摘要

人工智慧應用於冰水系統節能技術探討
Keywords / Artificial Intelligence11,Chiller3,Energy Saving Of Chilled Water System2,Optimization3,Automatically Change The Temperature Control


台積電運用人工智慧和大數據分析將製程最佳化,應用此精神追求冰水系統效能最佳化。2017年應用大數據分析及結合冰水系統找到全系統最佳效能運轉機制,成功開發業界第一個冰水系統最佳化節能控制系統(正負2度C),但因機台管路老化等因素,使得理論與實際運轉存在差異誤差。2018年運用了AI-ML(人工智慧-機器學習)的技術,以大量歷史資料透過類神經網路的結構和功能所產生的數學模型,藉由不斷學習來修正並精進既有正負2度C以理論為基礎的冰水系統最佳化模型,精確且即時的預測目前的耗能狀態,並且可以快速得到一組最佳的節能溫度設定值輸出給系統,將理論與實際差距最小化,整體能源效率再提升。此AI節能控制程式推行至12吋晶圓廠共15座廠執行,節能效益與2017年正負2度C冰水系統最佳化節能控制系統相較,成功再提升1.9%,每年節省3,400萬度用電量。
前言
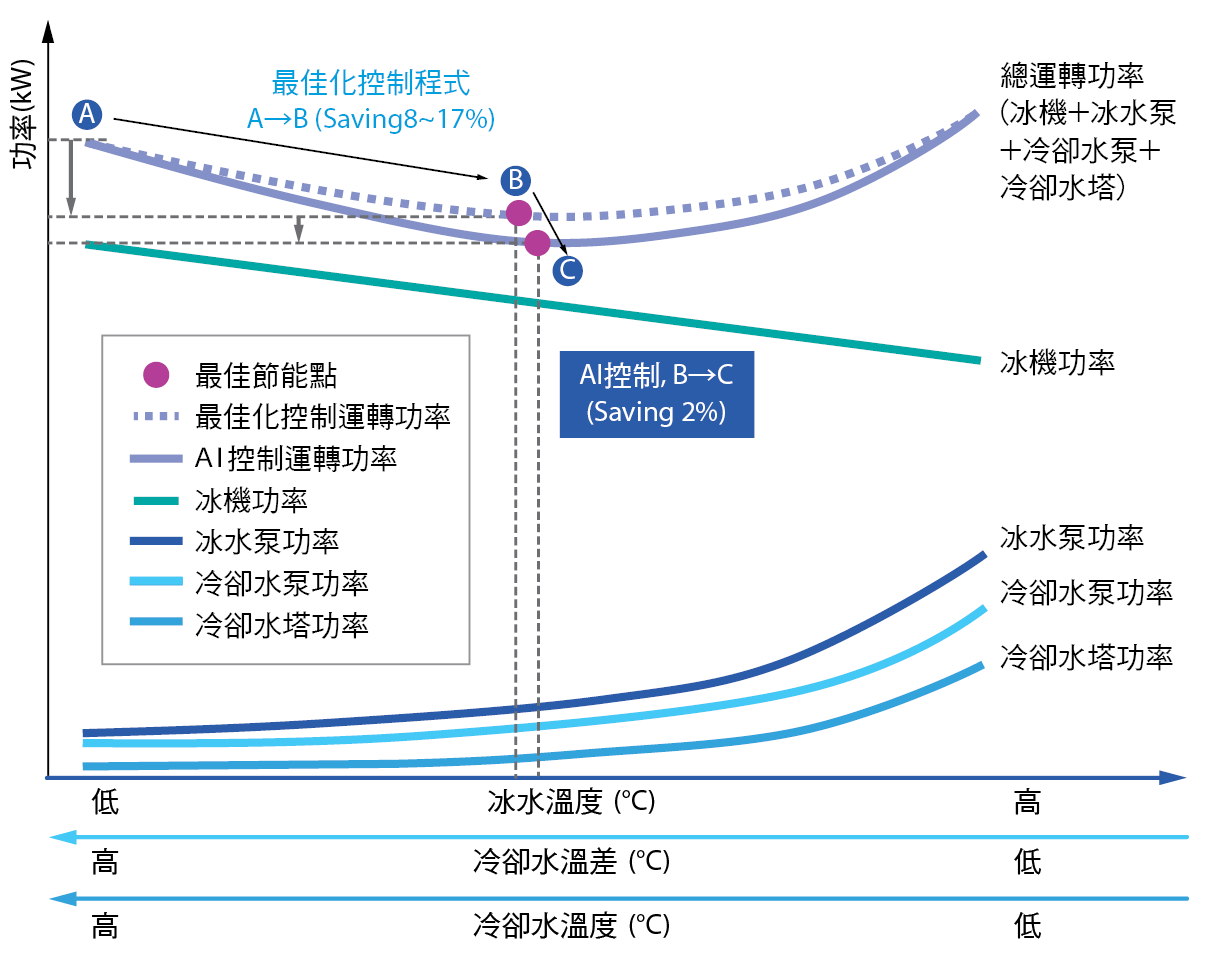
半導體廠利用冰水系統將運作中的工廠降溫,相對地,系統能源效率管理卻已是現今半導體廠最艱難的挑戰之一。在同樣的情況下,不斷增加的能源成本使台積電公司面臨著提高運營效率的壓力之外更需要承擔更多的社會責任。根據“台積電能耗報表系統”,冰水系統用電量佔整廠區的20%~25%,除了去年我們成功開發冰水系統最佳化節能控制系統(正負2℃),節省了8~17%的冰水系統能耗,但由於正負2℃是運用冰機、泵浦及冷卻水塔之性能曲線推導出變溫時各設備相互間之能耗方程式,因此無法反應出設備之實際狀況,在節能上相信還有空間;所以本研究將尋求新技術的方法來深入探討更多的節能機會。
冰水系統的溫度改變與基礎設備(冰機、冷卻水塔、熱回收、泵等)的負載變化呈現出非線性的複雜相關性,外氣條件也會影響冰水系統的耗電效率,如此高維度與複雜度的系統,以傳統理論公式的預測建模(如正負2℃)通常難以捕獲這種複雜的相互依賴性,且於實際運轉與理論有著不可避免的差異因素存在,如運轉時間久造成效率變差、管路結垢摩擦損失變大…等。為了解決這些挑戰,我們嘗試著運用大數據分析-人工智慧(Artificial Intelligence, AI)的方法,以實際運轉數據中分析找出與理論之差異性。在人工智慧眾多的演算法中我們採用了機械學習(Machine Learning, ML)演算法可較符合解決目前的問題,因為機械學習演算法擁有自我學習的優勢,是一類從運轉資料Big Data中自動分析獲得規律,並利用此規律對未來資料進行預測的演算法,訓練出來的AI模型可將系統因運轉時間久而造成效率的改變,做即時調整及修正,期望能將理論與實際差距最小化,而獲得更多之節能效益。
文獻探討
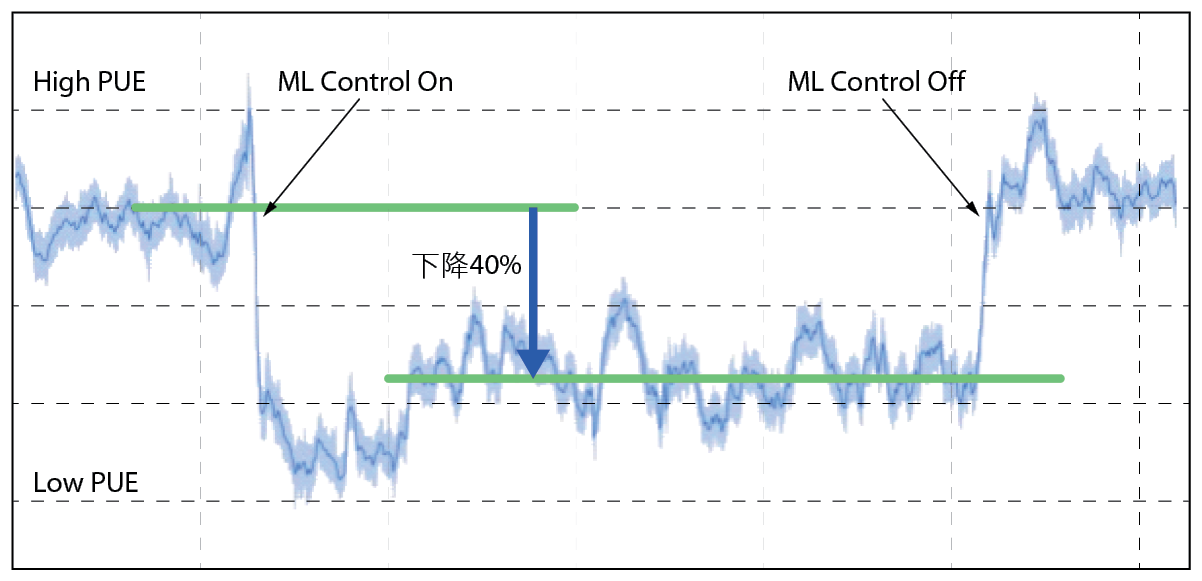
冰水系統主要吸取從工廠設備及其周圍環境中排出的熱量,以降低設備和環境溫度。因為冰水系統耗電量大,以往不論先進科技業或傳統產業,都是利用精進冰水系統技術或優化冰水系統設備運作效率達節能目的,往年這樣的冰水系統技術改進確實使互聯網公司(例如:google)提高資料運轉設備的用電效率,但近年來由於改進的速度趨於緩慢,為確保服務全球的龐大伺服器和計算資源網路必須保持最佳的運轉條件,Google決定不再定期投資新的冷卻技術來增加收益,首先提出採用人工智慧(AI)來有效管理其數據中心基礎設施的冷卻操作,該公司在2017年導入機器學習(ML)的類神經(Neural Network, NN)演算法,發展了一套智能系統來有效管理其數據中心基礎設施的冰水系統操作[1,2,3,4,5,6],這套智能冰水系統,不只是有效降溫了伺服器運作和網路傳輸過熱問題,更進一步將冰水系統的耗能達最小化。在Google某座資料中心導入AI之冰水系統前後PUE(Power Usage Efficient)減少40% 圖1,此PUE值是用來計算資料中心節能省電的標準,計算方式是以「資料中心的總用電量」除以「資料中心內IT設備的總用電量」,PUE值越低代表機房在環境監控、空調冷卻、燈光等周邊設備的用電量更少。
圖1、Google某座資料中心導入AI-ML之冰水系統前後的PUE
Google運用AI-ML並選擇類神經網路演算法[7,8,9,10,11,12,13],其主要原因為:
- 能快速學習和建立復雜關係中非線性的能力,因為在現實生活中,輸入和輸出之間的許多關係都是複雜的非線性關係。
- 模型學習之後,它可以推斷出數據上看不見的關係,從而使模型能夠預測看不見的數據。
- 與許多其他預測技術不同,類神經網路不需對輸入變量施加任何限制(例如它們規定應如何分配),編寫自由度高。
同時間,我們得知台積公司廠務冰水系統不僅擁有比google更大量的sensor資訊,其冰水系統能耗更甚於google許多,另外在冰水系統架構與google系統架構兩者相似度高,非常適合將此智能方法導入現行運轉於冰水系統的正負2℃模型,做進一步的能耗優化,所以在2018年初廠務與MTC合作,運用這方面相關技術並朝此方向研究。
計畫方法
整體來說,我們使用的機器學型模型是深度學習中常見的類神經網路演算法。類神經網路演算法中,輸入值和輸出值的定義是最初始的重點,台積公司和冰水系統相關的傳感器參數(sensor tag)將近1000個,但並不是每一個參數都和耗能相關,首先,我們利用機器學習常用的feature selection篩選出第一波和耗能相關近300個參數,其次,透過廠務冰水系統專家的經驗和專業,再精確篩選出近100個重要參數當成神經網路的輸入值。數據集收集每15分鐘一組,範圍共13個月且按時間順序排列共有3.79M筆數據,將數據分為訓練群和測試群兩群,訓練群包含總數據集的80%、剩餘20%是為測試群。訓練期間數據集並非原始資料,而是必須經過縮放(scaling)處理,因為我們所選取重要參數的大小、單位、範圍有相當大的不同,假如不管它們,這機器學習模型只會考慮參數的『值』而忽略『單位』,結果在不同單位之間會有很大差異,例如5kg和5000gms是同樣的重量,但因為單位不同而有1000倍的差異。為了預防這樣的變異性在訓練過程中造成影響,則我們需要將所有參數帶到相同的大小,這可以通過縮放來完成。通常有四種執行中縮放的方法,分別為標準化法(standardization)、均值歸一化法(mean normalization)、極小極大縮放法(min-max scaling)、單位向量法(unit vector),本文採用的方法是極小極大縮放法。
機器學習包含監督學習,非監督學習,深度學習和加強學習等,其中所涵括的演算法種類不勝枚舉,在此就我們所使用的深度學習之類神經網路演算法加以說明。TensorFlow是處理數值運算和大規模機器學習的開放式程式庫,目前是深度學習和神經網絡計算框架的指標,通常透過Python控制。TensorFlow是藉由利用圖形和圖形的運作來呈現運算過程,使用者可以將數據、變數、運算符號指定為特定圖形元素後做運算,且由於神經網絡實際上是數據和數學的圖形運算,因此TensorFlow非常適合神經網路和深度學習,以下舉一簡單的例子說明 圖2。
圖2、Tensorflow 基本架構圖
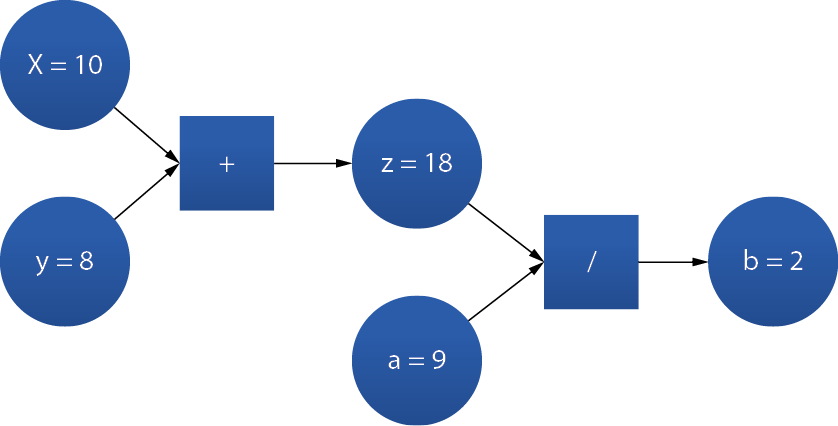
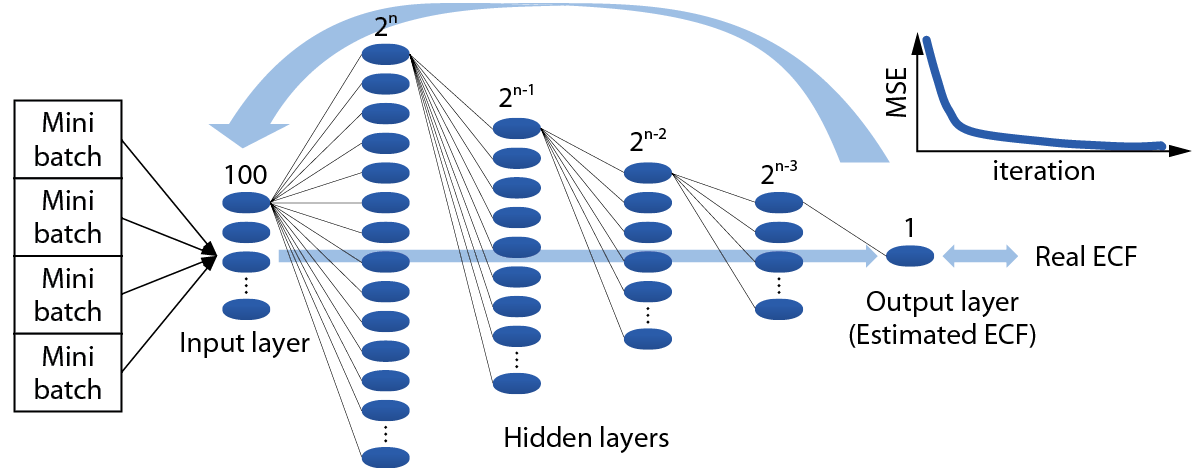
我們建構的深度學習類-反向傳播訓練神經網路模型架構中 圖3,將冰水系統耗能相關參數(壓縮機、水泵、水塔、熱回收、冷凍噸、外氣條件)視為輸入神經元組,總耗電量視為輸出神經元。中間層由數個隱藏層組成,定義輸入層、隱藏層和輸出層之間所需的變量維度很重要,這影響著資料在訓練期間傳遞的順暢性,以經驗法則,第一層包含2n個神經元,略大於輸入參數的兩倍,後續的隱藏層取決於前一層的一半大小,簡單地說,就是每個層將其輸出作為輸入傳遞給下一層。並且,在神經網路結構中,每一個耗能相關參數的權重(weights)和整體偏差變量(biases),初始由默認值定義之。
圖3、類神經網路結構圖
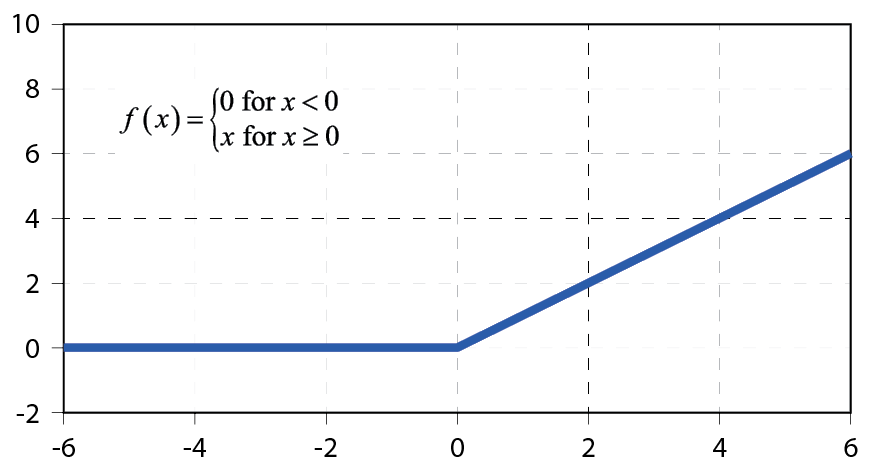
此外,我們也引入了網路體系結構的重要元素─激活函數(activation function),在類神經網路中如果不使用激活函數,那麼在類神經網路中皆是以上層輸入的『線性』組合作為這一層的輸出(也就是矩陣相乘),則輸出和輸入就脫離不了線性關係,如此做深度類神經網路便失去意義。因為隱藏層中層與層的各個層面是透過激活函數轉換,其功能是為系統帶來非線性,常見的激勵函數選擇有sigmoid, tanh, Relu,本文使用的是深度學習的主流Relu 圖4,主要是為了舒緩過度擬合(overfitting)和節省計算量兩個主要因素(對使用反向傳播訓練的類神經網絡來說,梯度的問題是最重要的,使用sigmoid和tanh函數容易發生梯度消失問題,是類神經網路加深時主要的訓練障礙)。
圖4、Relu函數
最後,我們要引入網路成本函數(cost function),在機器學習中,成本函數用於估計模型的執行情況,簡而言之,成本函數衡量模型在評估和y之間關係的能力方面有多好或多差,目的為度量預測值與實際觀察值之間的偏差量。常見的的函數是均方誤差(MSE)函數,表示如下列方程式:其中n是樣品總數、Y是實際觀察值、y是度量預測值。
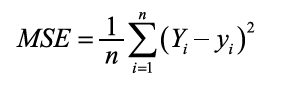
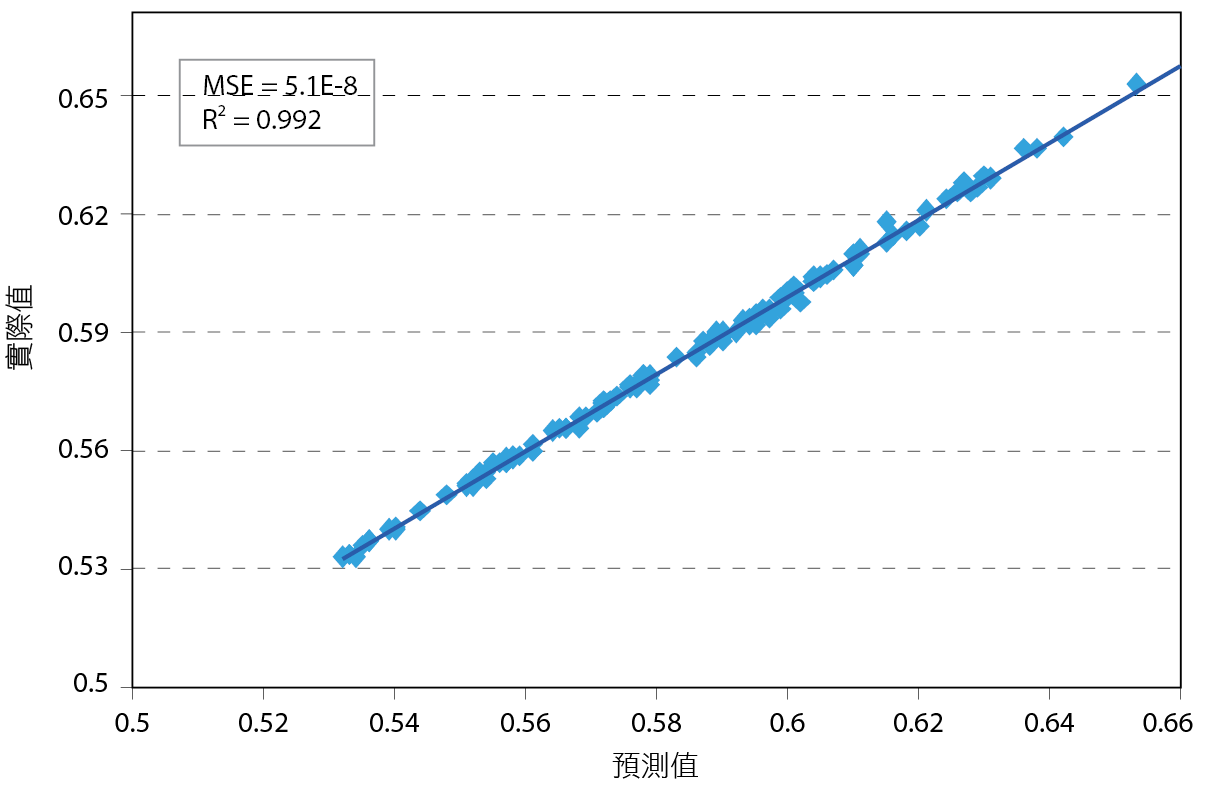
對模型進行訓練期間多採用小批量(Mini batch)規模培訓,每一個小批都是由訓練群中亂數選取後分批送進網路系統,由第一批的MSE得出相對應的權重和偏差變量,然後將其作為輸入提供給下一批的初始值,直到所有訓練群分送完畢後並重複該過程,當輸出達到收斂時訓練終止,或者當達到設定的epoch後停止。 圖5顯示ECF之預測值和實際測試值在相同時間下幾乎兩兩相疊,若將其量化比較,一般來說預測模型R2>0.9就算精確模型, 圖6指出MSE=(5.1E-8)和R2=(0.992),其精準度遠高於0.9,表示此模型成功訓練完成。利用這個已訓練完成的模型,我們將能預測在當下系統溫度(冰水出水溫度、冷卻水出水溫度、冷卻水溫差)微小變化範圍中的最低耗能溫度組,再將此溫度組回饋給冰水系統作為節能溫度設定。
圖5、預測值與實際值在相同時間下比較之ECF
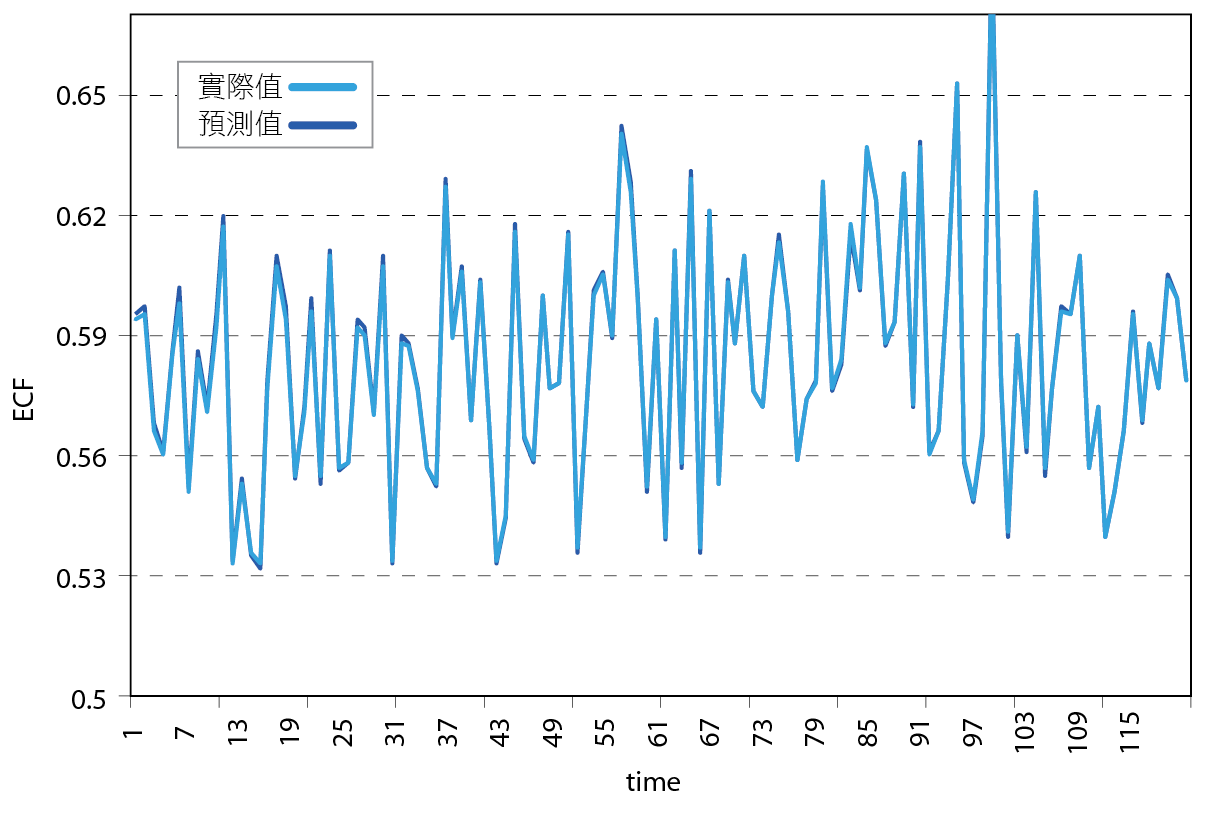
圖6、ECF在預測值與實際值比較之MSE及R2
結果與分析
如前言所提,正負2℃在2017年開發後成功地所獲得將近10%的節能效益,隔年發展出AI-ML機器學習模型,進一步考量了冰水系統因運轉時間久造成效率變差、管路結垢摩擦損失等無可避免因素,同年7月在F12P6開始上線測試。
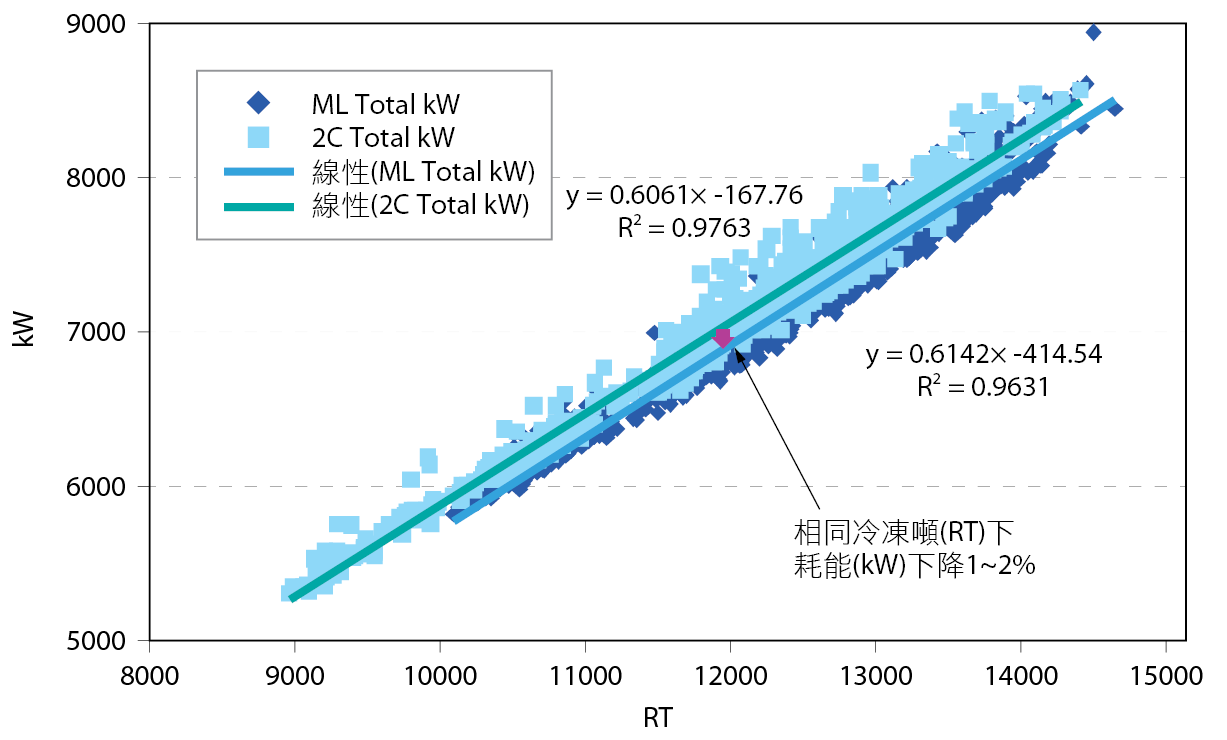
驗證方式:採用ASHRAE(美國冷凍空調工程師學會)國際節能量測認證手法[14],改善前後冰水系統性能係數(kW/RT,單位冷凍噸之耗電量)之差異;即收集機器學習模型上線前後約2個星期資料(耗電量kW vs.冷凍噸RT),並且確認兩時間區段的冰水系統條件相同(如:開機台數、開機編號不變和外氣焓值相差不大者),進行改善前後冷凍噸與耗電量做線性回歸(R2大於0.9),在相同冷凍噸需求下機器學習前(深藍色點)後(淺藍色點)的耗能下降1至2% 圖7。
圖7、AI-ML上線測試前後線性回歸(kW vs. RT)
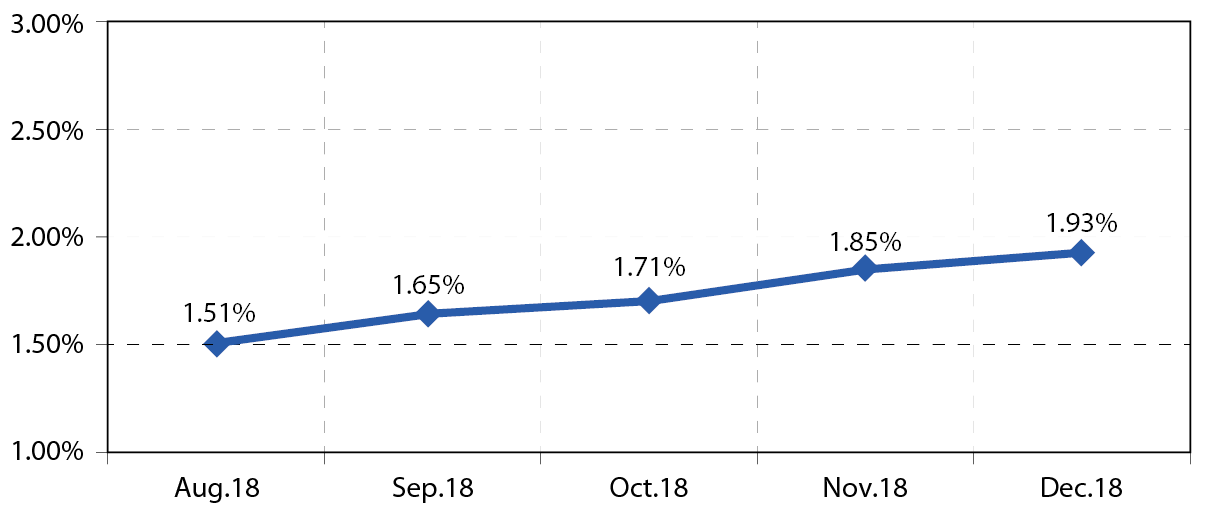
機器學習導入的初期(2018年8月)其節能效益比原控制之正負2℃可再往上提高了1.51%。此外重要的一點,機器學習的另一個優勢是建立好的模型本身有自我學習(self-retraining)的功能,此自我學習以每2週更新一次,隨著時間的演化,模型不斷在學習冰水系統的最佳狀態,而後自動調整參數 圖8,可清楚地看到機器學習模型在上線五個月後,節能效益由原本的1.51%緩慢的上升到1.93%。此模型自我學習成效曲線預計會在模型達到全域性地最佳化後趨於平緩。
圖8、機器學習模型的自我學習成效曲線
實際執行效益
此AI節能控制程式預計推行至十二吋晶圓廠 (共計15廠)執行,2018年5月至今已完成11個廠區導入,9個廠區已完成效益驗證,與2017年正負2℃冰水系統最佳化節能控制系統相較,其節能效益平均提升1.9% 圖9,15個廠實際節省用電量一年3.4M度。
圖9、AI-ML與正負2度C相較節能效益再提升1.9%
結論
2017年開發業界首創正負2℃冰水系統最佳化節能控制程式[1],12吋晶圓廠(共15廠)執行完畢,冰水系統用電量平均可節能9%(相當於全廠用電量1.8%),每年可實際節省用電量1.2億度。
因正負2℃主要以理論為基礎開發出控制程式,但於實際運轉與理論有著不可避免的差異因素存在,如運轉時間久造成效率變差、管路結垢摩擦損失變大…等;雖然程式有針對理論與實際之差異以人為判斷作修正,但是否真正符合實際運轉數據當時並無有效方法證明。
有鑒於此,本次研究於2018年與MTC (製造技術中心)合作,MTC運用AI-ML (人工智慧-機器學習)方式,以正負2℃之冰水系統總耗能方程式模型當基礎,並運用過往實際運轉(Big data)共3.79M筆數據,利用類神經演算法自動學習並修正此耗能模型,求得實際最低耗電量時之溫度設定值。
各廠導入後經由驗證,其平均節能效益1.9%,15個廠實際節省用電量一年3.4M度,證明了AI-ML之可行性與節能效果。
參考文獻
- 莊哲嘉,正負2°C–冰水系統最佳化控制創新方法,300mm FABs Facility Jour-nal(廠務季刊),Vol. 30, JUNE 2018.
- James W. Furlong & Frank T. Morrison. Optimization of Water–Cooled Chiller–Cooling Tower Combinations CTI Journal, Vol. 26 No. 1 2016.
- Retrieved from https://www.google.com/about/datacenters/efficiency/internal/.
- Jim Gao. Machine Learning Appli-cations for Data Center Optimization. 2017.
- Google’s Green Data Centers: Network POP Case Study. 2011.
- Jonathan Koomey. Growth in Data center electricity use 2005 to 2010. Analytics Press, Oakland, CA, 2011.
- Retrieved from https://machinelearning mastery.com/.
- Andrew Ng. “Regularization (Week 3).” Machine Learning. Retrieved from https://class.coursera.org/ml2012002.
- Andrew Ng. “Regularization (Week 3).” Machine Learning. Retrieved from https://class.coursera.org/ml2012002. 2012. Lecture.
- Andrew Ng. “Neural Networks: Repre-sentation (Week 4).” Machine Learning. Retrieved from https://class.coursera.org/ml2012002. 2012. Lecture.
- D. Kingma, J. Ba, Adam: a method for stochastic optimization, International conference on learning representations arXiv:1412.6980 (2014).
- Theano Development Team, Theano: a Python framework for fast computation of mathematical expressions, arXiv:1605.02688 (2016).
- P. Bashivan, I. Rish, M. Yeasin, N. Codella, Learning Representations from EEG with Deep Recurrent-Convolutional Neural Networks. International conference on learning representations (2016).
- ASHRAE’s GUIDELINE 14-2002 FOR MEASUREMENT OF ENERGY AND DEMAND SAVINGS.
留言(0)