內,因此不同InSQL的資料整合再一起,也就可以整合運用。
圖3、即時資料轉換程式

圖4、作業代理程序
3.3.資料架構設計
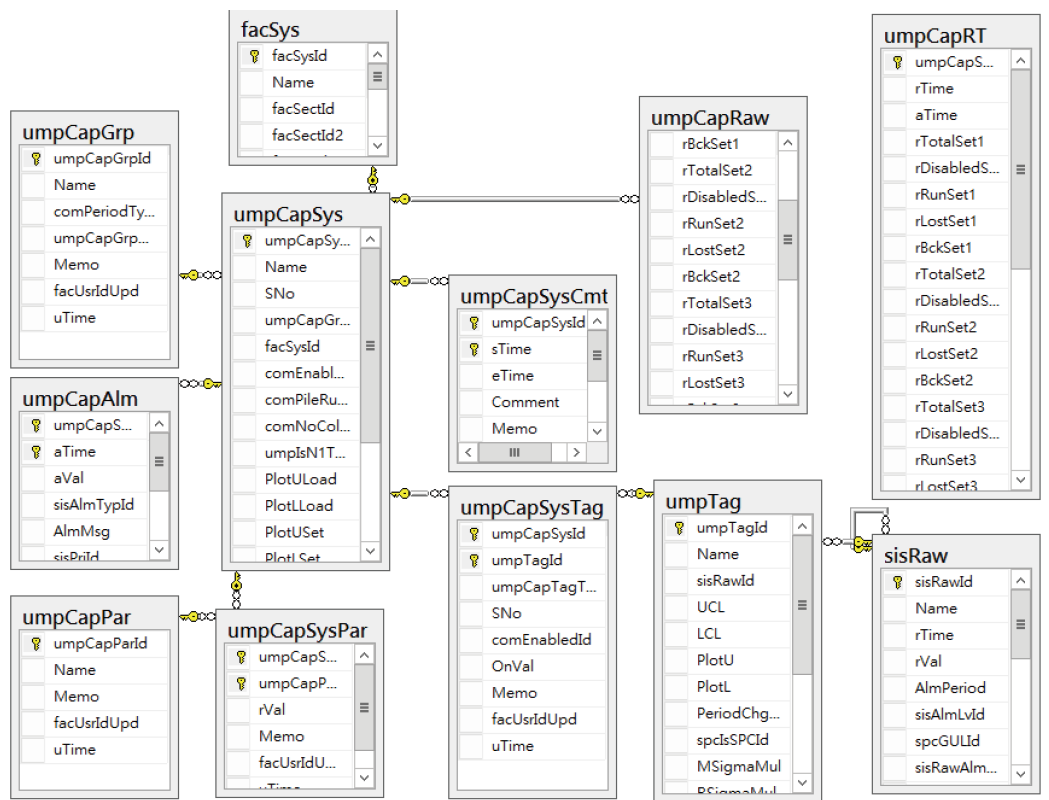
系統的開發過程,建構一個符合需求的系統架構是極其重要的,利用MSSQL資料圖表功能可以很容易檢視整個資料架構的全貌,同時也可建構資料間的關聯性,在此之前的討論,我們說明架構內的資料來源處理技術(sisRaw),這是系統的核心之一,因為沒有資料,就沒有系統 ; 而一開始討論的系統邏輯則是由umpCapGrp來區分,每個系統則是定義於umpCapSys資料內,因此針對每個系統會設定一個umpCapGrp,也就是一個特定的邏輯 ; 每個系統則有相關的Tag,這透過umpCapSysTag設定完成,但來源Tag設定於umpTag,並透過對應的sisRaw取得運算資料;每個系統則有特定的參數,例如設計量就設定於umpCap SysPar資料表內,這些資料設定完成後,即時運算資料則儲存於umpCapRT內,這樣就構成了整個運算系統 ; 當運算過程發生了Alarm,則Alarm資料會記錄到umpCapAlm內,提供之後查詢,而發生Alarm的時間內,每分鐘的運算資料會記錄到umpCapRaw內,已取得運算過程的結果 ,但正常狀況下則不儲存,避免資料量過大。這也就提供了使用者在設定時的資料設定步驟→圖5。
圖5、系統可靠度系統架構圖
3.4.邏輯分析與討論
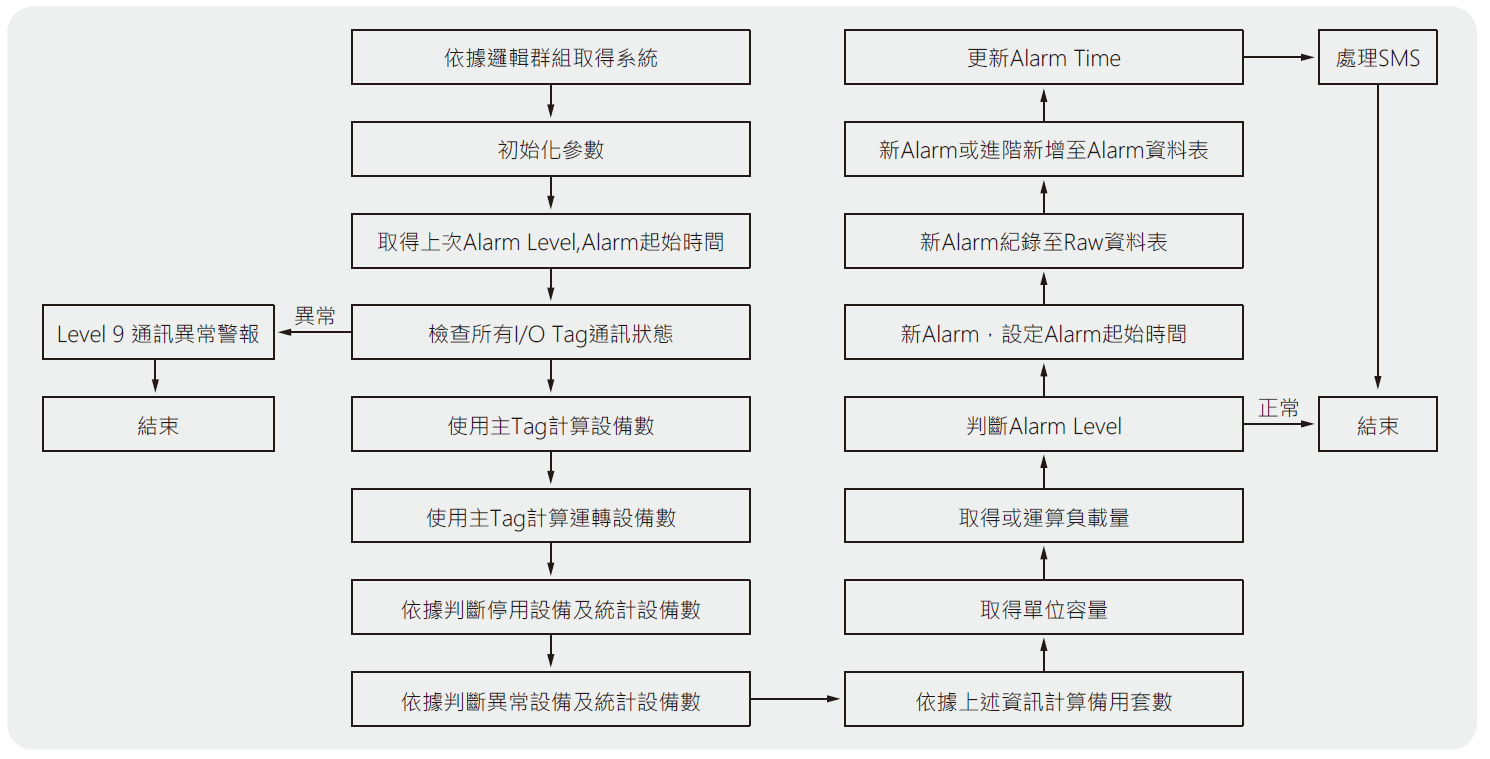
整個系統內最重要的當然是處理邏輯,針對不同的系統就有不同的處理邏輯,因此對於系統運行模式的了解是非常重要的,這個部分就需要系統工程師提供專業的說明與分析,並且經過討論以設定符合可靠度系統所需要的資料。→圖6中顯示了通用的邏輯圖,詳細的部分則會依據各個不同的系統而有所差異。
圖6、系統可靠度通用流程圖
以下以PCW運算邏輯為例子→圖7,當運轉電流值大於100A時代表系統在運轉狀態,也就是正常模式,而Fail模式則有兩個判斷模式,包含運轉電流小於100A,或是風車狀態與設定值不同,這說明了PCW的所有設備必須開機,否則判斷設備為Fail,再依據負載Tag取得目前的需求量,再透過運轉台數及單台設計量計算目前運轉的可供量,最後計算是否符合(N+1)運轉模式。
圖7、PCW系統可靠度流程圖

這個系統原本使用VFD Hz當作運轉的依據,但系統工程師認為電流值是個比較適合的判斷依據,因此改為電流當作判斷依據 ; 因此依據系統工程師的判斷進行修改與調整,這也就是如何讓系統更符合邏輯是需要經過分析與討論,因此系統工程師的專業是非常重要的。
因此在→圖8中以一個廠區為例,系統中有兩個負載Tag,兩套設備每個使用三個Tag來進行判斷。
圖8、PCW系統可靠度對應Tag設定

3.5.系統設計與開發
經過以上的步驟與討論,整個系統內最重要的部分都已經齊備,最後以廠務熟悉的程式設計模式進行設計,廠務系統大部分採用Windows,MSSQL,ASP.Net架構開發系統[6],因此,這套系統我們依循著開發,為了達到效益 ,主程式放置在MSSQL[5]裡使用Stored Procedure開發,因為是MSSQL內嵌程式因此應用MSSQL的性能會更好,透過 Task的安排,讓系統可以每分鐘更新一次,達到類即時的目的 ; 而介面方面則採用ASP/ASP.Net開發,這個平台普遍用於廠務大部分系統,可簡化維護的工作,並且降低開發與維護成本。→圖9中展示了判斷Fault的程式片段。這個系統透過序號管理各個不同類型的Tag,讓系統設計更簡單些。
圖9、MSSQL Stored Procedure邏輯處理的片段

3.6.失效驗證
在程式的展現上,當系統上有符合邏輯的問題發生了 ,系統即可及時發出警報,並且可透過簡訊系統發送相關人員即時到設備處進行確認,這個機制目前發展為交接時的確認模式,主要原因係搭配系統原來的即時監控機制,值班人員於系統設備現場確認,系統工程師人員則於可靠度系統測確認目前系統可靠度狀態來決定事件處理的先後次序。例如當AAS系統發生風車跳機時,我們知道SCADA系統會即時發送警報與簡訊,此時系統值班人員應即時到現場確認狀況,而系統工程師則可至可靠度系統確認系統熱備載狀態,如此的運作方式可有效確認系統縱使失去一台扛載仍可正常運作,並確認是否該將其擺在第一位處理以避免熱備援失效而導致的問題。
結果與分析
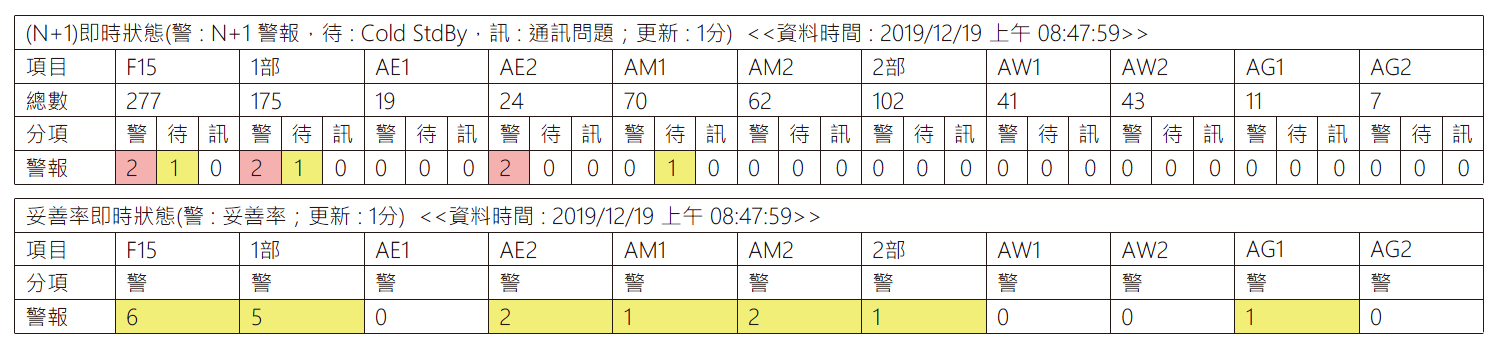
資訊如何顯示是一項重大工作,透過不同角度顯示使用者所需的資訊是結果輸出的重要方向,在原本的DIP系統中使用了Dashboard的概念,依據系統每分鐘更新的狀態顯示在介面上,廠區可以一目了然了解到整個廠區系統可可度的狀態,→圖10顯示了這樣的一個結果 ; 這兩個Dashboard分別顯示不符合(N+1)運轉模式及設備目前不可得的狀態,第一個Dashboard告知使用者目前系統未符合(N+1)因此有一定的風險存在;第二個Dashboard則是提醒使用者目前系統中有設備不可使用,但該系統可能符合或不符合(N+1)狀態;以不同的面向提醒使用者依據不同角度關心所屬系統。
圖10、系統可靠度 Dashboard
透過資料交換整合,資訊很容易就可以整合到開門十件事平台,如→圖11所示,經由這個平台,依據各個管理層級而顯示資料,提供使用者以不同面向看到所屬系統的狀態,管理的工作也就更為簡化了,管理者可以容易知道整個面向;系統工程師也可以知道詳細的資訊狀態,依據重點處理。
圖11、開門十件事資訊整合介面

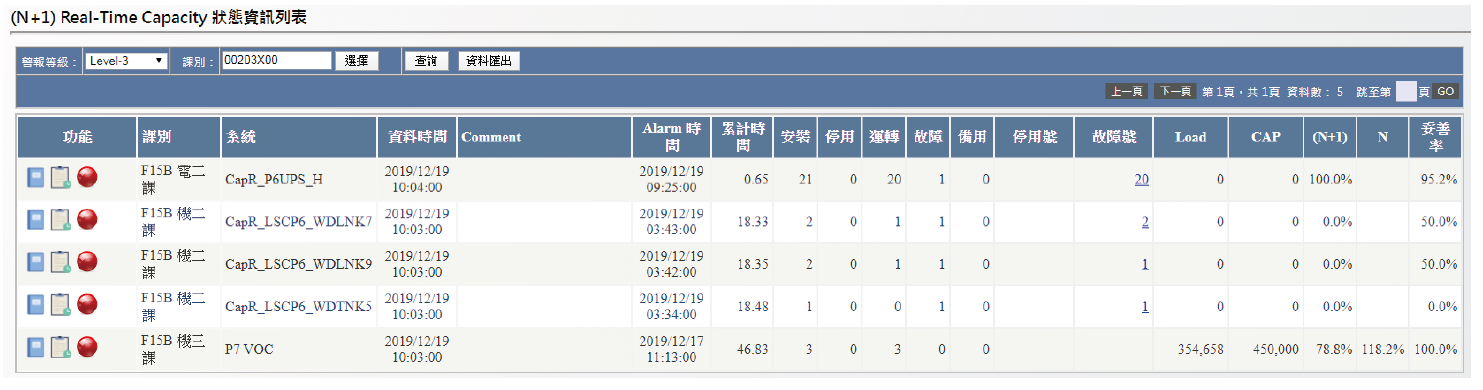
依據顯示的數值,使用者可以簡單點選以檢視對應的詳細資訊,這些資訊透過一個表格展現,依據分類、分單位顯示,因此在不同的管理層級可以檢視所屬資訊,以符合各個層級的需求 ; →圖12顯示了Level-3等級Alarm詳細列表,而依據序號管理,可以再詳細查詢每個目前狀態不符的Tag也就是設備所屬的Tag,如此方能完全掌握系統-設備-Tag狀態,讓值班人員能關注那些有問題的設備Tag。
圖12、檢視詳細結果
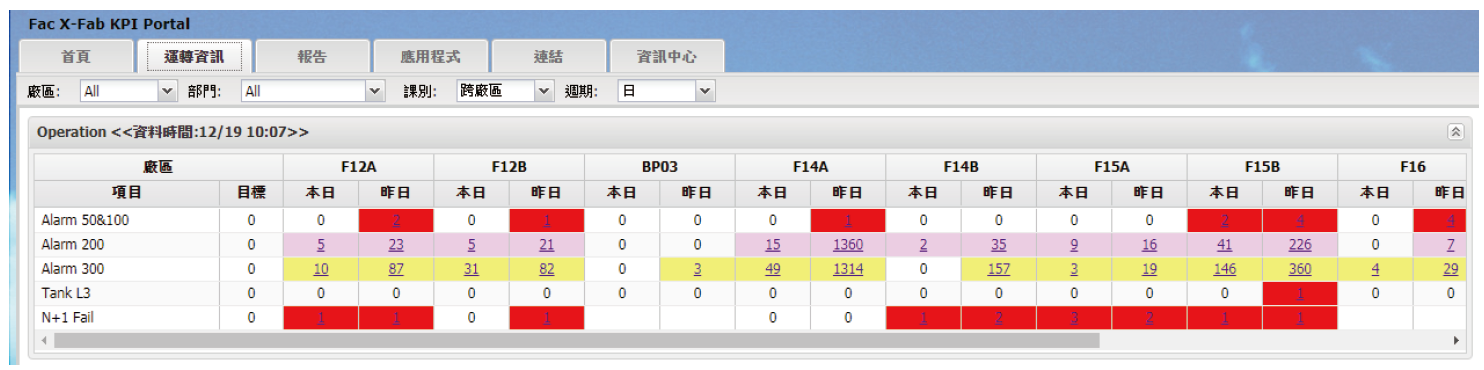
而OneFAC平台更提供了跨廠區的檢視,不同廠區間可透過查看彼此間的資訊而互相可交換資訊,交互學習,這樣就是大廠務的目標,因此,資訊透明、分享、交換就是一項重要的課題,也因此讓彼此有更多學習與進步的空間。→圖13顯示了OneFAC跨廠區資訊,因此無論哪個廠區的資訊都可以隨時取得。
圖13、OneFAC上的跨組織檢視
結論 Conclusion
系統可靠度區分為(N+1)備援機制與設備妥善率兩個面向,分別依據系統運行是否符合備援機制及設備是否在可用狀態下;而這兩個需求中的第一個項目透過與系統工程師詳細的討論與分析而有產出適用的邏輯;然後再依據需求增加需要的Tag進入InSQL,透過系統與FMCS合作完成整個系統需求,也因此讓系統工程師了解系統在監控中如何運用,也讓FMCS人員了解各個系統運行的關鍵;因此能更加深入各個系統。
系統可靠度透過DIP邏輯架構設計完成,再透過One FAC平台跨廠區資訊分享,讓所有廠務人員可以檢視到各個廠區資訊,再透過開門十件事平台整合並提供燈號提示資訊,因此更加簡化了系統管理方式,也同時提高使用度 ,讓各個層級的人員可以依據本身的需求管理系統、監視系統而達到廠務系統穩定供應的目的;因此層層分享的資訊是最佳的管理。
未來的發展方向應該可與FMEA系統分享資訊,並可以將資訊適當收集作為AI大數據分析的參考,當作未來系統更進一步發展的空間,以期達到系統未發生問題或設備元件在發生故障前先行預測,如此可降低對系統的衝擊。
參考文獻
- 可靠度工程 Reliability Engineering, Quality Magazine. Chinese for Quality.Vol. 47 No.1,翁紹仁。
- Wonderware InSQL入門手冊,Wonderware,2005。
- Wonderware Historian Administration Guide,Wonderware , 2013.
- Wonderware Historian Client,Wonderware,2012.
- Microsoft SQL Server T-SQL大全–實務學習與問題解決,林班侯,2007。
- ASP.NET專題實務(I) : C# 入門實戰,周棟祥,2019。
- 工業安全概論系統安全分析,浦永仁。
留言(0)