摘要

建立大數據管理平台以提升水處理系統效能與實現設備預知保養
Keywords / Predictive Maintenance4,Artificial Intelligence8,Smart Water Treatment

在一個晶圓廠中,為維持系統的穩定運轉與品質要求,「維護保養」是一個重要的基本要素。在廠務的運轉系統中,往往我們會用傳統式固定時間或固定頻率的方式進行設備維護保養,但過度保養與維修保養不及的狀況都有機會發生。然而,系統因保養因素而產生的異常是大家最不願看到的狀況。如何減少非預期性的設備故障與系統運轉效能的最佳化,達到「智慧廠務系統」是目前努力的目標。本研究由水處理設備與處理濾材開始,利用既有的量測與監控數據,導入人工智慧進行大數據分析,找到設備與處理濾材之運轉健康指標,預先提供工程師判斷設備與濾材的狀況,評估是否需要保養維護,減少非預期性保養的成本與風險,期望達到「智慧水處理系統」的目標。
前言
在廠務水處理系統的運轉模式中,為了保持產出水的品質與系統的妥善率,我們制定維修保養操作守則(P.M.O.I.) 並透過對濾材、轉動設備與量測儀器的定期保養來維持一定的品質水準;但是,即使有定期保養,偶爾還是會發生非預期性設備異常或是系統處理單元效率變差,增加工程師異常處理的負擔與系統運轉的風險。因此,我們希望可以透過分析歷史資料與即時數據,建立大數據管理平台,以達到設備預知保養與系統處理效能最適化的目的。
研究動機與目的
為了使得廠務水處理系統運轉最適化,本研究希望能透過大數據與人工智慧找到好的方法與指標,進而將「定期保養」與「預防性保養」,提升為「預知保養」[1] 表1。定期保養為依照設備原廠建議或運轉經驗定義保養的頻率與時間,而預防保養則是在操作人員巡視或操作中發現設備異常所採取的維護保養,這兩種通常都是以時間為基準的維護保養;與前兩者不同的預知保養-是將歷史數據與運轉紀錄進行統計分析,提早於異常發生前發出提醒並指出可能造成異常的原因,讓工程師提早確認,避免造成更大的影響。
|
保養分類 |
定義 |
保養頻率依據 |
保養模式 |
|---|---|---|---|
|
定期保養 (Period Maintenance) |
依照運轉經驗定義之時間區間,進行設備保養維護 |
維修保養操作守則 原廠建議 運轉操作經驗 |
時間驅動保養 |
|
預防保養 (Preventive Maintenance) |
預防設備故障,保養人員巡視或操作人員操作中發現設備異常時,所採取之維護 |
維修保養操作守則 運轉操作經驗 |
時間或條件驅動保養 |
|
預知保養 (Predictive Maintenance) |
結合運轉經驗與統計分析,預測設備維修與耗材保養的時間 |
運轉經驗 人工智慧分析模型 (大數據智慧管理平台) |
條件或數據驅動保養 |
舉例來說,將泵浦的運轉時數、振動、溫度、電流、故障零件、故障原因等資訊,全部儲存進行統計分析,預測下次的故障時間與故障零件,可事先備料並提早維修更換,既可節省人力與庫存成本,又能降低運轉風險。又譬如水處理系統中,處理單元的處理效率與產出水質的變化,可藉由歷史的水質資料與耗材更換記錄,經由人工智慧統計分析並預測耗材下次更換的時間,預防水質異常超標,以及判斷合理的耗材更換週期,即時檢視水處理系統的運轉狀態,將系統的運轉模式最佳化。綜合上述的預知保養與系統耗材運轉最佳化,即是邁向「智慧管理」的開端。
目前工業界大部分廠務系統使用的PM管理平台流程圖如 圖1所示,記錄了廠區內各設備運轉耗材更換保養的紀錄,如逆滲透膜、活性碳、離子交換樹脂、轉動設備耗材、閥件、pH計等等,在此其中,有些更換是基於維修保養操作守則(P.M.O.I)定義之定期保養,有些則是由於設備故障進行的異常更換,是屬預防保養的部分。
圖1、一般常用PM管理平台流程圖

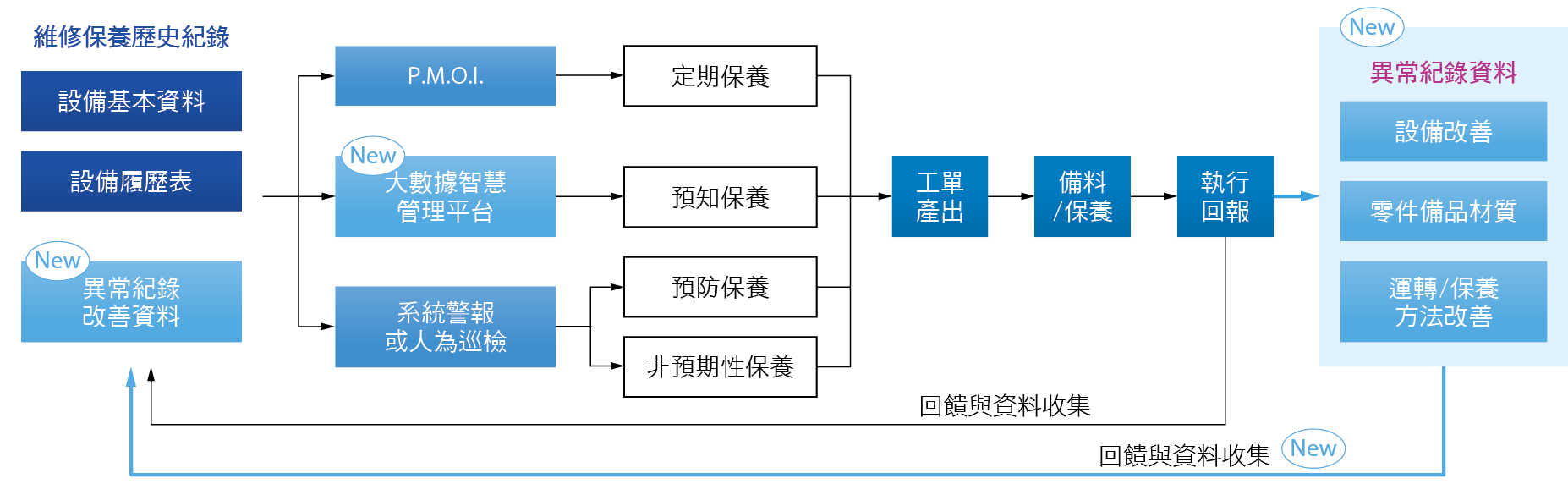
本研究的宗旨為延伸既有的系統架構,建立大數據管理平台 圖2-透過耗材備品更換之紀錄進行統計分析,將設備異常修復的事件變為預知保養,同時減少非預期性保養(un-expected PM)進而降低運轉風險與成本;另一方面也對於定期保養的耗材-如逆滲透膜、活性碳、離子交換樹脂等等,提供濾材處理效率之指標,作為更換的建議或依據。
圖2、結合大數據智慧管理平台之PM管理流程圖
研究架構
本研究將以廠務水處理系統設備為主,分為兩大主軸 圖3:一為針對水處理系統轉動設備,例如泵浦、鼓風機、馬達與攪拌機,收集其運轉相關數據加以分析,期望可獲得預測模型做為轉動設備預知保養的指標。第二個主軸則是聚焦於回收系統中的關鍵濾材,如逆滲透膜與活性碳,透過水質數據與運轉數據的分析計算,獲得最佳更換時間或運轉模式,讓濾材使用時限更合理且數據化,同時兼顧產水水質與系統運轉可靠度。
圖3、轉動設備與回收系統濾材

文獻探討
大數據分析
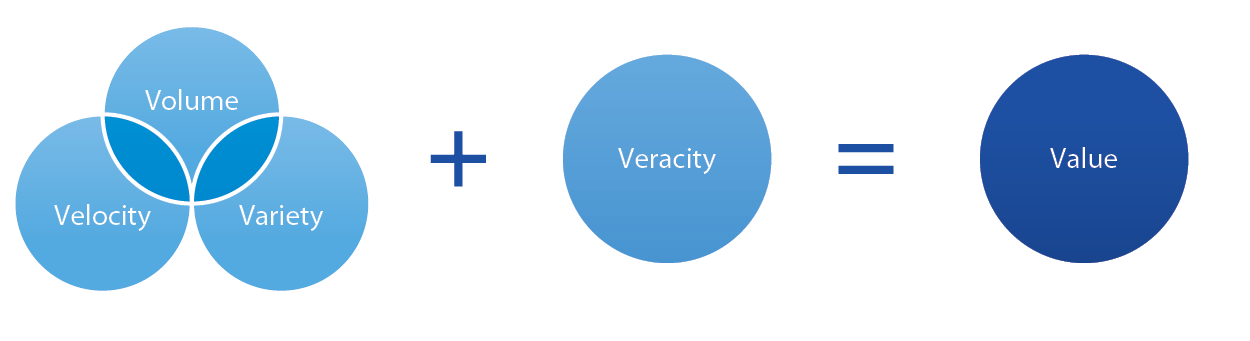
近年來,隨著各種通訊科技(無線傳輸/4G/5G…等技術)及電腦運算儲存能力的提升與融合,移動互聯網、物聯網、雲端運算等新技術發展日新月異,滲透並改變人類的生活,同時數據信息成爆炸式成長,大數據的時代已席捲而來。大數據,一般的定義為擁有「3V」特性的數據資料:大量的(Volume)-資料量多至有兆位元組,甚至更大的規模單位;多樣的(Variety)-可能是文字、語音、影像、圖片、類比訊號…等結構化與非結構化的包羅萬象的資料;即時的(Velocity)-強調資料的時效性,隨著時間推演產生大量的數據回饋。另外,也有其他學者提出第四種與第五種的「V」-Veracity (真實性)和Value (價值) 圖4,因數據具備大量、多樣與變化快的特性,資料的真實性也很重要;資料真實程度將會影響這些數據的價值。無論如何,這些數據產生的目的,即是要提供給決策者進行決策,或是研發者進行開發依據[2][3]。
圖4、大數據的「5V」特性[3]
目前應用大數據分析通常由三個要件組成:其一為資料收集與儲存的方法,如物聯網、無線傳輸用於資料收集,雲端運算平台(如Hadoop、Spark)與資料庫(如SQL、NoSQL)之於資料儲存。第二為資料計算分析,常見的計算分析技術如雲端運算與大數據分析(Big data analysis),乃至於人工智慧(Artificial Intelligence)與機器學習(Machine Learning)[4][5]。第三個要件為資料應用與反饋,運算結果提供決策者決策應用後,產生的結果再回饋至資料庫,將提升未來預測準確度。然而,因設備建置成本較高與資料樣本數量不足,目前大數據應用於工業界工廠效能分析之案例並不算很多。
人工智慧與機器學習
人工智慧(Artificial Intelligence, AI)一詞出現於1950年間,由Alan Turing提出圖靈測試[6]開始萌芽,在當時面臨的挑戰是硬體運算效能瓶頸及無法處理複雜度較高的問題,故發展前期主要是著重於理論的研究;經過了四十年持續的努力,儲存與運算硬體的問題逐漸被克服,許多以往過於複雜的演算法得以實現,人工智慧的研究從找出規則模擬人類思維─一強人工智慧(Strong AI)的範疇,轉向基於統計的方法來使機器自行學習資料進而找出規律,如同具有智慧的生物進行學習一般,即是「機器學習」(Machine Learning),同時也是弱人工智慧(Weak AI)的代表。近年來,人工智慧常用於人臉辨識、異常偵測與搭配大數據分析之行為與效能預測等等[7],已漸漸地改變人類的生活。
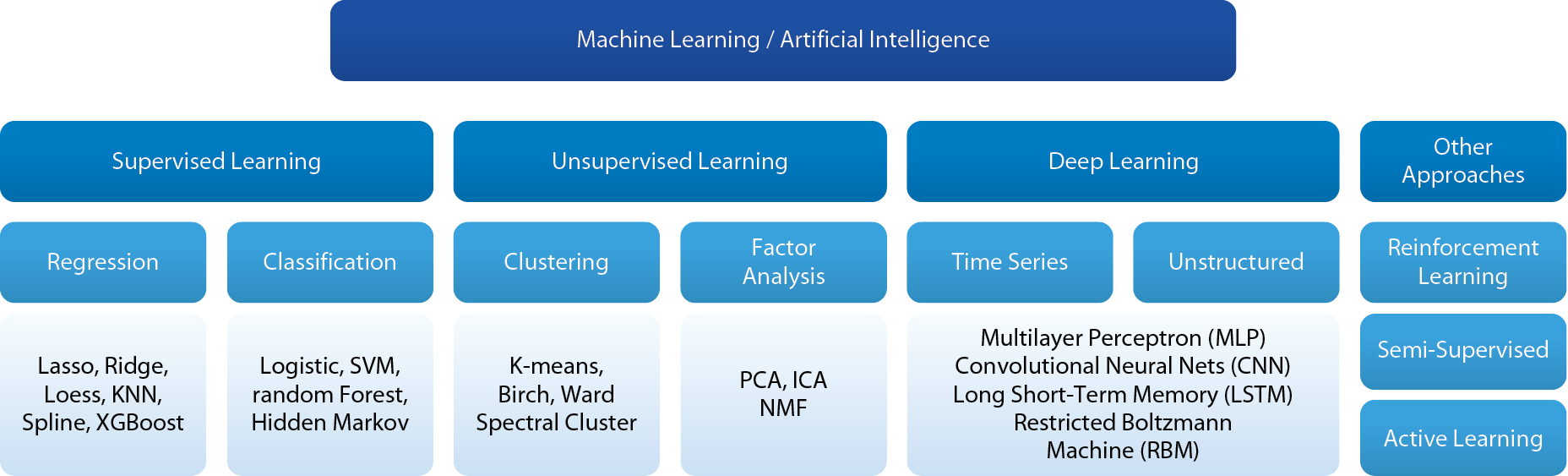
機器學習普遍可分為四類,如 圖5[8]所示:監督式學習(supervised learning)、非監督式學習(unsupervised learning)、深度學習(Deep learn-ing)與其他方法(增強式學習-reinforcement learning與半監督式學習-Semi supervised learning)[4][9]。監督式學習為將每筆數據標記(Label),讓機器學習分類(Classification);反之,非監督式學習則為讓機器自行透過數據的特徵(Feature)進行分類(Clustering)。每種學習方式都有其常用之演算法,如監督式學習的支持向量機(SVM)與K-鄰近演算法(KNN)[10],與非監督式學習的k-均值(k-means)演算法與主成分分析法(PCA)等等。如何決定學習方式與演算法,將影響這個模型預測的效果,一般而言資料科學家會依照數據與研究對象的特性找尋合適的演算法使用建立模型,並透過調整參數最佳化將預測準確度提升。
圖5、機器學習分類與其常見演算方法(資料來源:J.P. Morgan Macro QDS) [8]
大數據分析結合人工智慧於工業界的應用
美國發電廠效率提升與運轉管理
目前在全球工業界中大數據的應用較普遍使用在產品良率改善、廠房效率提升與客戶訂單預測。首先,我們以廠房運轉效率提升為例:美國坎薩斯州勞倫斯市與當地工程公司Black and Veatch合作,利用Black and Veatch Asset 360軟體之智能分析功能,優化當地電廠發電站的運作效率、分析計算電廠之運轉成本與影響成本之肇因,透過這些利用智能分析系統的主動判斷或提出建議,使決策者做出更明智正確的決策[11][12]。另外,Black and Veatch也有與勞倫斯市政府單位合作開發用於汽電共生與活性污泥系統的效能預測工具,使工廠管理人員能夠優化營運。最初開發的工具已率先用於發電廠的污水處理設施,預計未來將會擴展應用到整個城市的水處理設施。
水務單位應用於河川防汛與水資源管理
另一方面,大數據分析應用於政府水利部門水資源管理的策略[2][13],無論在國內外皆有一些案例正在開發進行中,其主要概念為整合水庫液位、降雨量資訊、河川液位、用水總量數據與污水處理納污量等等數據,並利用大數據進行分析,提供政府相關單位調度資源與政策的擬定及執行[2]。舉近年來台灣水利署提出之智慧水資源管理應用於防汛工程為例[13],結合物聯網與大數據的應用,即時回傳水庫與河川液位,依照液位高低控制水庫閥門作動,有效的操作減少了許多災情發生,而每次的事件資料收集也將會成為未來預測災害的重要基礎。
廠務系統應用案例
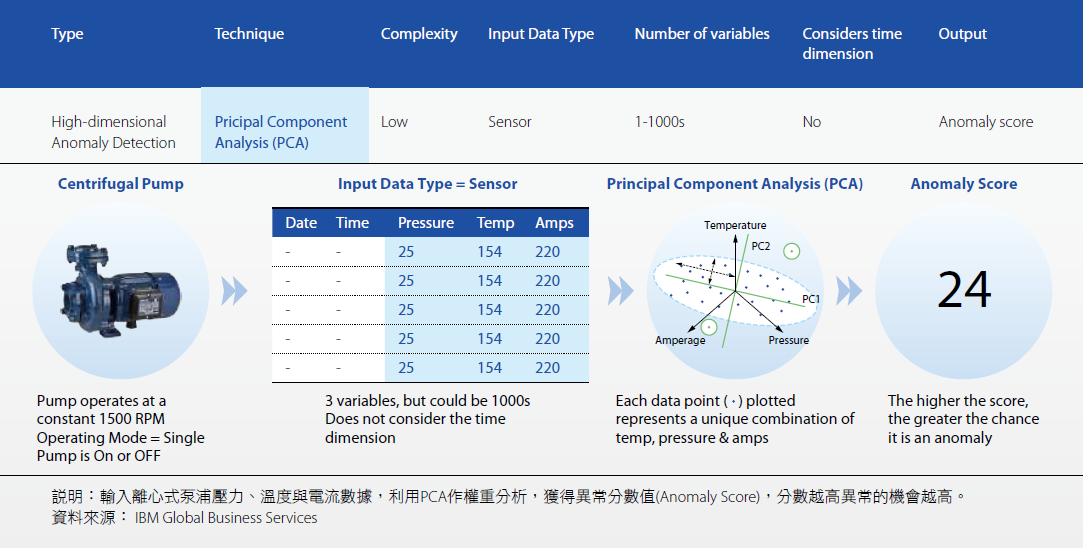
然而,對於廠務系統而言,大數據分析是否能有所應用呢?在水處理系統中,最重要的設備無非是負責輸送水的泵浦與水質淨化的濾材設備,是否能利用既有的數據做到智慧管理呢?工業界在轉動設備方面的預知保養的應用較多,依照設備屬性的不同,已有定義出不同指標做為故障發生的先期指標,較常見的為泵浦之振動頻率、運轉電流、運轉溫度等[14],透過這些數據的蒐集並用以統計學與大數據分析,除了可能獲得工程師經驗已知的結果,也有可能發現造成故障的新變數。如較成熟之轉動設備頻譜分析,在過去是需要透過人為進行數據分析與判斷,找到最可能的異常原因,但其缺點是人為判斷不一定永遠是正確的,且通常嚴重的故障都非單一肇因,用人為分析較可能忽略掉第二或第三個原因,讓故障無法根本解決導致容易再發。針對多變數之異常分析,常見的統計學與機器學習之手法為主成分分析法[7],為利用演算法找出最有影響的幾個特徵參數來做分類器模型的訓練,就可能用數據客觀的檢視造成故障的原因,並確實解決問題。除了能夠找到主要影響該設備故障的變數作為預測的指標,最終能將訓練好的模型作為預知保養的利器 圖6。
圖6、利用主成分分析進行高維異常檢測分析─以離心式泵浦為例
另外,在水質處理系統管理方面,芬蘭的造紙企業凱米拉(Kemira)公司,在2017年即有應用大數據分析來使得水處理系統的管理更加智慧化與有效率之案例[11][15]。以此案例經驗來說,凱米拉公司認為:造紙業的廢水處理流程大部分都屬於高能耗與高化學品使用量的操作,這樣的操作對環境較為不友善;同時,對於處理流程的控制與調整,如曝氣泵運作時間或是化學品加藥量等參數,大多是基於定時人為取樣量測數據與重複的實驗來進行判斷,因此工程師為了符合放流水質標準,常常會發生過度曝氣和過量加藥的狀況。為了改善此狀況,凱米拉公司進行了大量的研究並開發一種新工具可以非常準確和迅速地在幾秒鐘內預測水處理廠污泥的性質,通過整合現有的運轉數據、歷史過程數據、機器設備數據和化學分析數據,並搭配當地水處理廠進行測試。該工具的主要優點在於讓操作者可更好地區別和了解影響污泥乾燥的關鍵條件以及其化學特性,並提供了降低運營成本的方法。未來可利用傳感器即時測量系統的水質與水量,如pH、氧氣、營養物質、磷酸鹽、硝酸鹽、污泥乾燥度、病原體等變量,搭配正確的人工智慧演算法,使數據可進一步用於持續優化泵浦運轉的能耗以及化學品的使用量。經過這種優化過程,可最適化系統的操作並將操作成本合理化,同時仍然符合排放水之法規需求。
透過以上文獻回顧與案例研究,我們認為要達成廠務水系統的運轉效能最適化與設備預知保養之智慧管理,需結合大數據分析與人工智慧將廠務水系統運轉優化,期望可將非預期性保養的發生降至最低同時也減少運轉成本。
研究方法
研究計畫
本研究與成功大學工程科學研究所與IBM大數據分析與高級分析優化部門合作,以廠務水處理回收系統之運轉數據做為資料來源,利用人工智慧進行大數據分析與預測,並提供運算與開發平台所需之軟體,期望未來可作為PM管理平台的延伸,增加其在PM管理的多元性與功能性,進而達成水處理系統效能最適化與設備預知保養的目的。
首先,以氣體洗滌塔回收系統(Local Scrubber Reclaim System, LSR)為主要研究對象,針對此系統之濾材處理效率與轉動設備運轉狀態進行研究,但非耗材類設備之維護(如變頻器內部元件監測或電盤內部元件)並不再此次研究範圍內。我們藉由傳感器量測水的導電度、氟離子濃度、酸鹼度、流量計與壓力計等水質資料,進行濾材處理效率的探討;另一方面,我們會聚焦於此系統的轉動設備-泵浦,導入運轉時數、運轉頻率、振動量測數據與運轉電流,以既有量測數據進行分析,找到可能減少非預期性保養的機會點。
研究流程步驟
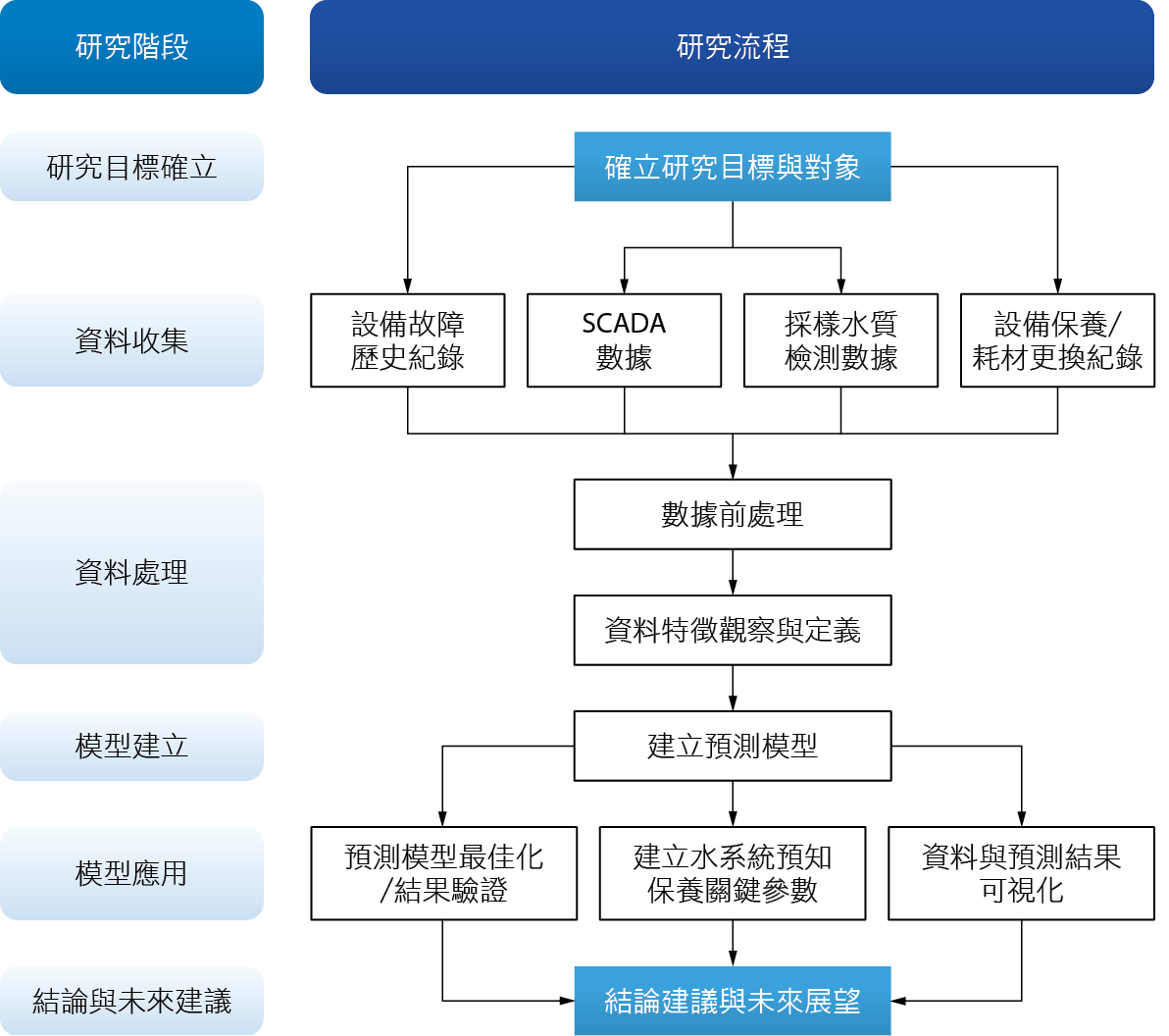
研究流程相關說明如 圖7所示。第一階段是決定研究目標與對象,第二階段則是收集SCADA回傳數據、水質取樣數據、設備保養紀錄、耗材更換紀錄與設備故障歷史紀錄等相關運轉數據,並補足可能會缺乏的資料點。第三步為資料分析與數據處理,定義可能會造成機器誤判的雜訊,並完成數據特徵標記(Feature Label),以利後續模型的建立。完成資料處理後,接著是演算法選用與模型建立,將其中百分之八十的數據用以機器訓練(Training),剩餘百分之二十用於結果驗證與預測(Predicting),選擇預測結果較好的模型並進行後續的參數調整與最佳化。第五階段為模型的應用,將各種收集的數據可視化,可視化後更便於人類或是機器進行參數之間關聯性分析,藉此我們可以進一步找到關鍵參數以作為預知保養的指標。最後針對本研究結果討論,提出推廣至其他廠務系統的可行性與未來展望。
圖7、研究流程說明圖
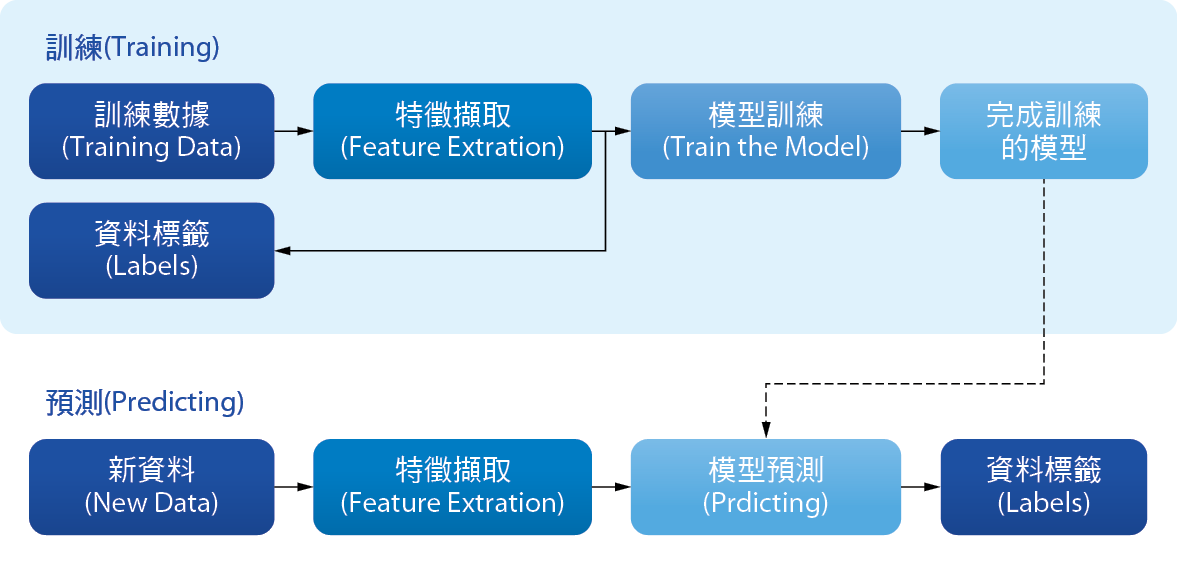
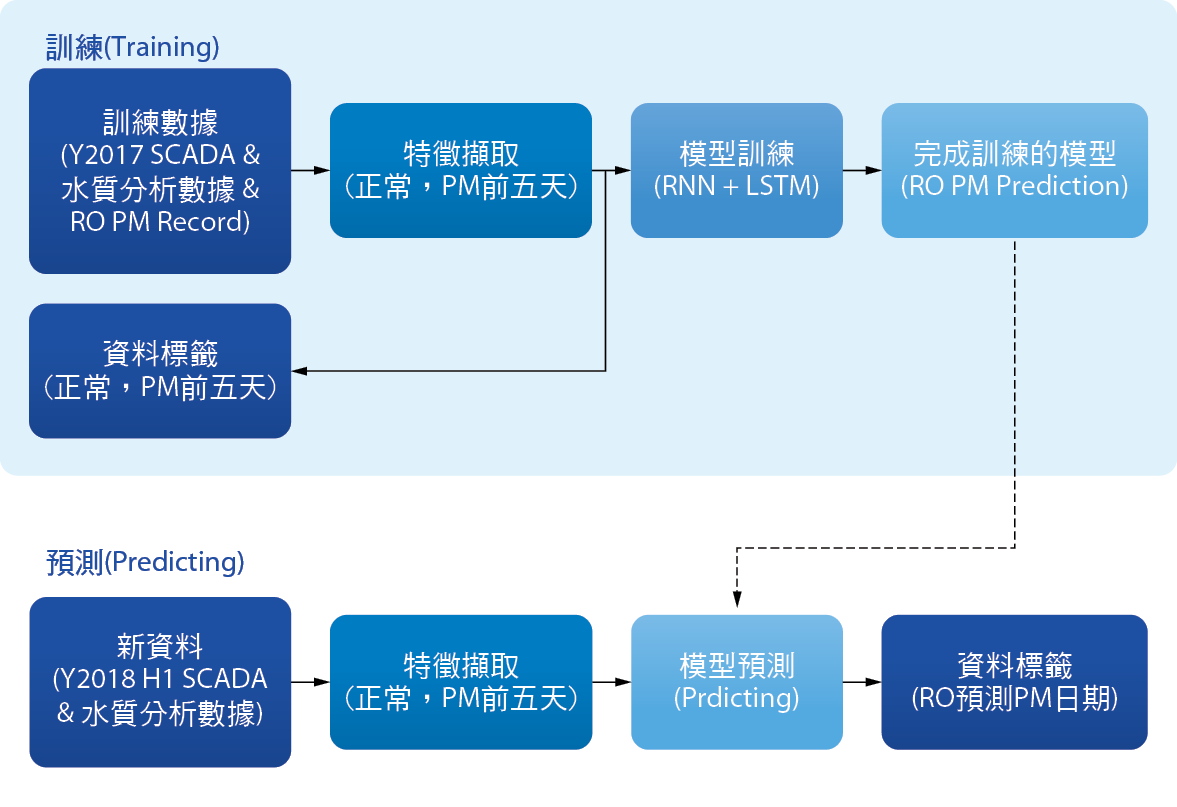
因受限於本次研究內容導入的資料量較少,僅2017年數據用於模型建立,與2018上半年數據用於驗證結果,結果準確度不一定可以達百分之百,故希望能將建立預測模型之流程標準化,作為提供未來相關廠務系統預知保養模型開發之標竿。 圖8為本研究建立預知保養模型之流程,模型的建立分為兩階段-訓練(Training)與預測(Predicting)。訓練階段將訓練數據導入並完成資料標籤,讓機器學習資料的特徵並加以訓練,完成初步的模型;預測階段把新的資料導入模型,經過模型判斷其特徵後產出預測分析結果。完整的模型需要多次的驗證與訓練,並非一蹴可及,資料量越是足夠,則預測的準確度越高。
圖8、建立預知保養模型之流程圖
資料前處理與模型選定
開始訓練機器之前,將蒐集的資料參數進行分類,即所謂的「貼標籤」(Label),我們必須先定義正常資料與異常資料,才能使得機器學會判斷。以逆滲透膜的處理效能為例,目前廠務工程師通常會依據膜的離子去除率與壓差判斷是否需要進行更換保養,與去除率相關的參數為逆滲透膜入、出水導電度,而壓差則是由入、出口壓力獲得;在本研究中,我們並非告訴機器既有的更換條件,而是將數據分為正常(0)、保養前五天(1)、保養當日(2),讓其自動去學習將相關數據進行分類,並分辨該筆數據是屬於哪種狀況(亦即分辨正常、保養前五天與保養當日)。另外在演算法的選用,因資料量偏少與資料變數較少的緣故,使用較常用的K-鄰近(KNN)演算法[16]、決策樹(Decision tress, DT)演算法[17]與循環神經網路(Recurrent neural network, RNN)[18]演算法做初步的比較。
由 表2中的六個組合建立模型,比較其預測之準確度。在機器學習中,模型的準確可由混淆矩陣(Confusion Matrix)來評定,選擇準確率高之適用模型後,再導入預測資料確認模型的可靠度與後續的分析。
|
標籤分兩類(0,1) |
標籤分三類(0,1,2) |
|
|---|---|---|
|
KNN演算法 |
模型1 |
模型2 |
|
DT演算法 |
模型3 |
模型4 |
|
RNN+LSTM演算法 |
模型5 |
模型6 |
由模型1的混淆矩陣來說明 表3,X方向為機器預測的結果筆數,Y方向代表實際上輸入的數據筆數,表格的判讀方式如下說明:當實際為「0」且預測為「0」,代表實際上為正常且預測結果同為正常,其資料數量為18653筆,預測準確率達99.2%,而實際為「0」且預測為「1」,代表實際上正常但預測錯誤的資料,數量為152筆;另一方面,在預測保養前五天的部分,實際為「1」且預測為「1」,代表成功預測需要保養的狀況,其準確率為52%,而實際為「1」且預測為「0」的部分,為需要保養但預測為正常的狀況,數量為315筆。最後,總和準確率則是表示模型1完全預測正確的比例,即(18653+342)/19462=0.976,故模型1的總和準確率為97.6%。
|
總和準確率:0.976 |
預測數據 |
|||
|---|---|---|---|---|
|
0 |
1 |
Total |
||
|
實際數據 |
0 |
18653 |
152 |
18805 |
|
1 |
315 |
342 |
657 |
|
|
Total |
18968 |
494 |
19462 |
|
|
總和準確率:0.962 |
預測數據 |
||||
|---|---|---|---|---|---|
|
0 |
1 |
2 |
Total |
||
|
實際數據 |
0 |
15757 |
152 |
20 |
15929 |
|
1 |
339 |
372 |
9 |
720 |
|
|
2 |
92 |
15 |
30 |
137 |
|
|
Total |
16188 |
539 |
59 |
16786 |
|
|
總和準確率:0.97 |
預測數據 |
|||
|---|---|---|---|---|
|
0 |
1 |
Total |
||
|
實際數據 |
0 |
18531 |
252 |
18783 |
|
1 |
329 |
350 |
679 |
|
|
Total |
18860 |
602 |
19462 |
|
|
總和準確率:0.95 |
預測數據 |
||||
|---|---|---|---|---|---|
|
0 |
1 |
2 |
Total |
||
|
實際數據 |
0 |
15633 |
246 |
82 |
15961 |
|
1 |
278 |
377 |
33 |
688 |
|
|
2 |
78 |
21 |
38 |
137 |
|
|
Total |
15989 |
644 |
153 |
16786 |
|
|
總和準確率:0.881 |
預測數據 |
|||
|---|---|---|---|---|
|
0 |
1 |
Total |
||
|
實際數據 |
0 |
16519 |
2231 |
18750 |
|
1 |
94 |
618 |
712 |
|
|
Total |
16613 |
2849 |
19462 |
|
|
總和準確率:0.838 |
預測數據 |
||||
|---|---|---|---|---|---|
|
0 |
1 |
2 |
Total |
||
|
實際數據 |
0 |
13533 |
2366 |
82 |
15981 |
|
1 |
140 |
495 |
33 |
668 |
|
|
2 |
21 |
64 |
52 |
137 |
|
|
Total |
13694 |
2925 |
167 |
16786 |
|
表3至 表8為模型 1到模型 6的預測結果與準確率,比較模型1與2,可看出標籤分類的方式對於準確率的影響,在模型2中,標籤分三類的準確率較差,原因可能為保養當日(2)的數據量較少,對於機器學習上樣本數不足,故在標籤分類的部分我們認為分成正常與更換前五天兩類較好。接著比較三種演算法之優劣,即比較模型1、3與5,由總和準確率來看KNN的方法較DT高(97.6%與97.0%),但同樣的在預測需要保養的時間準確率偏低,分別為52.1%與51.5%;相較之下模型5雖然總和準確率只有88.1%,但在預測需要更換的準確率為86.8%,相對高了很多。探究其中原因可能為:RNN演算法屬具有時序概念之演算方法[18],會將前一層計算完成的輸出,再回傳給該層作為輸入-換句話說當前的輸出不只受輸入影響,也受前一層計算的輸出影響,所以在處理數據之間有時序前後關係的案例,RNN演算法較能夠有正確的預測結果 圖9。回想逆滲透膜的運轉模式,其處理效率通常不只跟當下的水質有關聯,也有可能因為幾天前的水質異常,造成今天的處理效率變得不好,舉例來說,三天前的餘氯濃度偏低,造成當天的逆滲透膜壓差變高,即有可能是水質變化造成膜滋長細菌的結果。另一方面,KNN或決策樹的演算方法中,因其強項在數據的分類與變數權重分析上,探究造成判斷需要保養的狀況準確率僅有五成左右的原因:其一為演算法本身的特性在處理有時序關係的資料效果較差,其二是這兩種演算法會受資料標籤分類的影響較大,故當我們所投入的資料類型的數量差異較大時,可能導致在機器訓練上效果不彰,如 表3中,正常的資料佔全數96.6%,而需要保養的資料數量僅佔3.4%。
圖9、循環神經網路原理圖
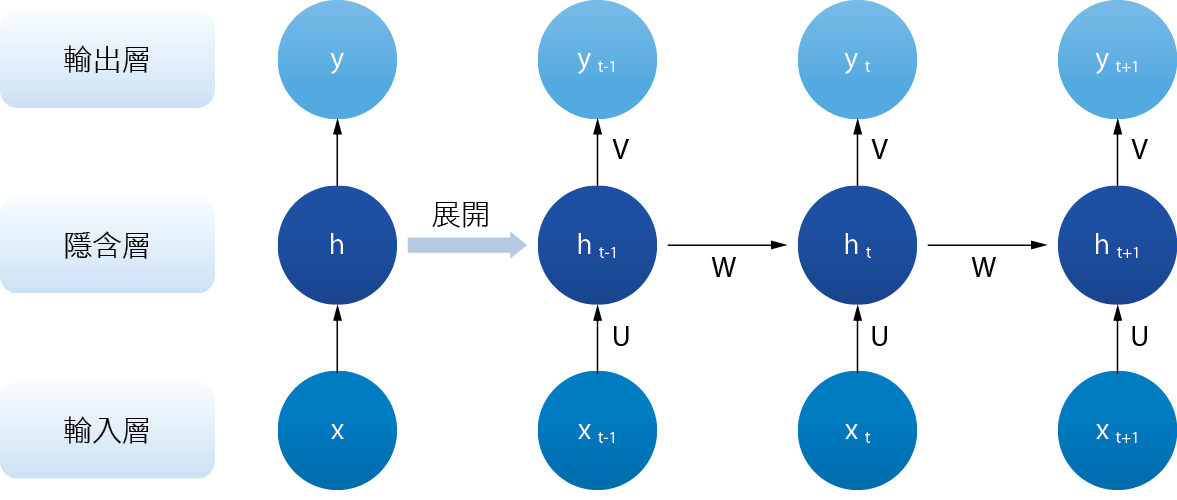 說明:xi 為輸入,yi 為輸出,hi 為預測值,U、V、W為權重向量
說明:xi 為輸入,yi 為輸出,hi 為預測值,U、V、W為權重向量綜合上述模型混淆矩陣的分析結果,模型1至6中較適用的為模型 5。在下一章會針對模型優化驗證與各種參數對逆滲透膜處理效率之影響權重做進一步的探討。
結果與分析
模型優化驗證─逆滲透膜更換保養案例
本研究選用模型5 (RNN+標籤分兩類)延伸做模型驗證,並且利用此模型繼續進行各參數的影響權重分析。導入2018上半年作為新的資料至模型中進行測試,結果如 表9混淆矩陣所示,總和準確率有90.6%,且在預測需要保養的狀況準確率已達87.6%。
|
總和準確率:0.906 |
預測數據 |
|||
|---|---|---|---|---|
|
0 |
1 |
Total |
||
|
實際數據 |
0 |
27560 |
2756 |
30316 |
|
1 |
403 |
2837 |
3240 |
|
|
Total |
27963 |
5593 |
33556 |
|
定為提早一週間預測需要更換的日期,舉例來說,利用1/1至1/7的運轉數據預測1/8是否需要更換,若1/8判定為需要更換保養,則會在1/1至1/7之間提出警訊告知工程師,以利保養更換逆滲透膜之準備作業-例如調撥備用膜或安排更換廠商人力。由2018上半年更換紀錄 表10與預測結果 表11的比對,本研究建立的模型有約87.5%的正確率,七套逆滲透膜系統共進行了48次更換保養,由模型預測需要保養的日期共64次,有6次實際上有執行保養的日期未被預測出來,故準確率為87.5% ,此外有16次預測模型認為需要保養但實際上我們未執行保養。探討這幾筆模型預測結果與實務上的差異,我們發現:6次未被預測出來的更換紀錄,實際上逆滲透膜A、E與G的處理效率尚在標準中,在記錄註解上為工程師決定提前施作的預防保養,故模型的判斷依然是符合設計需求的;而16次的誤報(實際為正常,但預測為需要保養的情況),有一半的狀況是誤動作,另一半為等待備用膜的時間較長所導致,例如 表11中,6/9以後的預測更換日期。綜合以上結果,以目前的預測模型作為提前預警,效果已算不錯,未來還能夠改進的部分為降低誤報的次數,與預測更換日期的準確率提升。
|
更換次數 |
更換日期 |
|||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
逆滲透膜#A |
7 |
1/15 |
2/21 |
3/20 |
4/11 |
4/25 |
5/11 |
5/23 |
||
|
逆滲透膜#B |
6 |
2/12 |
3/20 |
4/11 |
4/25 |
5/8 |
5/23 |
|||
|
逆滲透膜#C |
5 |
2/12 |
3/20 |
4/19 |
5/2 |
5/15 |
||||
|
逆滲透膜#D |
7 |
1/15 |
2/21 |
3/13 |
4/11 |
4/25 |
5/8 |
5/23 |
||
|
逆滲透膜#E |
7 |
1/15 |
2/21 |
3/20 |
4/19 |
5/2 |
5/18 |
6/1 |
||
|
逆滲透膜#F |
7 |
2/12 |
3/13 |
4/11 |
4/25 |
5/8 |
5/18 |
5/29 |
||
|
逆滲透膜#G |
9 |
1/15 |
2/21 |
3/13 |
4/18 |
4/25 |
5/2 |
5/15 |
5/18 |
6/6 |
|
Total |
48 |
淺監色表示模型未預測需保養,但實際有更換的日期 |
||||||||
|
逆滲透膜 |
預測需PM日期總數 |
日期 |
|||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
#A |
10 |
3/6 |
3/8 |
4/19 |
4/25 |
5/3 |
5/7 |
5/23 |
6/9 |
6/21 |
6/25 |
||
|
#B |
10 |
2/12 |
3/4 |
3/17 |
3/22 |
4/15 |
4/22 |
4/25 |
5/23 |
6/23 |
6/25 |
||
|
#C |
9 |
2/12 |
3/4 |
3/17 |
4/15 |
4/19 |
4/25 |
5/15 |
6/23 |
6/25 |
|||
|
#D |
10 |
1/10 |
2/21 |
3/4 |
3/13 |
3/26 |
4/11 |
4/23 |
4/25 |
5/8 |
5/23 |
||
|
#E |
7 |
3/18 |
4/24 |
5/6 |
5/13 |
5/18 |
6/1 |
6/8 |
|||||
|
#F |
12 |
1/7 |
2/12 |
3/4 |
3/13 |
4/11 |
4/14 |
4/21 |
4/24 |
4/25 |
5/2 |
5/8 |
5/29 |
|
#G |
6 |
1/7 |
3/20 |
4/25 |
5/2 |
6/9 |
6/21 |
||||||
|
Total |
64 |
設定7天為預測容許誤差,淺藍色底為正確預測更換的日期 |
|||||||||||
參數權重分析─逆滲透膜更換保養案例
在參數權重分析的部分,使用2017年整年的數據,比較30個參數對於逆滲透膜處理效率的影響權重,其中16筆數據來自SCADA,14筆數據為採樣實驗數據,結果如 表12所呈現,影響程度大小由上至下排列。與實際運轉狀況相似,逆滲透膜管入口壓、出口壓、膜管壓差、產水流量與離子去除率列居影響處理效率的前五名(重要性Importance 10000以上),另外,因LSR系統大多為氫氟酸廢水的提濃前處理系統,故Rank 7-產水氟離子濃度也是我們常用來判斷逆滲透膜效率的指標之一。
|
排名 |
數據標籤 |
數據敘述 |
數據來源 |
權重重要性* |
|---|---|---|---|---|
|
1 |
PIT_770_PV_2 |
產水壓力 |
SCADA |
12329 |
|
2 |
RO DP |
RO壓差 |
SCADA |
12024 |
|
3 |
FIQT_770_PV |
產水出口流量 |
SCADA |
10492 |
|
4 |
去除率 |
去除率 |
SCADA |
8979 |
|
5 |
PIT_770_PV_1 |
入口壓力 |
SCADA |
8873 |
|
6 |
PH_770A_PV_2 |
濃水出口pH |
SCADA |
4982 |
|
7 |
T-780 F |
產水氟離子濃度 |
採樣數據 |
4303 |
|
8 |
CIT_770_PV |
產水導電度 |
SCADA |
3730 |
|
9 |
T-740 F |
入口氟離子濃度 |
採樣數據 |
3627 |
|
10 |
PH_770A_1_PV |
產水出口pH |
SCADA |
3436 |
|
11 |
PDT_750A_PV |
前置濾心壓差 |
SCADA |
3425 |
|
12 |
CIT_740_PV |
入口導電度 |
SCADA |
2703 |
|
13 |
RO Outlet氨氮 |
產水氨氮濃度 |
採樣數據 |
2665 |
|
14 |
T-740氨氮 |
入口氨氮濃度 |
採樣數據 |
2567 |
|
15 |
T-740餘氯 |
入口餘氯濃度 |
採樣數據 |
1968 |
|
16 |
ROR F |
濃水氟離子濃度 |
採樣數據 |
1884 |
|
17 |
ROR NH3 |
濃水氨氮濃度 |
採樣數據 |
1872 |
|
18 |
FIQT_770A_PV |
濃水流量 |
SCADA |
1836 |
|
19 |
T-740硬度 |
入口硬度濃度 |
採樣數據 |
1577 |
|
20 |
T-780餘氯 |
產水餘氯濃度 |
採樣數據 |
1555 |
|
*權重重要性:為模型預測時使用到此參數的次數比例,作為參數的重要性指標 |
||||
透過這樣的參數權重分析,我們能夠瞭解到各個參數對逆滲透膜濾材處理效率的影響,並將影響程度數量化,如2017年的結果顯示了Rank 1~5是最重要的參數,其重要性指標都大於其餘25個參數2至10倍,所以我們能夠認定這五個參數為逆滲透膜保養的關鍵參數。再利用2018上半年的資料進行參數權重分析,也是獲得幾乎相同的結果 表13,雖然排序不太相同,但還是相同的五個關鍵參數影響著逆滲透膜的處理效率與是否需要更換保養。
|
排名 |
數據標籤 |
數據敘述 |
數據來源 |
權重重要性* |
|---|---|---|---|---|
|
1 |
RO DP |
RO壓差 |
SCADA |
14462 |
|
2 |
PIT_770_PV_1 |
入口壓力 |
SCADA |
12818 |
|
3 |
FIQT_770_PV |
產水出口流量 |
SCADA |
12945 |
|
4 |
去除率 |
去除率 |
SCADA |
8540 |
|
5 |
PIT_770_PV_2 |
產水壓力 |
SCADA |
8522 |
|
*權重重要性:為模型預測時使用到此參數的次數比例,作為參數的重要性指標 |
||||
透過這些機器學習的模型,可以達到即早期預知系統運轉處理效能,減少非預期性的維修保養發生。本研究的結果能達到提早一週提醒需要更換逆滲透膜管,並可透過水質資料權重分析,指出本次造成需要更換的原因,協助工程師判斷異常真因。
模型優化─轉動設備模型
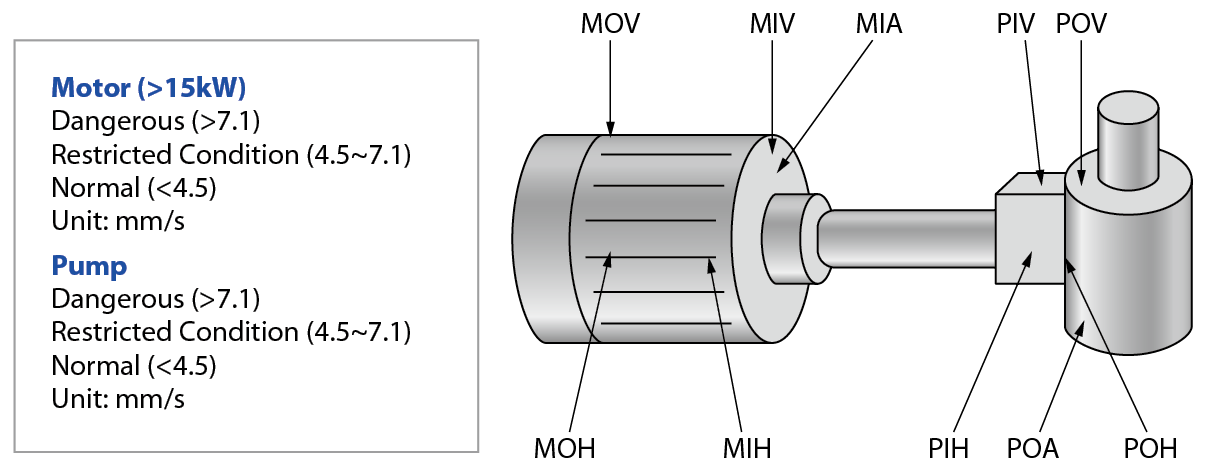
本研究另針對水處理系統中轉動設備-泵浦進行預知保養模型的建立,使用的數據為2016至2017年兩年間泵浦運轉電流(Amp)、運轉時數(R)、運轉頻率(Hz)、變頻器溫度(Temp)、電壓(DC_VOL)與振動量測值(MOV/ MIV/ MOH/ MOV…等共10個,如 圖10),期望以既有數據找出判定泵浦穩定度之參數。以目前對於水處理系統20~100HP泵浦的保養內容,定義振動值若大於4.5mm/s則判定振動有異常,但是振動值為半年一筆的量測數據,屬非連續式的監測數據,若半年間發生異常工程師無法提前知曉並做預防動作,故本研究希望能找到與振動值有相關性的SCADA參數或是能夠重新定義泵浦的預知保養指標,以達到減少泵浦非預期性故障之風險。
圖10、離心式泵浦振動量測位置與規範─以功率大於15kW為例
經本研究發現,若以現有的量測數據進行建模與數據分析,因泵浦異常故障的紀錄與振動量測值較少,無法建立準確度較高的預知保養模型,故改以著重於尋找能夠代表泵浦穩定運轉之綜合指標 (Health Index),研究結果如 圖11、12、13所示。將SCADA蒐集的資訊繪製成趨勢圖,並比對模型計算出之綜合指標趨勢圖,可以發現用綜合指標即能夠精準的呈現泵浦運轉的狀態是否正常:在綜合指標的趨勢圖中,若數值落在淺藍色塊區間內(Spec. <6),則判斷泵浦為正常狀態,綜合指標若大於6,則表示設備的運轉狀態已偏離平常的條件;舉例而言,在2016年1月底時,泵浦A、B與C的綜合指標大都落在6以上,原因是當時泵浦C所掛載之諧波抑制器內部電容故障進行更換,造成切換機次數頻繁所致,又如2017年2月中因泵浦B漏水需停機維修,綜合指標數值也呈現異常 圖12。
圖11、泵浦A運轉資訊趨勢圖(上)與綜合指標趨勢圖(下)
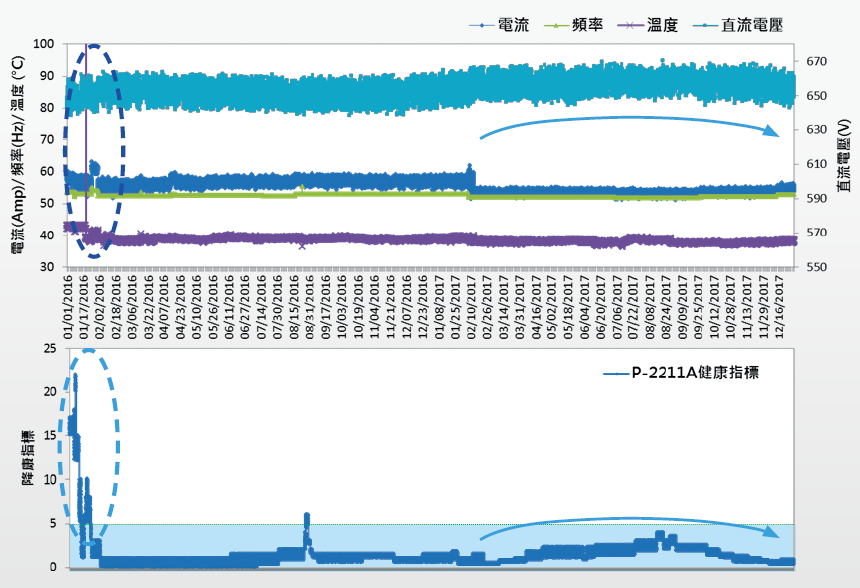
圖12、泵浦B運轉資訊趨勢圖(上)與綜合指標趨勢圖(下)
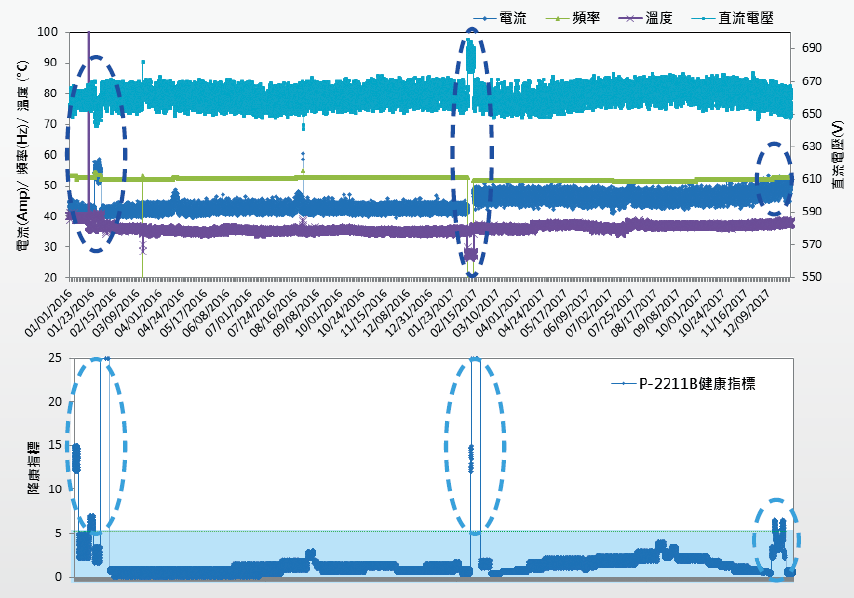
圖13、泵浦C運轉資訊趨勢圖(上)與綜合指標趨勢圖(下)
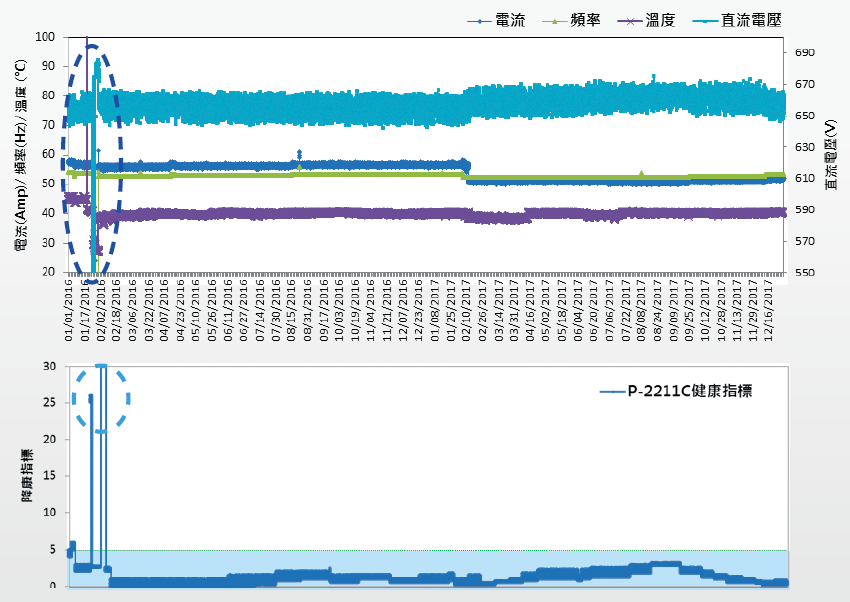
由這兩個事件皆可證明此模型所提供之綜合指標能夠作為代表泵浦運轉穩定度的參數,當泵浦運轉數值有些微趨勢性的變化或工程師切換機操作,綜合指標的數值都能夠及時反應出異常結果。以目前所建立的模型,雖然尚無法達到預知保養,但在未來加入更多泵浦發生異常的數據與量測數值,將模型可靠度提升與達到預知保養的目標是可預期的。
結論
透過本次研究建立出兩種模型,其一能預測水處理濾材逆滲透膜之處理效能與需要更換的時間點(準確率達87.5%),除了可減少非預期性的保養次數以外,透過各項水質參數權重分析,了解到每次發生非預期性保養或異常的主要原因,有效的指向真正問題所在,加速工程師的判斷與異常排除,朝預知保養與濾材處理效能最適化的目標,邁出了大大的一步。其二為找到轉動設備-泵浦的穩定度綜合指標(Health Index),使用了泵浦既有的SCADA的數據所建立的指標,當指標數值大於6時,顯示泵浦運轉狀態與條件發生變異,可提醒工程師即早確認設備狀態,在未來若可加入更多泵浦振動量測數值與異常狀況數據,提升模型準確率與達成預知保養的目標更是指日可待。
除此之外,預測模型的成功,同時也意味著本研究所整理之建立預知保養模型的標準化流程是可靠的,而 圖14是本研究建立逆滲透膜處理效能之預知保養模型流程示意圖,未來期望可將此標準化流程應用於更多廠務系統的預知保養,提升系統設備保養的品質與運轉可靠度,例如:透過冰機運轉參數預測保養時程,或以超純水系統的運轉水質分析預測樹脂、活性碳、UV燈等耗材的更換最佳時間。
圖14、建立預知保養模型之流程圖-以逆滲透膜處理效能與保養為例
除運用於預知保養之外,大數據分析也可應用於庫房管理或系統節能管理,例如:利用原物料使用量大數據分析去預測每日消耗量,並結合領料與叫料,進而達成庫存最適化管理;也可利用冰機運轉參數的大數據分析,去了解季節變換時外氣溫度的變化,進而調節冰水閥開度,以達節能效果。最後,綜合以上的應用可將各別的預測模型與公司內系統平台整合,自動連結資料輸入於預測模型,經模型計算分析後,把結果呈現於平台,完成廠務系統智慧管理平台。
參考文獻
- R. Keith Mobley, Chapter 1: Mainte-nance management methods, “An Introduction to Predictive Maintenance”, 2nd Edition, Butterworth-Heinemann published, pp.1-433, 2002.
- 劉于偉、陳獻耘,大數據在水資源管理中的應用展望,水資源研究,Vol. 4, No. 5, pp. 470-476, 2015.
- Viktor Mayer-Schonberger and Kenneth Cukier, “Big data: A revolution that will transform how we live, work, and think.” Mariner Books Published, 2014.
- Nagdev Amruthnath and Tarun Gupta, “A Research Study on Unsupervised Machine Learning Algorithms for Early Fault Detection in Predictive Mainte-nance.” 5th International Conference on Industrial Engineering and Applications, pp. 355-361, 2018.
- M. Lebold and M. Thurston, “Open standards for Condition-Based Mainte-nance and Prognostic System”. 5th Annual Maintenance and Reliability Conference MARCON, Gatlinburg USA, 2001.
- A. M. Turing, “Computing machinery and intelligence”. Mind, Vol. 49, No. 236, pp. 433-460, 1950.
- A. Beghi, R. Brignoli, L. Cecchinato, G. Menegazzo, M. Rampazzo, F. Simmini, “Data-driven Fault Detection and Diag-nosis for HVAC water chillers”, Control Engineering Practice, Vol. 53, pp. 79-91, 2016.
- Marko Kolanovic and Rajesh T. Krish-namachari, “Big Data and AI Strategies-Machine Learning and Alternative Data Approach to Investing”, Global Quantitative & Derivatives Strategy, pp. 16-29, 2017.
- 陳胤凱與楊維邦,一個以決策樹為基礎的三階段監督式學習垃圾郵件過濾架構,臺灣碩博士論文系統,2009.
- Gian Antonio Susto, Andrea Schirru, Simone Pampuri, Sean McLoone, Alessandro Beghi, “Machine Learning for Predictive Maintenance: a Multiple Classifier Approach”, IEEE Transactions on Industrial Informatics, Vol. 11, No. 3, pp. 812-820, 2015.
- Djamel Ghernaout, Mohamed Aichouni, and Abdulaziz Alghamdi, “Apply big data in water treatment industry: A new era of advance,” International Journal of Advanced and Applied Sciences, Vol.5, No. 3, pp. 89-97, 2018.
- Water Online, Understanding Big Data In the Water Industry, http://www.wateronline.com/doc/understanding-big-data-in-the-water-industry-0002
- 經濟部水利署,氣候變遷挑戰─永續水資源治理論壇,https://www.wranb.gov.tw/public/Data/842315382171.pdf
- 蔡有藤、陳宗傑與廖哲賢,機械系統性能衰退預測與故障診斷之研究,Journal of Technology, Vol. 27, No. 3, pp. 121-129, 2012.
- Kemira Company, Big Data applications and advances for the water treatment industry. https://www.kemira.com/company/media/newsroom/news/big-data-applications-and-advances-for-the-water-treatment-industry
- G. Guo, H. Wang, D. Bell, Y. Bi, K. Greer, “KNN -Based Approach in Classification.” In: Meersman R., Tari Z., Schmidt D.C. (eds) “On The Move to Meaningful Internet Systems 2003: CoopIS, DOA, and ODBASE. OTM 2003”. Lecture Notes in Computer Science, Vol. 2888, pp. 986-996, 2003.
- J.R. Quinlan, Introduction of Decision Trees, “Machine Learning”, Vol. 1, Kluwer Academic Published, Boston, 1986.
- Sepp Hochreiter and Jiirgen Schmid-huber, “Long Short-term Memory”, Natural Computation, Vol. 9, No. 8, pp.1735-1780, 1997.
留言(0)