摘要

從深度學習技術到MLOps : 以CCTV影像工安辨識談人工智慧的落地應用為例
Keywords / Construction Site Safety,Surveillance Video Analysis,Deep Learning2,Object Detection,Machine Learning5,Artificial Intelligence8,MLOps




According to recently survey reports of fatal occupational injuries, the major risks leading to fatal injuries in construction sites are falling from high places or getting hit by a dropping heavy item. To avoid human exposed to those risky situations, one of the traditional approaches is to set up surveillance system, and to hire surveillance operator monitoring CCTV video stream for 24hours x 7days a week. However, fatigue issue could lead surveillance operator losing their focus and may become unaware to response potential hazards on time. This paper adopts a deep-computer-vision based approach to detect each human on video frame and to check their locations as well as their personal protective equipment. By taking advantages of UI/UX design and AI model maintenance process, the resulted system can automatically analyzes the real-time CCTV video stream and prevents the potential hazards or safety protocol violation with very few human efforts.
1. 前言
工地環境向來是變遷快速、複雜多變且充滿風險的環境。也因此在各產業之中,營造及土木工程產業每年承擔巨額的職災損失。據美國勞工統計局(Bureau of Labor Statistics, BLS)最新的統計[1],工地現場員工(建築營造產業)是除了職業駕駛(運輸產業)統計受致命職業災害人數最多的職業,同時隨著經濟規模的成長,自2015-2019年,統計有案的受致命職業災害人數是年年增加。而據我國勞動部職業安全衛生署最新的勞動檢查統計年報[2]顯示,2019年我國因為重大職業災害死亡人數多達316人,營造業更是所有產業中重大職災死亡人數佔比最高者,計168人(達53%)。這兩份報告皆指出,「從高處墜落」及「物體飛落砸傷」是造成營造施工環境產生重大職災傷害的主要成因,避逸此類風險意外已成為打造安全營造施工環境最刻不容緩的重要任務。
目前在工地環境安全監控設備多仰賴CCTV或其他監視攝影機系統(Closed-Circuit Television, or Surveillance),安排值班人員長時間監看監視攝影機畫面,並即時通報所發現的高風險或災害發生情事。然而這種高度仰賴人員介入的操作機制,長期來看除了需投入的大量人力的操作,一旦人員的專注意力因疲勞而下降,遺漏通報或通報延遲的狀況恐難以避免。單純仰賴人力的作業機制也無法在擴大場域中有效規模化的執行,因此需要一自動化且智慧化的工地影像監控系統,協助值班監控人員從鉅量的影像中,快速過濾高度職災風險的畫面。
另一方面,隨著多媒體平台及IoT(Internet of Things)聯網裝置的普及,包含影像、聲音或是感測數據等資料型態,每日皆以鉅量之規模產出,提供豐富的人工智慧訓練資料。加上具快速平行化運算能力及高效存取頻寬的GPU裝置,其製造技術與成本皆不斷優化,即便是一般的研究學者或技術人員皆可輕易取得高效且經濟實惠的運算力。基於上述兩點加速深度學習類神經網路(Deep Learning Neural Network, or DNN)技術自2012年開始蓬勃發展[3]。深度學習類神經網路之所以具有超強的資料擬合及學習能力,即在於將傳統機器學習方法中對資料施以特徵工程及特徵選取(Feature Engineering and Feature Selection)過程[4],直接整合到層層疊加的類神經網路模型中,並透過損失函數的設計,創造端到端學習(End-to-End Learning)的模型優化機制,在訓練的過程中,學習算法便可自動為類神經網路模型,擬合出具有高度鑑別力的特徵向量。目前深度學習已被證明在越是純粹、低階的資料及訊號,例如 : 影像、聲音、感測數值及文字中取得高度的成功[3]。自2015年的ILSVRC國際圖像識別競賽開始,深度學習於影像識別應用的準確率,更是一舉突破了人類辨識能力的平均水準[5]。因此近年來透過深度學習影像分析技術,偵測攝影機畫面中之物件,例如 : 安全帽、安全反光背心、危險區域環境等,已被多所應用於工地安全監控維護的應用上[6][7][8]。
然而如同之前所述,有別於其他場域的影像識別應用環境多屬相對穩定、少有變化的環境。隨著工程進度的推展,工地環境樣貌變遷速度不只快,同時變化幅度劇烈,往往深度學習模型甫剛訓練完上線,就得面對影像辨識或物件偵測應用中的「前景物件」或「背景影像」已跟訓練資料集的分佈狀況,有大幅度變化的問題。這些都會使深度學習模型上線後的準確率及模型的有效期間大打折扣。過往所發表深度學習應用於工地影像安全偵測之論文,往往著重在影像辨識或物件辨識中對工地人員行為、穿戴裝備、車輛機具的辨識進行命題及實驗,卻少有談論因應工地環境快速變遷,如何以自動化、有效率的方式持續監督及改善模型效能下降的問題。
有鑑於此,對於深度學習影像識於工地安全強化的討論,我們將從單純模型建立的角度,向上提升至建立長期、穩定的服務流程。本篇論文提出MLOps的概念,規劃適合於工地工安監控人員長期操作的服務維運流程(Machine Learning as a Service, MLaaS)。MLOps意即將系統開發及維運(Development and Operations)的DevOps流程,透過機器學習裡的互動式學習(Active Learning)[9]及遷移學習(Transfer Learning)[10],實現機器學習模型在長期服務維運中的持續訓練(Continuous Training)與持續整合(Continuous Integration)效果。並透過合適的使用者操作介面與操作體驗設計(UI/UX design),實現工安偵測應用中對於PPE(Personal Protective Equipment)穿戴及高風險區域的侵入偵測,提出輔助監控人員的自動化辨識系統。有效降低「從高處墜落」及「物體飛落砸傷」等工地職災成因。
本文後續章節安排如下 : 第二章重點說明相關背景知識,包含深度學習模型中的卷積操作運算及深度物件偵測模型類型簡介,說明影像樣態識別及物件偵測的原理。同時亦會介紹互動式學習、遷移學習,以及MLOps等核心概念。第三章將介紹本篇論文針對PPE穿戴及高風險區域侵入偵測,所引用的深度學習模型設計方法、系統的UI/UX設計,以及針對MLaaS為目標所設計的MLOps流程。第四章我們來自工地現場所收集的CCTV系統影像進行準確率及效能評估實驗。第五章則對本篇論文的重要發現進行綜整並提出未來可持續強化的系統開發方向。
2. 文獻探討
2.1 深度卷積類神經網路及卷積運算(Convolution Neural Network & Convolution Operation)
受惠於近年高效能GPU運算裝置及鉅量資料的蓬勃發展,多樣且新穎的機器學習資料分析方法得以發展,並促成了目前大眾所認知的深度學習神經網路(Deep Learning Neural Network)架構。圖1⒜突顯了傳統機器學習方法及深度學習網路概念上的差異[11]。傳統的機器學習方法,在特徵擷取(feature extraction)上需要專家基於領域知識(domain knowledge)設計或是透過統計檢定選取特定指標,進行人工特徵的合成(hand-crafted feature engineering)。這樣分二階段的作法對於後續預測模型的建立,雖然可以提供快速的引導及收斂,然而以現有的專家知識出發,某方面來說也剔除了一些模型原本可探索的方向,以綜觀來看未必就能找到全域最佳解。另一方面,深度學習模型強調不仰賴專家產生的特徵值做為模型輸入,而是嚐試堆疊多層的神經元運算,串接前面淺層的神經元運算輸出,成為後面深層神經元運算的輸入。當堆疊超過一定的深度時,深度學習演算法為了擬合模型最後輸出的結果,使其與分類目標一致,各層神經元中的參數,自然就會演變為重要的特徵值,整個學習的過程實現了自動化的特徵工程機制(automated and learning-based feature engineering),這不只是大大克服了機器學習研究學者在跨足不同領域應用時缺少專家知識的困難,同時也讓人工智慧有了挖掘既有專家經驗以外新知識的機會,進一步提升了模型預測效能。
圖1、⒜傳統機器學習及深度學習方法比較示意圖[20] ; ⒝利用多層次卷積運算,漸次掌握人臉偵測之重要圖像特徵[23]
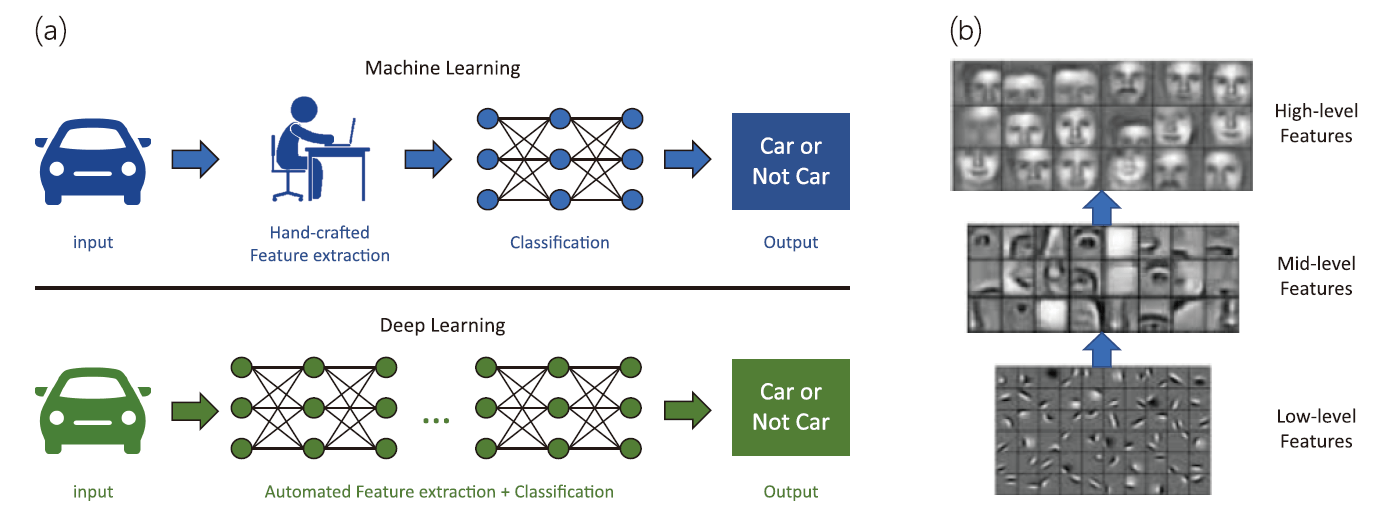
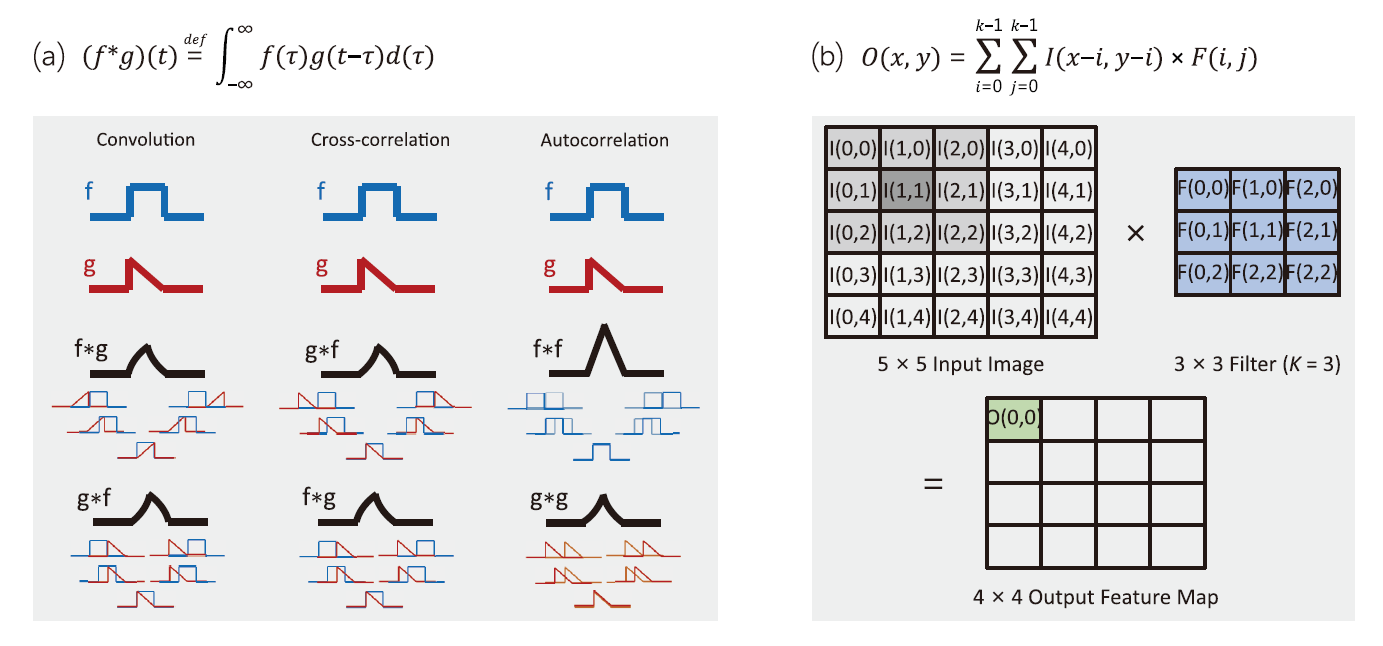
在所有近年來發展的深度學習類神經網路運算型態中,最知名也是影響最深遠的莫過於卷積運算(Convolution Operation),而大量採用卷積運算的深度學習網路則稱為深度卷積類神經網路(Deep Convolution Neural Network, DCNN)。圖2⒜及⒝分別示意卷積運算在一維序列及二維影像陣列上的運算方式[12]。不論是 圖2⒜及⒝兩種中的哪一種,讀者可以發現卷積運算的操作類似於傳統向量內積運算,先將兩段資料的分量元素相乘,再取各分量相乘後的積進行相加做為最後的輸出。與內積運算的效果相同,卷積運算非常適合用來量化兩向量間的相似性及相關性(similarity and correlation)。不論是在一維的時序性資料分析或是二維的圖像識別應用上,卷積運算中的卷積核(convolution kernel),或是是稱卷積核濾波器(convolution filter),它內部的分量值就是用來描述想要進行搜尋及比對的目標樣態,它可以是一小段一維時序上待搜尋的訊號(target query sequence),也可以用來表示二維圖像上一種特定的圖像形式(target image pattern)。另外,卷積運算最後輸出值的大小,代表了待搜尋樣態發生於一維或二維資料上特定區段的顯著性。有趣的是,從過往視覺化卷積運算的研究成果[13]中,我們可以發現當多層次的卷積運算逐漸往上推疊時,越下層(淺層)的卷積運算參數所學到的圖像樣態,會越接近簡單的幾何線條與紋理,並且把這些低階、簡單的結構及紋理特徵做為更上層卷積運算的輸入。而越上層(深層)的卷積運算參數學到的,則是將這些簡單低階特徵組成更高階的圖像樣態,進行後續的樣態搜尋比對。如 圖1⒝示意圖以人臉偵測為例,淺層(Layer 1)的卷積運算著重偵測簡單的紋理及幾何線條,越是深層的卷積運算則是將淺層找到的樣態,逐漸拼接成具有應用意義的五官(Layer 2)及具體人臉(Layer 3)等樣態。
圖2、卷積運算計算式與示意圖⒜1-D時間序列[12] ; ⒝2-D影像資料
2.2 深度物件偵測方法(Deep Object Detection Method)
本案運用工地CCTV影像分析進行工地工安偵測需要的核心演算法為深度學習物件偵測演算法(Deep Neural Network for Object Detection)。所謂的物件偵測應用,其命題為預先定義要偵測的物件種類集合,例如 : 人員、車輛、安全帽、背心等,並在輸入影像上偵測這些物件發生的位置及種類。因此物件偵測應用會有如 圖3⒜下的輸出產生 : 不同顏色的方框(bounding box)是演算法針對輸入影像偵測出來的物件,方框上的文字說明演算法判定該方框的物件種類(例如 : 「human」或「helmet」),而方框上的數字則是演算法對於該偵測物件預測的信心程度(confidence score),例如「1.00」或「0.99」。使用者可以遵循如 圖4的流程進行應用的開發,達到物件偵測的功效。①資料整備階段-以人力及標記工具前處理大量的目前物件影像樣本,提供各種物件的標記資訊;②模型開發(訓練)階段-透過演算法工程師,設計合適的模型架構與目標函式(例如 : 物件偵測的準確率),並透過GPU平行運算裝置,搜尋最佳參數,建立物件偵測模型;③模型上線(偵測)階段-將物件偵測模型佈署到應用環境,例如 : 與工地CCTV串流影像整合,持續輸出偵測結果並做後續處理。
圖3、深度學習物件偵測演算法 ⒜輸出結果示意圖

圖3、深度學習物件偵測演算法 ⒝一階段(one-stage)類型方法
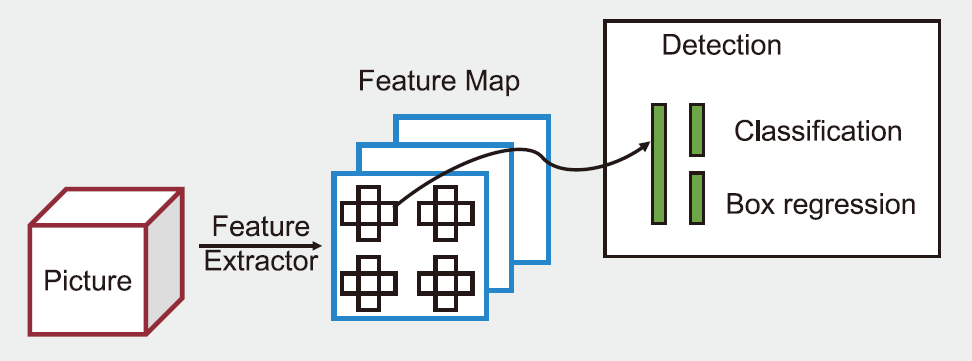
圖3、深度學習物件偵測演算法 ⒞二段類型方法[18]
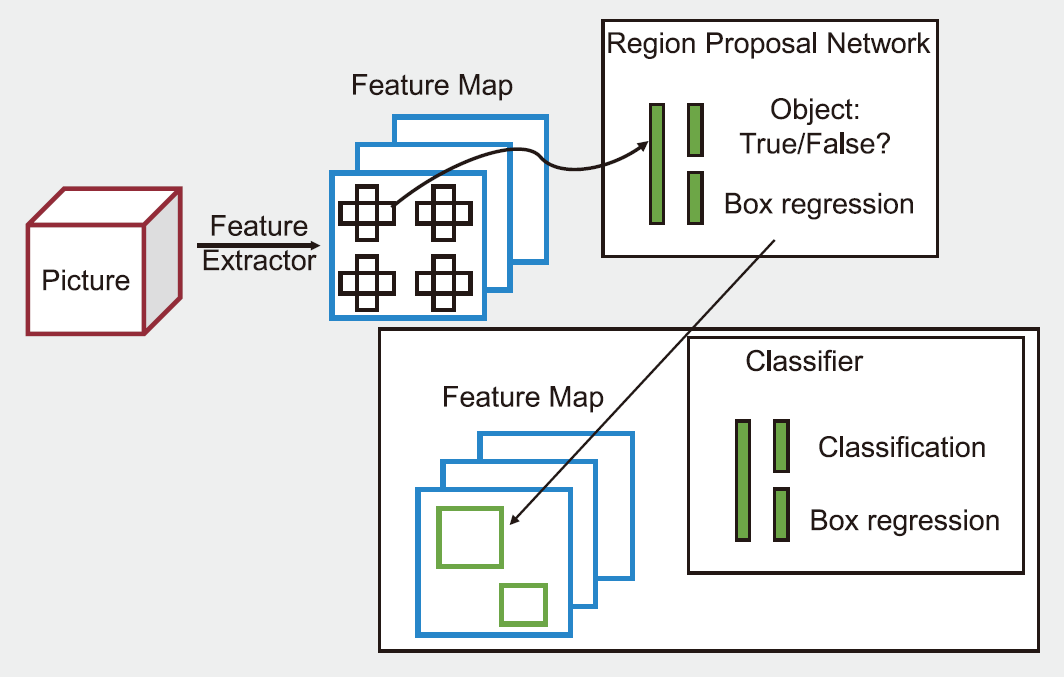
深度學習物件偵測演算法是以前述提到的深度卷積類神經網路模型為主體,透過推疊數個卷積運算網路層逐漸將輸入影像中的特徵圖(feature map)提取,並且對各子區塊所得的特徵圖進行分類,分類的結果會有兩類輸出,包括①Box Regression-指的是偵測物件的偵測方框的大小及位置;②Classification-指的是輸出該偵測方框所框列的物件之物件種類標籤(例如 : 「human」或「helmet」。一般說來,深度學習物件偵測演算法依其模型推論的流程,大致上可以分為「一階段方法」[14][15]或「二階段方法」[16][17]。一般說來,這兩類方法各有優缺點。「一階段方法」僅做一次類神經網路推論就可以輸出預測物件的類別標籤及位置,所以系統回應時間較快,較適合即時影像串流分析等系統運算速度較高的需求。而「二階段方法」因為有獨立的「區域提取網路」(Region Proposal Network, RPN)先行鎖定影像中可能存在物件的部份區域,後續的物分類只針對RPN輸出的前景物件做預測,可以過濾掉大量的背景雜訊,因此較適合對準確率要求較高,系統反應速度較為次要的應用。圖3⒝為深度學習物件偵測演算法中「一階段方法」及「二階段方法」的示意圖[18],對深度學習物件偵測演算法的發展演進有興趣的讀者可以再參照相關論文[19]。
2.3 互動式學習(Active Learning)
前述 圖4有提及深度學習影像辨識需要準備大量經有人力標記的影像樣本集(例如 : 「human」或「helmet」)。利用人力標記影像樣本是非常耗時耗心力的工作,平均而言每位標記員一天八小時的人力工時僅能標記約800~1200張影像,然而要訓練一個準確的物件偵測模型大概每種物件都需要數千至數萬張影像樣本不等。有鑑於影像標記的成本是如此昂貴,因此如何用最快速、經濟的方式評估未標記影像的標記價值,並且把有限的標記人力及時間投入在最有效益的影像樣本,便是互動學習技術(Active Learning)[9]的首要目標。如圖5⒜顯示互動式學習流程圖,由未標記資料集(unlabeled data pool)中,透過不同機制的互動式學習演算法,僅提取最有標記價值的未標記資料出來,再經由標記員(annotator)進行正確標記,加入已標記資料之中(labeled data pool),在僅投入有限的標記成本情況下最大化模型的成效。過往有許多的研究探討如何從未標記資料集中,排序及輸出最有標記價值的樣本進行標記[9]。常見的方法有隨機取樣方法(Random Sampling)及最大不確定性取樣方法(Most-uncertainty Sampling)兩種。其中最大不確定性取樣方法[9]主要利用式1,基於既有的分類模型,針對每個未標記樣本x進行分類確信度的亂度計算(Certainty Entropy)及排序,由高到低選擇具有最大分類亂度(Entropy)的樣本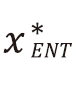 先進行標記,其中P(yi | x ; θ)表示樣本x基於模型θ分類為類別yi的機率。
先進行標記,其中P(yi | x ; θ)表示樣本x基於模型θ分類為類別yi的機率。
圖4、物件偵測演算法開發及導入流程
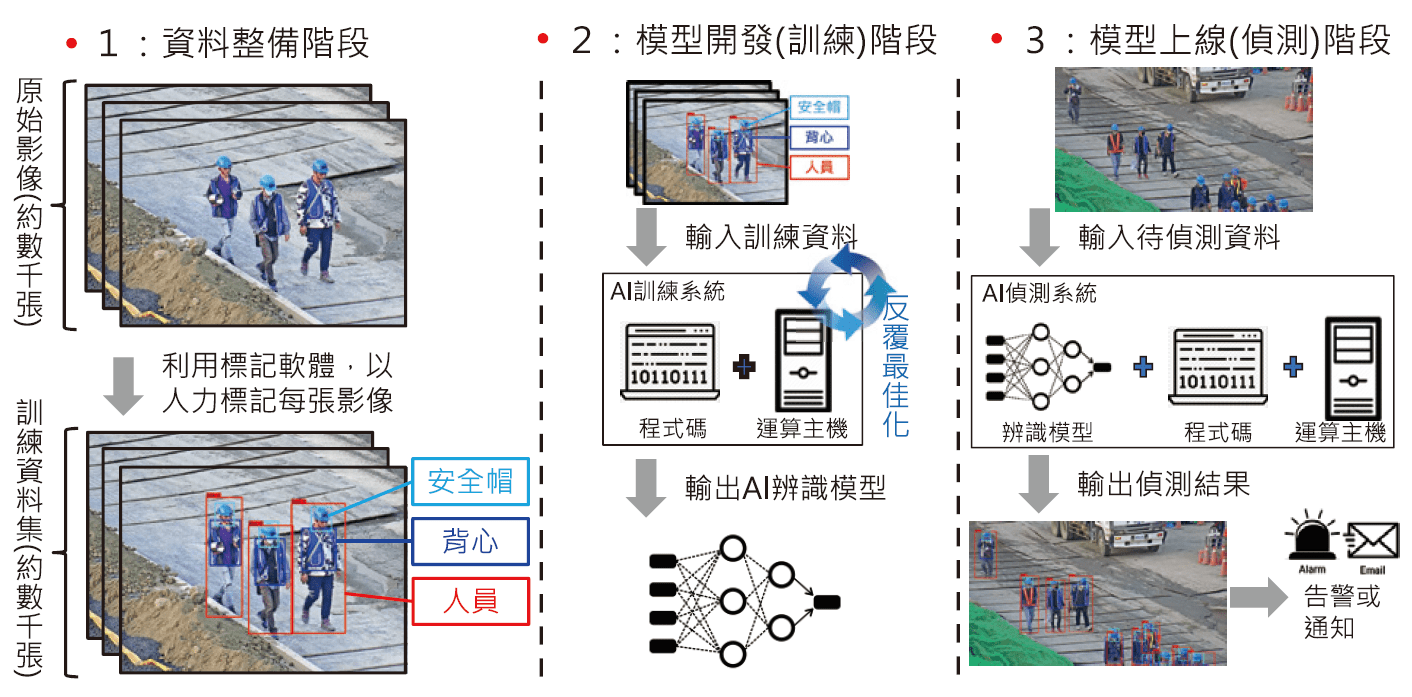
圖5、⒜互動式學習流程圖[9] ; ⒝遷移學習流程示意圖[20]
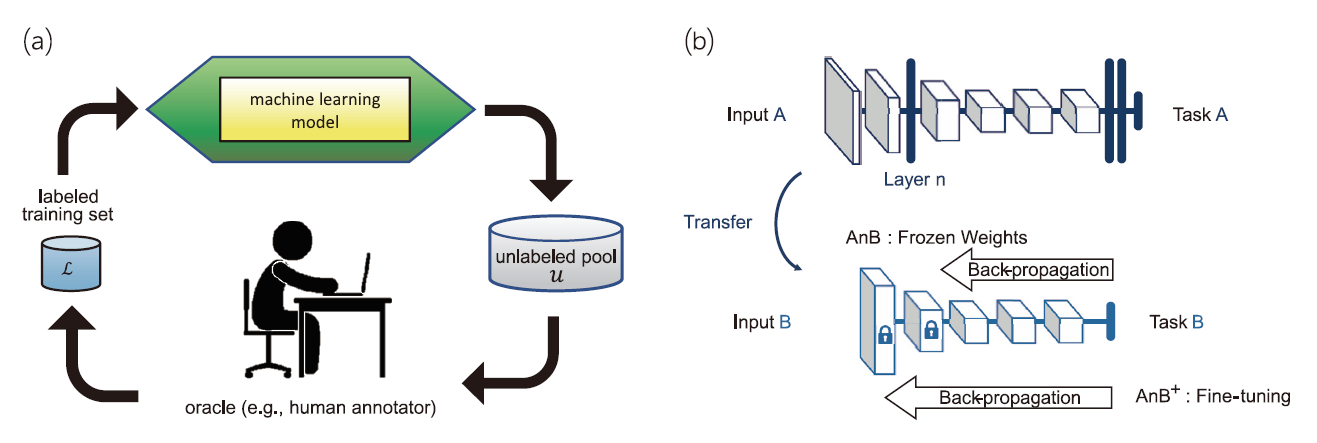
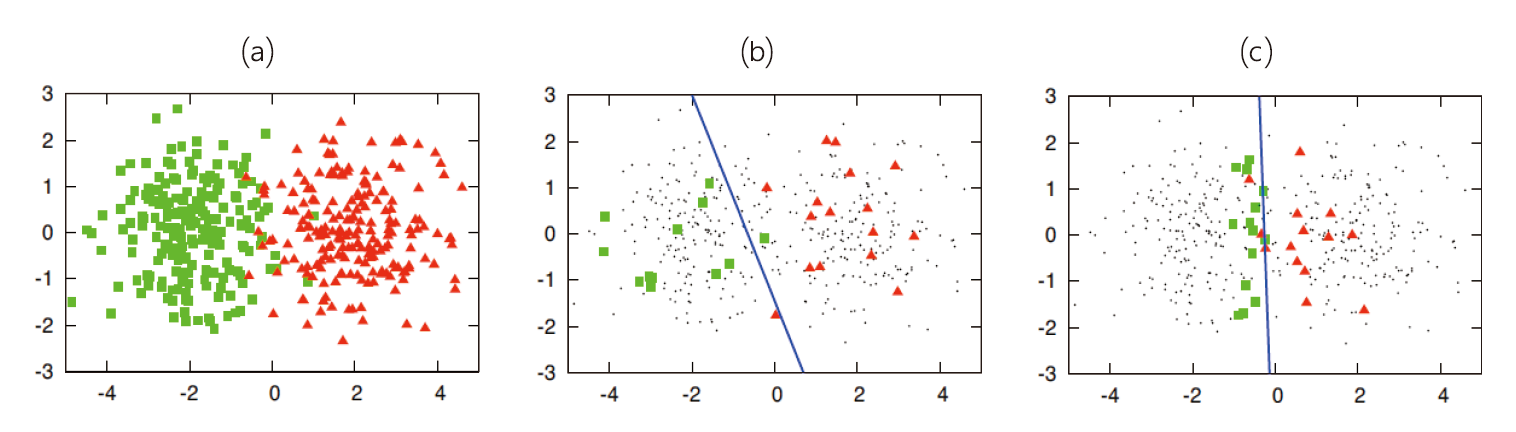
圖6簡單說明不同採樣方法在選擇未標記樣本上的互補性。圖6⒜為由兩個不同高斯函數分佈所生成的樣本資料集(綠色方塊及紅色三角形)。圖6⒝採用隨機方法進行取樣(Random Sampling),綠色方塊及紅色三角形表示被取樣到且進行標記的資料點,黑點則表示未被取樣類別未知的資料點。而圖6⒞則是利用式1進行最大不確定性取樣方法。圖6⒝及圖6⒞中的藍色直線,分別表示基於不同取樣方法進樣互動式學習進而可以得到的分類模型。由圖6可以發現不同取樣方法具有彼此互補的效果,因此實務上建議採用混合式策略,組合兩個簡單但有互補成效的互動式學習演算法。例如,同時採用隨機取樣及基於最大亂度評估來進行混合式的互動式學習,分別排序不同的未標記樣本進行人工標記。
圖6、不同互動式學習方法效果示意圖[9] ⒜基於兩個高斯函數所生成的樣本資料集 ; ⒝及⒞分別表示採用隨機取樣方法及最大不確定性方法
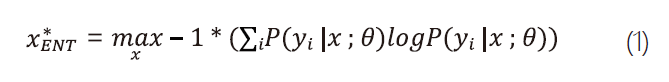
2.4 遷移學習(Transfer Learning)
傳統機器學習方法,在模型訓練階段處理訓練資料及在上線應用階段處理測試資料時,往往會有一前提假設(assumption) : 「訓練階段及測試階段所採用的資料需來自於相同的資料分佈(data distribution),並且有著同樣的特徵值特性(feature property)」。這個假設雖是令所有機器學習方法得以基於訓練資料產生模型,再將模型上線應用在測試場域的重要依據[4]。然而在現實的情況下,這個假設會遇到兩個挑戰。①在機器學習、深度學習和數據挖掘的大多數任務中,我們都會假設training和inference兩個階段,採用的數據皆會服從相同的分佈(distribution),資料特徵也都有相似的性質。但在變遷快速的現實環境中,這個假設很難長久維繫。例如欲在施工進度快速的工地中發展影像辨識應用,地形地貌及環境背景的快速變化,勢必會在工程進度的不同階段產生不同特性的影像資料,造成原有的辨識模型偏差失準;②第二項困難,來自於深度學習模型本質上就是高度仰賴大量資料來訓練模型的演算法類型,其所需要的資料級距,往往是數十萬張或是數百萬張影像的量級,要去一一蒐集與標記這個級距的資料,會讓專案開發初期所需投入的人力工時成本變得滯礙難行。
遷移學習(Transfer Learning)[10][20]便是基於上述兩項困難點,試圖在機器學習算法落地應用時,提出一個合理可行且有經濟效率的作法。遷移學習基於一個普遍的假設 : 「我們在來源場域(Source Domain)所解決的問題、所積累的知識、所生成的模型,經過妥善的處理及存儲後,能夠遞移到下一個目標場域(Target Domain),幫助我們解決相關的問題。」換句話說,遷移學習就是探討如何使用最少的成本(包含人力工時或是機器計算時間),將原先訓練好的模型,重新適配於新的環境之中,解決新的問題。
圖5⒝就是遷移學習運作示意圖[20],章節2.1 圖1中有說明深度學習模型淺層的權重參數主要做為影像特徵萃取(Feature Extraction)之用,因此在遷移學習過程中,我們會將應用於來源場域(Source Domain)任務A的深度學習網路模型A取出,把模型A淺層(for#Layer<n)的結構及權重參數都固定下來成為Frozen Weights複製到目標場域(Target Domain)任務B的深度學習網路模型模型B中。模型B的淺層結構(for#Layer<n)與模型A完全一致,對於模型B的後段(for#Layer≥n),則由開發人員客制化設計需要的模型結構,並以任務B的訓練資料來最佳化後段的權重參數。遷移學習的好處,在於模型A可以是基於超大型影像資料集的訓練成果(e.g., ImageNet),要訓練這樣的大型資料集(Input A)所花費的計算成本相當高,而模型B得直接取用模型A所訓練出的特徵萃取的成果及功效,並且僅以最少的輸入資料(Input B),調校必要的參數來滿足任務B的特定需求。透過遷移學習可在開展新應用場域或對既有模型進行重新效準時,大幅度節省所需的人力標註及機器計算成本。
3. 研究方法
3.1 MLOps機器學習維運流程(Development and Operations w/Machine Learning)
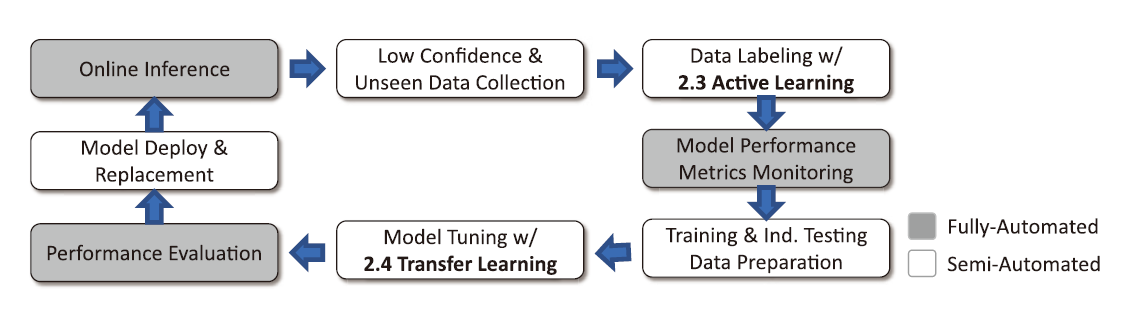
MLOps主要是由機器學習(Machine Learning, ML)及開發與維運(Development and Operations, DevOps)兩個資訊領域的衍生字結合而來,簡單來說就是適用於機器學習的DevOps流程。由章節2.3及2.4可知,機器學習應用在開發階段需要有效率地累積大量訓練資料,在上線應用一段時間後,或是佈署既有系統到其他場域時,也需要進行維護校準。而為這些必要的開發及維護工作,設計標準作業程序並整合到機器學習應用整體的生命週期之中,為開發及維運人員提供運營效率及便利性,便是把MLOps的精神融入在使用者介面及操作流程上的主要效益。圖7為MLOps流程生命週期示意圖。若從左上角的線上偵測開始,透過不斷搜集判定準確性不佳的影像,進行資料標記(Data Labeling)、模型校準(Model Tuning)及評估,並且將重新校準訓練好的模型,替換掉原本線上使用的模型。這一連串的步驟構成MLOps中的必要流程。而在其中最花費人力時間與計算成本的階段分別是Data Labeling及Model Tuning,於此兩項我們分別以2.3互動式學習(Active Learning)及2.4遷移學習(Transfer Learning)來進行流程的最佳化,藉此減少人力標記影像數量及加速模型校準的計算時間。
圖7、MLOps流程生命週期示意圖
3.2 系統架構
圖8為本計畫中CCTV AI監控系統的架構圖,重要的系統模組包含 :
圖8、CCTV AI工安監控系統架構圖
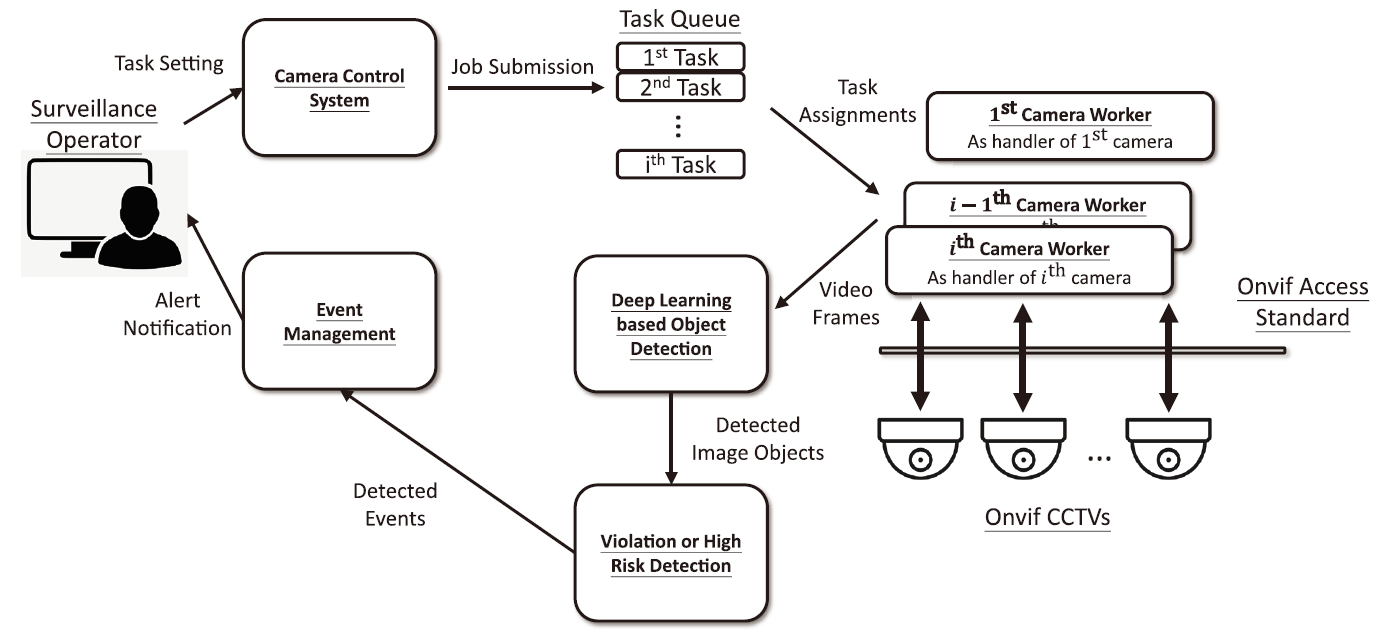
- Camera Control System : 提供監控操作員(Surveillance Operator)所需要的操控介面,包含 :
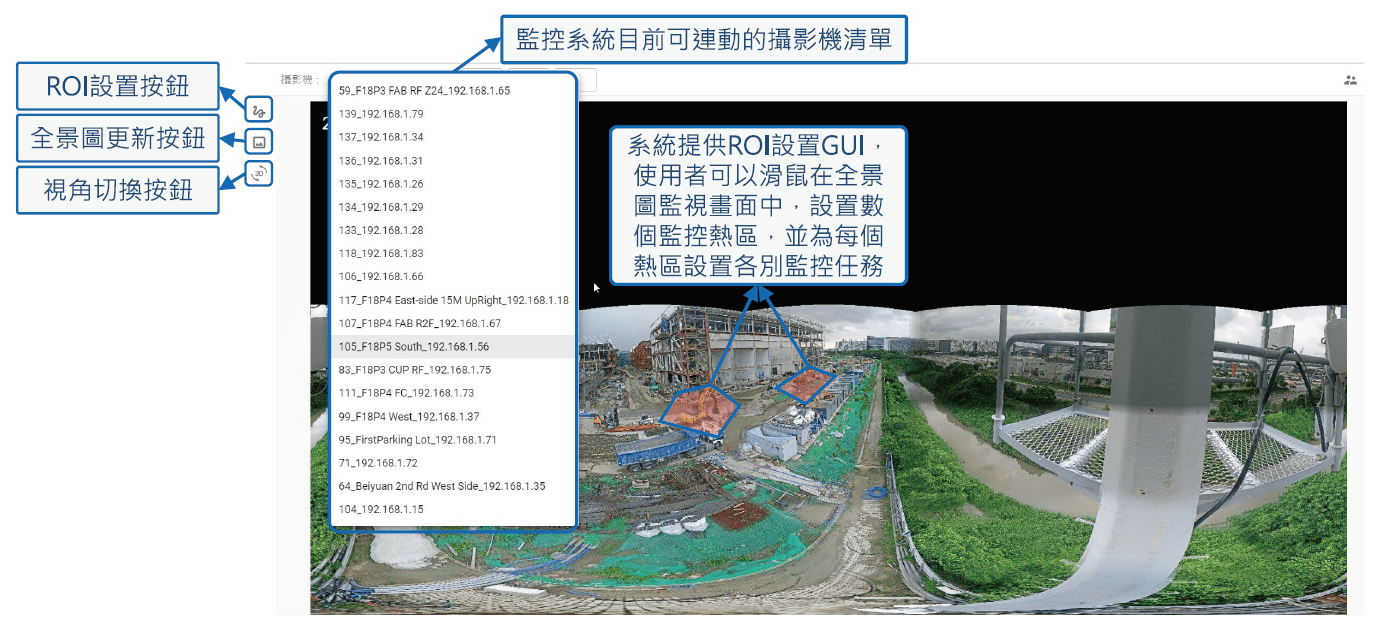
- 每日定期更新攝影機環景視野圖(panorama),提供使用者可監控視野下的最新影像
- 提供GUI,於環景視野圖上設置感興趣的監控熱區(Region of Interest, ROI)
- 針對每一個ROI設置特定的監視任務(e.g., 電子圍籬區域侵入/侵出、個人防護設備穿戴偵測等。)
圖9為GUI介面示意圖說明ROI任務設置之效果。圖9、CCTV AI監控系統監視區域ROI介面說明
- Task Queue : 經Camera Control System所設置的監控任務區域,會儲存於Task Queue中,定期分派給各Camera Worker模組做各別攝影機的操控執行。
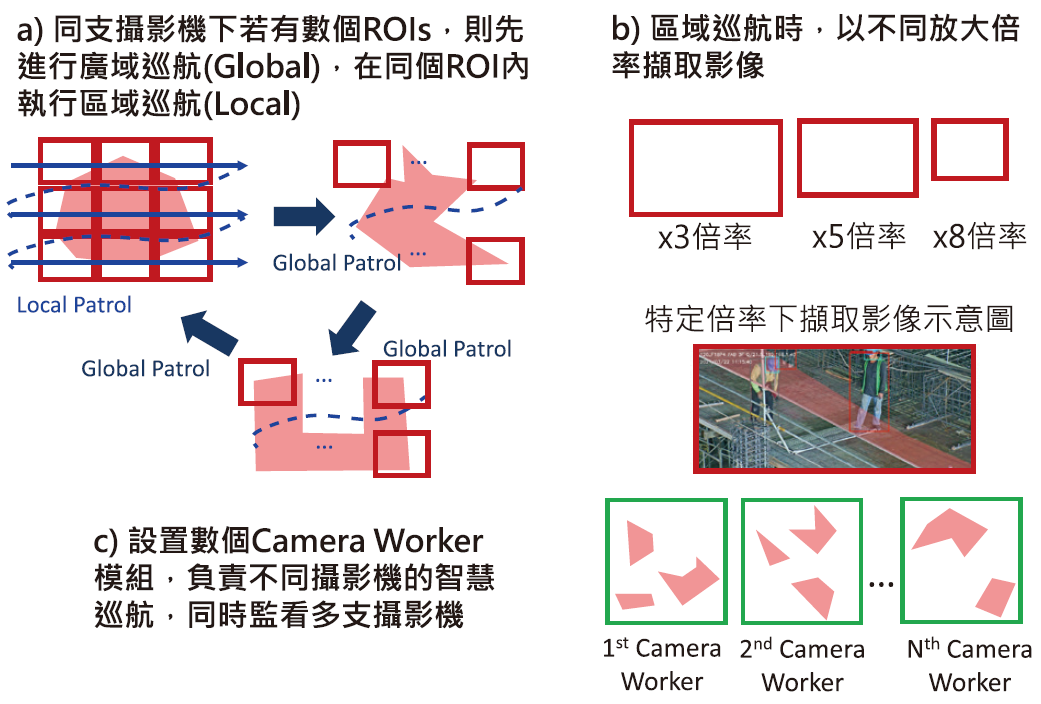
- Camera Worker模組 : 在本案的監控系統中有實作多個Camera Worker模組,接獲Task Queue的攝影機任務安排後,透過Onvif標準指令介面[21],遠端搖控Onvif攝影機,令各攝影機依據所被指派的ROI區域,進行智慧巡航擷取即時影像。圖10為Onvif攝影機搭配ROI設置後,進行智慧巡航的執行邏輯示意圖。
圖10、CCTV AI攝影機智慧巡航示意圖
- Deep Learning based Object Detection : CCTV AI工安監控系統中,Camera Worker模組擷取ROI區域中的影像截圖後,將影像截圖輸入至Deep Learning based Object Detection模組。於此模組中,針對不同影像辨識需求,有實作多種用途的影像偵測演算法,包含 : 物件偵測、影像分割、物件追蹤及人臉身份識別。經運算後輸出多項物件識別結果,做為下一階段運算的輸入資訊。
- Violation & High Risk Detection : 本模組實做工安管理規則,例如 : 於設定的電子圍籬高風險區域,偵測人員的侵入/侵出,或是估測吊掛物起吊的高度並偵測人員闖入管制區等。這部份會以Deep Learning based Object Detection偵測出的影像物件做為輸入,著重在演算法邏輯運算,進行工安違規項目或高風險行為的判定。
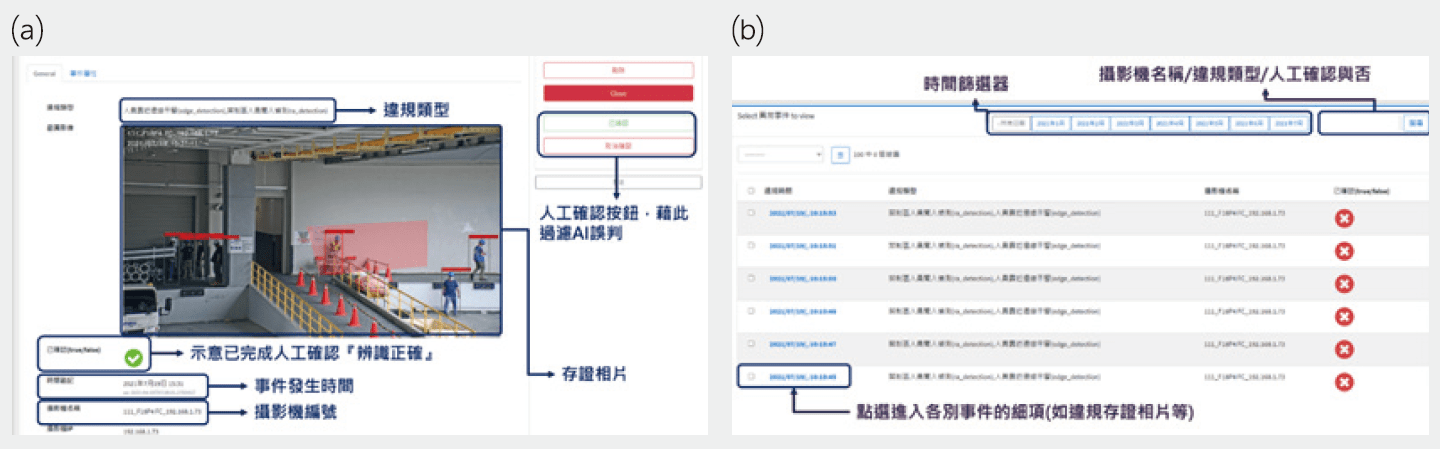
- Event Management 模組 : 主要接收Violation & High Risk Detection模組所偵測的事件,進行事件的即時告警及事後查找等功能。圖11為Event Mangement對應的操作介面。其中,圖11⒜為違規及高風險行為即時告警畫面。一旦Violation & High Risk Detection偵測為高風險事件,立即在系統網頁上提供偵測事件種類、攝影機編號、偵測時間及事件存證相片等資訊,並且以警示音提醒工安值班人員。此外,在每一個偵測事件網頁中,都提供人員確認按鈕,經工安值班人員確認為正確偵測(True Alarm)或是錯誤偵測(False Alarm)後,這些監督式的標駐資料都可做為珍貴的訓練資料。此為MLOps概念下一種互動式學習的實現方式。圖11⒝則為CCTV AI監控系統提供之累計違規及高風險行為查找頁面,使用者可在此頁面中,針對不同資訊做為過濾依據,進行歷史事件的查詢。例如 : 依據事件發生的時間、偵測事件種類、攝影機位值及是否有人員進行誤判確認等條件。
圖11、CCTV AI工安監控系統-事件告警模組 ; ⒜違規及高風險行為即時告警頁面 ; ⒝累計違規及高風險行為查找頁面
4. 實驗分析
於本文撰稿同時,CCTV AI工安監控系統目前可偵測事件尚在拓展建置中,本章節將以目前可支援的 : ①險區域人員侵入/侵出偵測;②人員防護設備(PPE)穿戴完整性;③人臉影像身份辨識進行效能分析。不同實驗項目皆會揭露資料搜集方式、樣本分佈情形與量化偵測準確性等資訊,供讀者做為評估參考。
4.1 Case-高風險管制區域人員侵入偵測
本實驗主要評估以CCTV AI工安監控系統GUI介面,實作電子圍籬功能,設置ROI區域作為高風險區域,並偵測高風險區域的人員侵入事件。
4.1.1 資料分佈
本項實驗分佈如圖12,分別為三種實驗狀況 :
圖12、CCTV AI工安監控系統-高風險管制區域人員侵入偵測功能實驗場景擷取影像。
⒜高倍率小範圍管制區 ; ⒝低倍率小範圍管制區 ; ⒞低倍率大範圍管制區

- 圖12⒜高倍率小範圍管制區-實驗人員計有3位,以三角錐圍起區域為禁制區,人輪流走進去,可走入、跨入、由下闖入管制區。其中違規人次計有95人次 ; 無違規人次計有 504人次。
- 圖12⒝低倍率小範圍管制區-實驗人員計有3位,以三角錐圍起區域為禁制區,人輪流走進去,可走入、跨入、由下闖入管制區。其中違規人次計有98人次 ; 無違規人次計有 360人次。
- 圖12⒞低倍率大範圍管制區-實驗人員計有5位,以紅色三角錐及黃色隔離墩圍起區域為禁制區,測試人員依序獨自或成群走進去,可走入、跨入、由下闖入管制區。其中違規人次計有124人次 ; 無違規人次計有 481人次。
4.1.2 實驗結果
在此實驗中,Positive Case為違規人次及Negative Case 為無違規人次,經實驗統計後,在三項實驗情境總計之分類混淆矩陣如 表1所示 :
| 實際違規 | 實際未違規 | |
|---|---|---|
| 預測違規 | 286(True Positive, TP) | 4(False Positive, FP) |
| 預測未違規 | 31(False Negative, FN) | 1341(True Negative, TN) |
其中,針對違規侵入事件(Actual Positive)其:
召回率(recall rate) =  x 100% = 90.22%
x 100% = 90.22%
精確率(precision rate) =x 100% = 98.62%
即在誤報(False Alarm)機率小於1.5%情況下,違規情事偵測率可達90%以上。
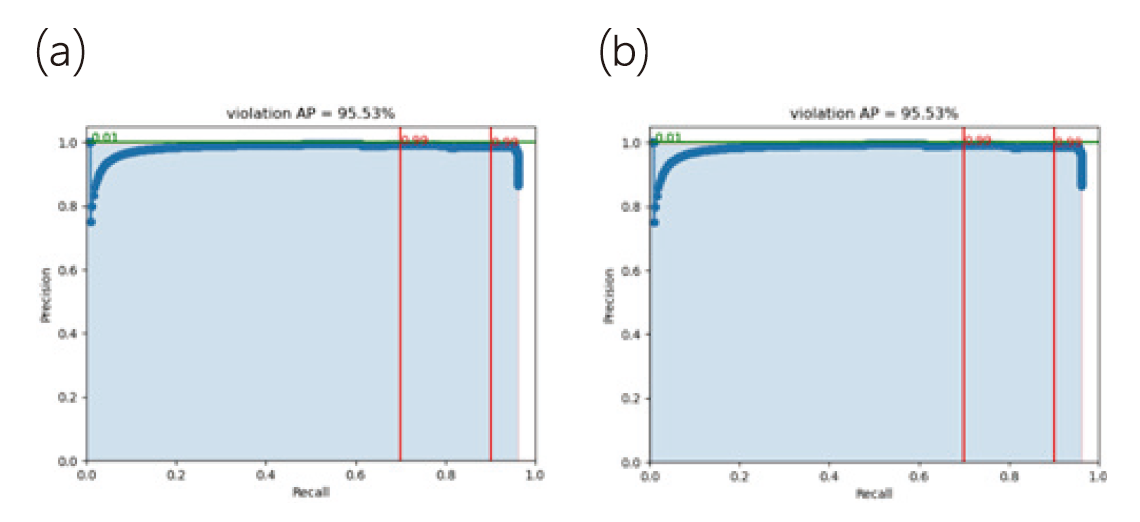
此外,若在Violation & High Risk Detection模組中,取用不同判定違規的門檻值參數設定,將會對偵測違規的兩項指標-召回率(recall rate)及精確率(precision rate)形成權衡取捨(trade-off)的情況。一般說來高召回率(較低漏報)會導至精確率降低(較高誤報),反之為提升精確率(較低誤報),往往也會連帶使得召回率降低(較高漏報)。圖14⒜為高風險管制區域人員侵入偵測的precision-recall曲線變化圖,在極度理想的狀況下,precision-recall下方的面積(area under curve, AUC or violation average precision)應為1.0,於本系統中AUC可達到0.9553。兩條紅色垂直線分別表示當recall rate定為70%及90%做為標準時,precision rate皆可達到99%。
4.2 Case-個人防護設備(安全帽)穿戴偵測
本實驗主要評估以CCTV AI工安監控系統GUI介面,實作電子圍籬功能,設置ROI區域作為高風險區域,並在ROI區域內增設安全帽穿戴偵測的監控任務。
4.2.1 資料分佈
本項實驗分佈如圖13,分別有三種實驗場域 :
圖13、個人防護設備(安全帽)穿戴偵測實驗場景擷取影像。
⒜低放大倍率影像(台南F18工地停車場) ; b)高放大倍率影像(新竹F12工務所後) ; ⒞高放大倍率影像(台南F18P4工務所人員上下班出入動線)

圖13⒜低放大倍率影像(台南F18工地停車場)-實驗人員計有4位,測試情境中人員只穿背心,不戴安全帽。四人並行沿著指定路線出發再回到原點。該場域目的在測試低放大倍率下的未戴安全帽違規偵測。
圖13⒝高放大倍率影像(新竹F12工務所後)-實驗人員計有3位,於固定放大倍率下,人員圍繞以三角錐圍起區域行走,並隨意穿、脫安全帽。本場域的目的是希望藉由人員繞行的方式,可以測試受測人員以正面或背面影像偵測安全帽穿戴的準確性。
圖13⒞高放大倍率影像(台南F18P4工務所人員上下班出入動線)-本段影像為實際工區人員上下班出入動線上擷取之影像,實驗中擷取入鏡的人員計有4位。本場域規劃的目的是測試以實際人員行走的步態及速度等條件,進行安全帽辨識的準確性評估。
上述三種實驗場景,共有未穿戴安全帽(違規,Positive Case)計153人次及有穿戴安全帽(無違規,Negative Case)計121人次。
4.2.2 實驗結果
在此實驗中,Positive Case為違規狀況(153人次)及Negative Case為無違規狀況(121人次),其中經實驗統計後,在三項實驗情境總計之分類混淆矩陣如 表2
| 實際違規 | 實際未違規 | |
|---|---|---|
| 預測違規 | 138(True Positive, TP) | 0(False Positive, FP) |
| 預測未違規 | 15(False Negative, FN) | 121(True Negative, TN) |
其中,針對違規侵入事件(Actual Positive)其 :
召回率(recall rate) =x 100% = 90.19%
精確率(precision rate) =x 100% = 100.00%
即在針對封閉實驗資料集,極低誤報(False Alarm)情況下,違規情事偵測率可達90%以上。同時,圖14⒝為針對封閉實驗資料集進行安全帽穿戴偵測的precision-recall曲線變化圖,於本系統中AUC可達到0.9750。兩條紅色垂直線分別表示當recall rate定為70%及90%做為標準時,precision rate皆可達到100%。
圖14、針對封閉實驗資料集進行違規偵測的precision-recall曲線變化圖 ⒜高風險管制區域人員侵入偵測 ; ⒝安全帽穿戴偵測
4.3 Case-個人防護設備(背心)穿戴偵測
考量在工地情境中,反光背心具有安全示警作用,同時不同顏色的工作背心具有不同的功能與意義,例如 : 紅色背心為監火人員、綠色背心為吊掛人員等。本實驗主要評估以CCTV AI工安監控系統GUI介面,實作電子圍籬功能,設置ROI區域並在其內偵測包括 : ①有無穿戴工作背心;②區分工作背心的顏色等,供監控人員在適當情境下設置不同偵測條件。
4.3.1 資料分佈
本項實驗資料集直接收集來自F18工地之CCTV影像,示意圖如 圖15。其中 :
圖15、背心穿戴與否及顏色區分實驗影像示意圖
- 辨識穿戴背心與否情境-在規劃的實驗下,總人次計有3,782人次,其中有穿戴背心(不分顏色)的計有2,689位,未穿戴背心的計有1,093人次。
- 區分不同顏色背心情境-在工地實景資料收集下,穿戴不同顏色背心的實驗人員計有1,367人次,其中包含各式工地區域中常見背心顏色及對應工作職掌如下 : 粉紅色-清潔人員(145人次)、紅色-監火人員(288人次)、橘色-安衛人員(64人次)、綠色-吊掛人員(144人次)、藍色-管制人員(152人次)、紫色-引導人員(145人次)與其他顏色(431人次)。
4.3.2 實驗結果
在辨識穿戴背心與否情境實驗中,Positive Case為未穿戴背心狀況(1,093人次)及Negative Case為有穿戴背心狀況(2,689人次),其中經實驗統計後之分類混淆矩陣如 表3 :
| 實際違規 | 實際未違規 | |
|---|---|---|
| 預測違規 | 947(True Positive, TP) | 6(False Positive, FP) |
| 預測未違規 | 146(False Negative, FN) | 2,683(True Negative, TN) |
其中,針對未穿戴背心狀況(Actual Positive)其 :
召回率(recall rate) =x 100% = 86.64%
精確率(precision rate) =x 100% = 99.37%
另外,在區分不同顏色背心情境為一多分類問題實驗,共計七類。其中各類資料分佈下的召回率及精確率,分別整理為 表4的分類混淆矩陣 :
|
實際 \ 預測 |
粉紅色 | 紅色 | 橘色 | 綠色 | 藍色 | 紫色 | 其他 |
|---|---|---|---|---|---|---|---|
| 粉紅色 | 145 | 0 | 0 | 0 | 0 | 0 | 0 |
| 紅色 | 0 | 288 | 0 | 0 | 0 | 0 | 0 |
| 橘色 | 0 | 0 | 62 | 0 | 0 | 0 | 0 |
| 綠色 | 0 | 0 | 0 | 144 | 0 | 0 | 0 |
| 藍色 | 0 | 0 | 0 | 0 | 152 | 0 | 0 |
| 紫色 | 0 | 0 | 0 | 0 | 0 | 145 | 0 |
| 其他 | 0 | 0 | 2 | 0 | 0 | 0 | 431 |
| 召回率 | 100% | 100% | 96.88% | 100% | 100% | 100% | 100% |
| 精確率 | 100% | 100% | 100% | 100% | 100% | 100% | 99.54% |
由實驗可知,在人員可穿著便服的情況下,因有部份便服的款式設計、花樣紋理接近背心款式,因此並不容易完美區隔人員是否有穿著背心。對於人員未穿戴背心(違規)的辨識精確率可達99.37%(低誤判),然而在違規召回率則尚有進步空間(僅達86.64%)。不過若在給定人員皆有穿戴工作背心的情況下,扣除「其他顏色類別」後,常見的工地區域背心顏色識別的平均召回率達99.48%、平均精確率達100%。代表監控人員後續可利用區分各種背心顏色做為手段,來對特定區域內進行特定人員管控。例如 : 吊掛作業範圍,需有綠色背心吊掛指揮人員。
5. 結論及未來展望
近年來工地建設的施工進度,在現代工法技術的加持下,不論是施工推進的速度、單一場域的規模都有顯著提升。為求管控及強化施工人員安全,僅靠傳統CCTV影像錄製系統及人員長時間目視監控的作法,恐會成為大規模工進下安全監控的瓶頸。本研究嚐試開發遠端CCTV攝影機的智慧化巡檢系統,提供目視人員設置監控熱區,定期執行巡檢任務。同時在對齊工安管控的專家知識下,引入深度學習人工智慧技術,從CCTV系統所擷取的影像中,自動化過濾可能潛在的高風險行為(風險區域管制及PPE穿戴偵測),加以示警及通報。後續將結合更多工安專家知識,嘗試開發包含 : 高處作業安全掛勾是否使用、吊掛作業執行中是否有人員闖入、人員受傷昏迷、動火作業管控等更多重要的工安管控項目。
參考文獻
- Statistics, Bureau of Labor. "National Census of Fatal Occupational Injuries in 2019." Washington, DC: Bureau of Labor Statistics (2020).
- 勞動檢查統計年報,勞動部職業安全衛生署,網址: https://www.osha.gov.tw/1106/1164/1165/1168/
- Alom, Md Zahangir, et al. "The history began from alexnet: A comprehensive survey on deep learning approaches." arXiv preprint arXiv:1803.01164 (2018).
- Mitchell, Tom M. Machine Learning. New York: McGraw-Hill, 1997.
- He, Kaiming, et al. "Deep residual learning for image recognition.Y 2016.
- Fang, Qi, et al. "Detecting non-hardhat-use by a deep learning method from far-field surveillance videos." Automation in Construction 85 (2018): 1-9.
- Wang, Mingzhu, et al. "Predicting safety hazards among construction workers and equipment using computer vision and deep learning techniques." ISARC. Proceedings of the International Symposium on Automation and Robotics in Construction. Vol. 36. IAARC Publications, 2019.
- Nath, Nipun D., Amir H. Behzadan, and Stephanie G. Paal. "Deep learning for site safety: Real-time detection of personal protective equipment." Automation in Construction 112 (2020): 103085.
- Settles, Burr. "Active learning literature survey." (2009).
- Pan, Sinno Jialin, and Qiang Yang. "A survey on transfer learning." IEEE Transactions on knowledge and data engineering 22.10 (2009): 1345-1359.
- A.I. Technical: Machine vs Deep Learning. https://lawtomated.com/a-i-technical-machine-vs-deep-learning/
- Convolution on Wikipedia. https://en.wikipedia.org/wiki/Convolution
- Karn, Ujjwal. "An intuitive explanation of convolutional neural networks." The data science blog (2016).
- Redmon, Joseph, et al. "You only look once: Unified, real-time object detection." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
- Wang, Chien-Yao, Alexey Bochkovskiy, and Hong-Yuan Mark Liao. "Scaled-yolov4: Scaling cross stage partial network." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
- Girshick, Ross. "Fast r-cnn." Proceedings of the IEEE international conference on computer vision. 2015.
- He, Kaiming, et al. "Mask r-cnn." Proceedings of the IEEE international conference on computer vision. 2017.
- Kemajou, V. N., Bao, A., & Germain, O. (2019, April). Wellbore schematics to structured data using artificial intelligence tools. In Offshore Technology Conference. Offshore Technology Conference.
- Agarwal, Shivang, Jean Ogier Du Terrail, and Frédéric Jurie. "Recent advances in object detection in the age of deep convolutional neural networks." arXiv preprint arXiv:1809.03193 (2018).
- Kamath, Vinayaka R. "Transferred Fusion Learning using Skipped Networks." arXiv preprint arXiv:2011.05895(2020).
- Onvif Profiles and Specifications. https://www.onvif.org/profiles/
留言(0)