摘要

廠務監控健檢雛形系統

為了提昇部門與人員整體運轉效率,過去各廠皆投入了不少心力進行電子化系統的建置,也因此維持電子化系統正常的執行成為日常運轉重要的任務之一。然廠務電子化系統應用程式的數量不在少數,為了改善用戶反應異常才進行故障排除的窘境,因此我們透過人工定時點檢的方式來確認各系統的執行狀況,不但耗費時間也沒有效率。本文的目的即在於介紹進行實驗中的FMCS Watch Dog健檢雛形系統,將應用程式的執行狀況轉換為心電圖即時線上偵測的模式,在預期或判斷異常的時候立即通報管理人員進行問題的排除以減少用戶的抱怨,並針對異常的原因進行分析與改善,避免問題再度發生,提昇用戶整體滿意度。
前言
為了提昇部門與人員整體運轉效率,過去各廠皆投入不少心力進行電子化系統的建置,也因此維持電子化系統正常的執行成為日常運轉重要的任務之一。雖然我們對應用程式設計階段的處理程序有基本的了解,但對於應用程式執行階段各個步驟的執行狀況卻如同黑盒子般所知不多,因此只能夠使用人工的方式進行日常健檢,透過程式執行的最終結果,例如統計報表來判斷系統是否持續正常運轉。
以中科廠務為例,統計單一廠區各電子化系統應用程式的數量約有50個,每天投入電子化系統檢查的人力估計約需三個小時,這樣的方式不但耗費時間,且人為的判斷還是存在著盲點,加上點檢的頻率根本無法滿足系統持續二十四小時運轉的需求,因此我們通常是在接到用戶端的報案才發現異常的狀況,而無法在第一時間進行問題排除,導致要花費更多的時間來進行資料的回補。為了改善這樣的困境,我們嘗試打開應用程式的黑盒子並開始進行實驗性系統的測試,將應用程式的每個執行步驟的執行時間與相關資訊加以記錄,就如同將應用程式連接上了心電圖診斷器般,再進行全自動二十四小時不間斷地監控各應用程式的心電圖健康狀況,以在第一時間快速通報管理人員進行問題的防堵,避免異常持續擴大。
健檢手法發想
電子化系統是由數個或多個應用程式協同運作組合而成,應用程式會收集各資料來源例如監控系統或人員輸入的資料進行運算,並將計算結果接力傳送給下一個應用程式進一步處理,最後將運算結果以統計報表的方式呈現給使用人員進行分析與應用。這樣的運作方式就如同工廠生產的過程一樣,從原物料輸出半成品到下一個工作站進一步加工直到成品的產出,如 圖1。
圖1、應用程式間交互運作流程示意圖

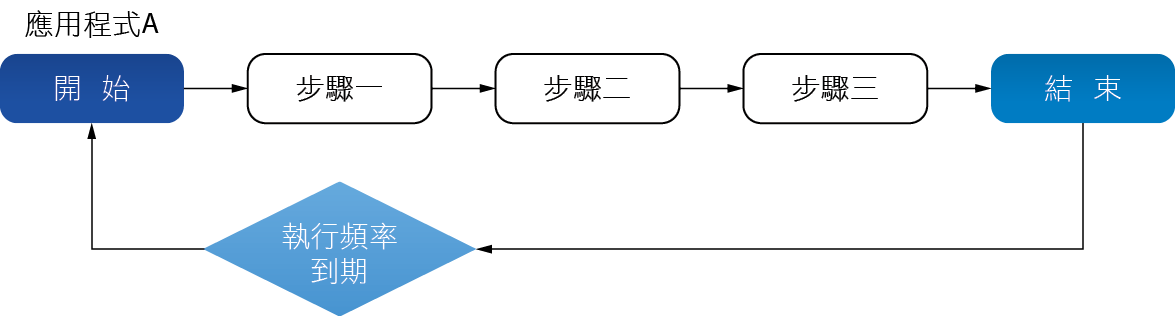
而每一個應用程式則是由許多的執行步驟組合而成,通常我們會設定應用程式的執行頻率,例如每小時或每隔一天,當時間到達的時候,應用程式便會啟動,並且依照順序逐步執行各個步驟直到結束,並等待下一次時間到達再重新啟動執行,應用程式執行步驟示意圖如 圖2。但針對每一個應用程式而言,雖然我們可以透過設計文件中的流程圖了解其處理步驟與程序,但對於每個執行步驟的執行狀況是否正常卻如同黑盒子般沒法掌握。
圖2、應用程式執行步驟示意圖
當應用程式發生異常的時候,程式人員通常會在程式碼中埋入除錯的程式,將執行步驟、執行時間以及相關的資訊輸出到記錄檔中,然後打開記錄檔逐步檢視與推斷可能的問題所在。但為何要等到發生異常再加入除錯程式?就如現在廣泛應用的健康手環等各類感應器隨時量測著相關的訊號,如果我們將每個執行步驟的執行時間等相關資訊都記錄下來並儲存到資料庫,我們就可以隨時監視應用程式的執行狀況是否正常,就如同在各個應用程式裝上了心電圖般隨時量測著心跳的狀況。
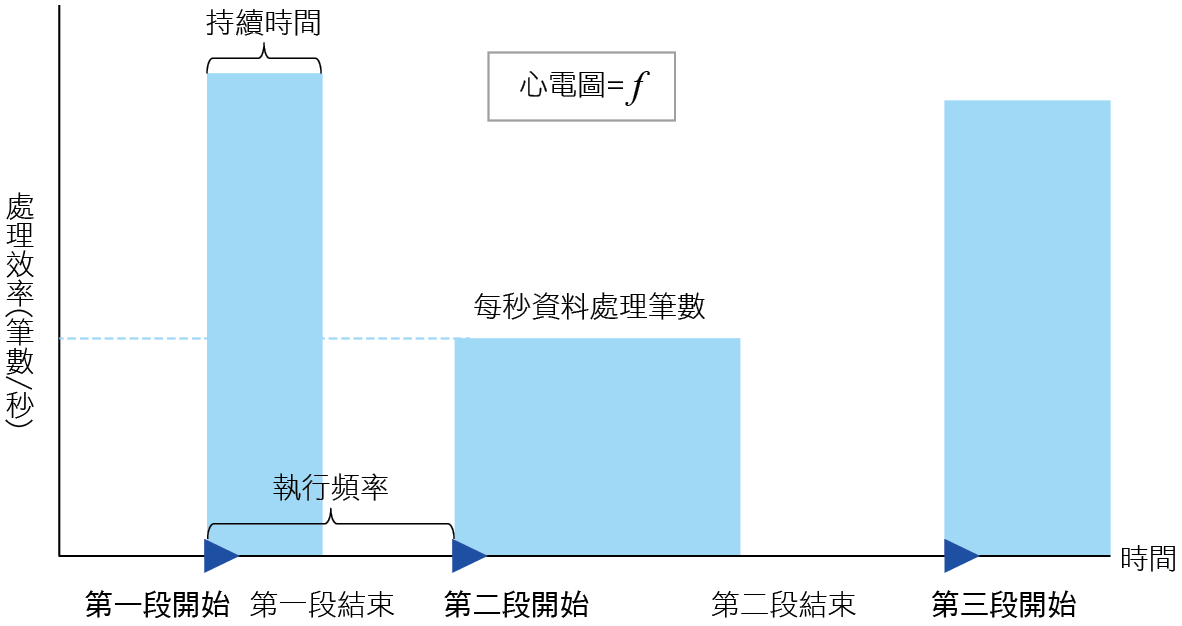
我們以 圖3中某應用程式執行步驟的時序圖來說明這個概念,在水平軸上我們標註該執行步驟啟動的時間與結束的時間,然後以開始到結束時間平均每秒鐘資料處理的筆數為垂直軸,就可以畫出每個應用程式的執行時序函數圖,我們可以將它比擬為心電圖。如果應用程式的心電圖前後有不一致或變異的狀況,就代表應用程式的執行可能已經出現了問題。
圖3、應用程式心電圖函數示意圖
健檢系統設計與建置
心電圖判讀手法聽起來可行,但應用程式數量不少,若要每一個應用程式都加入自己的健康診斷機制,不但耗費資源,而且每家廠商的做法可能都不相同,這將造成後續管理上的困難。
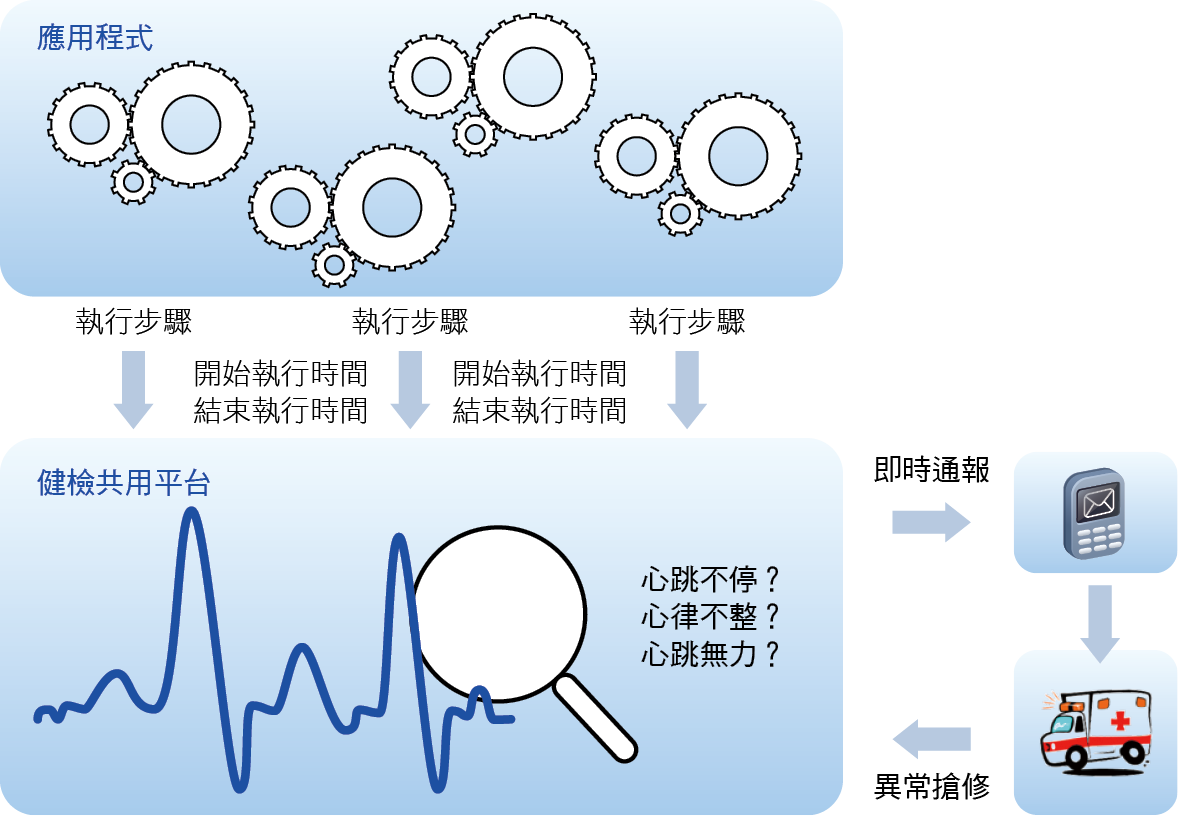
因此我們的做法是採用共用平台的模式建置單一的健檢系統,並提供簡單的整合介面給所有應用程式,如 圖4中所示的應用程式與健檢系統整合示意圖。而且這些整合介面包含有容錯的設計,即使呼叫失敗也會維持各個應用程式原本的運作與效能。當應用程式呼叫了整合介面後,即可快速與健檢系統完成無縫的接軌,健檢系統會收到應用程式各個執行步驟的訊息,並全面接手後續大數據心電圖的記錄、判讀與異常通報的工作,免除了應用程式自行加入診斷機制的負擔,大幅降低了管理複雜度並提昇整合程度。
圖4、應用程式與健檢系統整合設計
依據心電圖健檢系統的理念,中科廠務開始進行健檢雛型系統的開發與建置,為了加速驗證的速度,我們選取了自行開發的應用程式,並依據重要性的先後順序,優先挑選5大系統的11個應用程式,共計78個處理步驟進行第一階段的整合作業,下面我們以健檢系統的各個操作畫面來說明健檢雛型系統的整合結果。
圖5為納入健檢系統管理的應用程式與執行步驟清單,應用程式只要呼叫共用整合介面,系統就會自動收集並更新各應用程式最即時的相關資訊,包含所有執行步驟名稱以及應用程式所在伺服器位置、執行檔案路徑以及資料庫連結等資訊,這對我們掌握所有應用程式的實體佈署狀況以及異常排除非常有幫助。
圖5、健檢系統應用程式清單
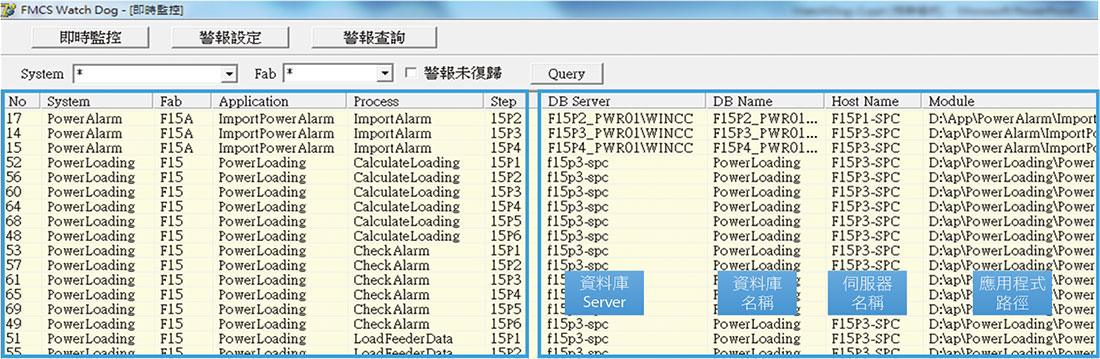
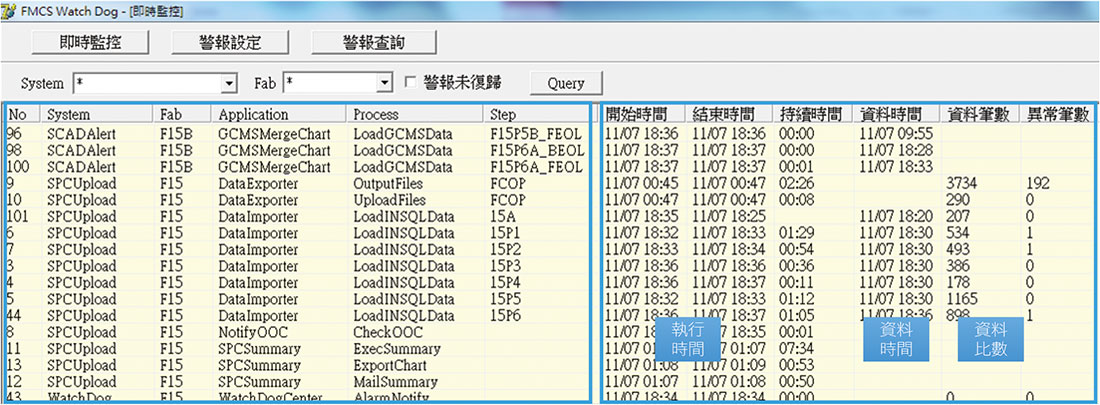
我們可以進一步透過健檢系統監控各應用程式各執行步驟即時的心電圖執行狀況。 圖6所示,我們可以查詢到各應用程式執行步驟開始執行的時間、結束的時間、持續的時間以及資料的筆數等,當任何應用程式發生異常的狀況時,我們可以立即查詢各執行步驟的執行狀況,以快速診斷究竟問題卡在什麼地方,並對症下藥立即進行異常排除。
圖6、健檢系統心電圖即時狀態監控
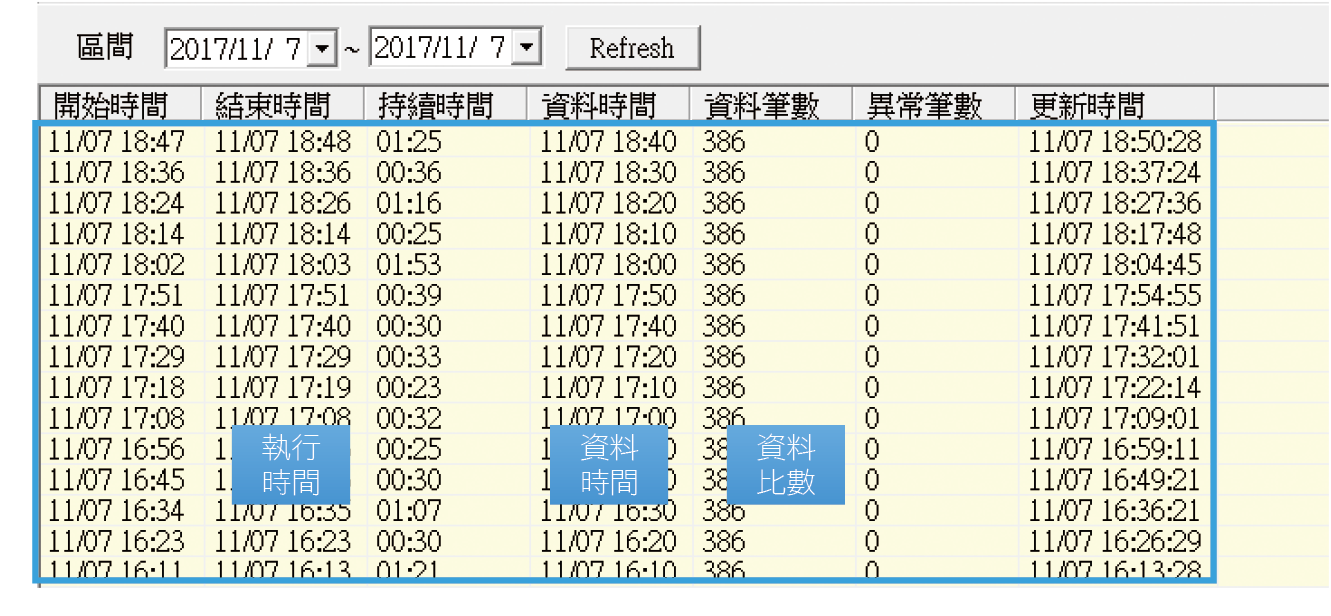
除了即時的心電圖監控外,健檢系統也提供了歷史的心電圖記錄查詢,包括每次執行的開始時間、結束時間、持續時間以及資料筆數等,如 圖7,我們可以透過這些大數據的收集計算各應用程式的執行基期並做為後續執行效率的分析與預警等應用。
圖7、健檢系統歷史心電圖記錄查詢
健檢系統測試與異常分析
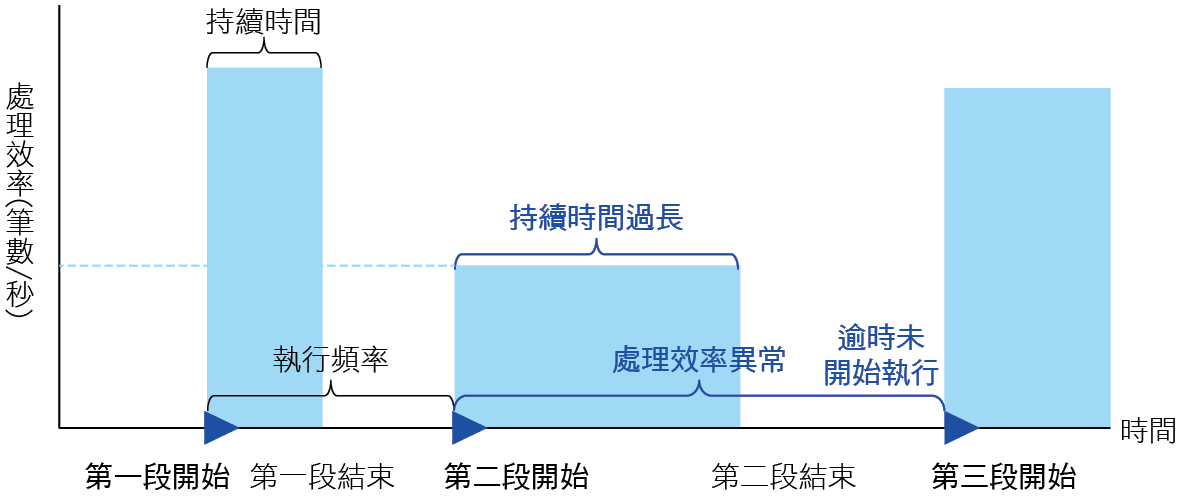
健檢系統收集了各個應用程式的心電圖後,下一步就是如何判讀心電圖的發生了異常?例如心跳暫停、心律不整與心跳無力等。這可以由 圖8的心電圖異常診斷手法來進行說明。通常應用程式都是以固定頻率來啟動執行,若正常執行狀況的時序圖如第一個方波所示,則可觀察到第二個方波執行的持續時間明顯較第一次拉長許多,這可歸類為心跳無力的現象;另外在處理資料的效率上,第二個方波也明顯偏低,我們可以判定為心律不整的狀況;第三個方波則未在預期的時間開始執行,且執行後一直沒有結束的狀況,屬於心跳暫停的異常。
圖8、心電圖異診斷手法
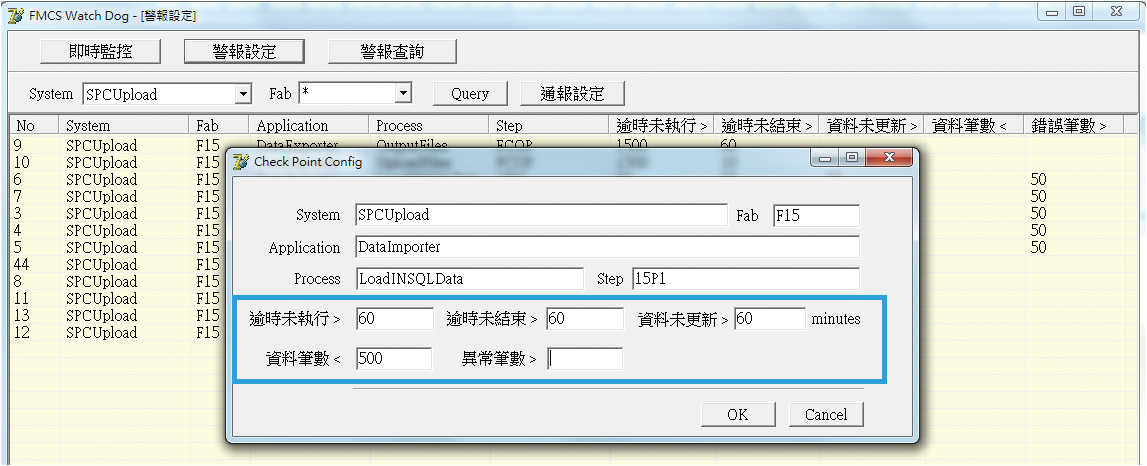
但健檢系統是如何判讀心電圖的異常呢?這可由 圖9的警報條件設定畫面進行規畫,包括逾時未執行時間、逾時未結束時間、資料戳記未更新時間以及資料處理筆數等。而每一個應用程式可透過歷史心電圖的記錄來計算合理的設定值。設定完成後,健檢系統會依據各應用程式所設定的條件,以每分鐘一次的頻率來進行所有應用程式的掃描,若符合所設定的警報條件,則心電圖異常的狀況即判斷成立。透過這樣的方式,健檢系統持續監控各應用程式的執行健康狀況,若發現異常將立即以簡訊以及Email雙重管道同步通報管理人員並進行問題排除,大幅減少過去用戶端通報異常的次數。
圖9、健檢系統警報設定畫面
除了即時判讀與通報異常的效益外,健檢系統的異常警報記錄也提供了我們系統問題分析與改善的重要參考依據。統計健檢系統上線以來五月到十月期間累積的警報次數為229次,我們針對每次的異常進一步進行分析與歸類,結果如 圖10,說明如下。
圖10、健檢系統異常原因分析
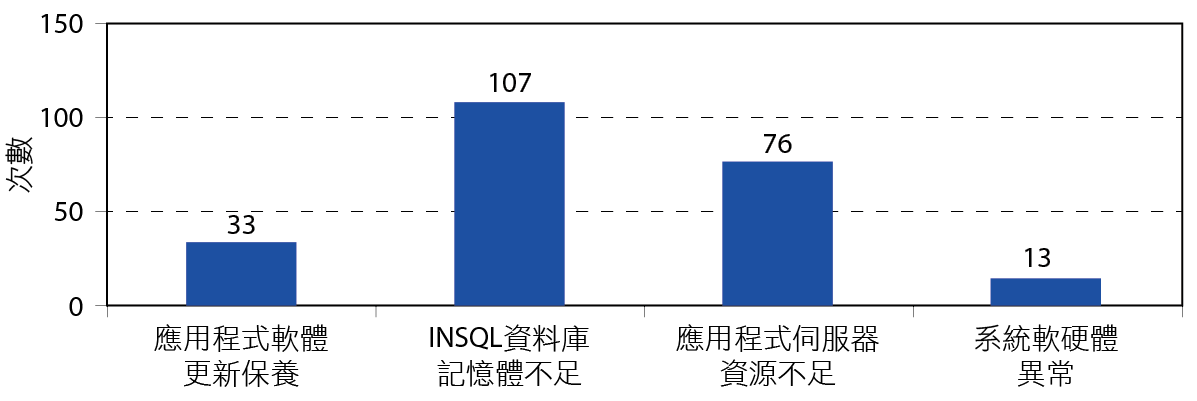
應用程式軟體更新保養
應用程式軟體更新例如Power SCADA或是設備停機保養例如Inline GCMS都會造成與健檢系統離線,屬於不可抗力的原因,但透過健檢系的異常通報,我們仍可以隨時掌控更應用程式的執行狀況。
INSQL資料庫記憶體不足
廠務各監控系統資料主要是儲存在Wonderware INSQL資料庫,但因為監控系統的點數眾多導致INSQL長期負載過重,加上無法自動釋放記憶體資源,因此每隔一段時間就會導致記憶體不足當機的狀況,相關的應用程式也會受到影響而停止運作,我們的短期的改善方法是將不必要的點位移除,長期的規劃是針對重要的系統建置獨立的INSQL資料庫,改善目前所有系統共用一套INSQL資料庫造成負載過重的問題。
應用程式伺服器資源不足
伺服器因為安裝的應用程式耗用資源不同,資料庫的負載分配也未考慮平衡,造成伺服器CPU、記憶體或硬碟空間不足,應用程式也跟隨停止運作。重新檢視應用程式的伺服器分配以及對資料庫進行負載的平衡或者安裝新的伺服器都能夠改善應用程式伺服器資源不足的問題。
系統軟硬體異常
系統軟硬體的故障造成應用程式異常,包括硬碟毀損、網路中斷與作業系統未安裝正確的修補程式導致當機等,這必須依賴定時巡檢維護的落實度來得到改善,例如查看異常紀錄檔,並進行系統的設定修改或安裝修補程式以排除問題。
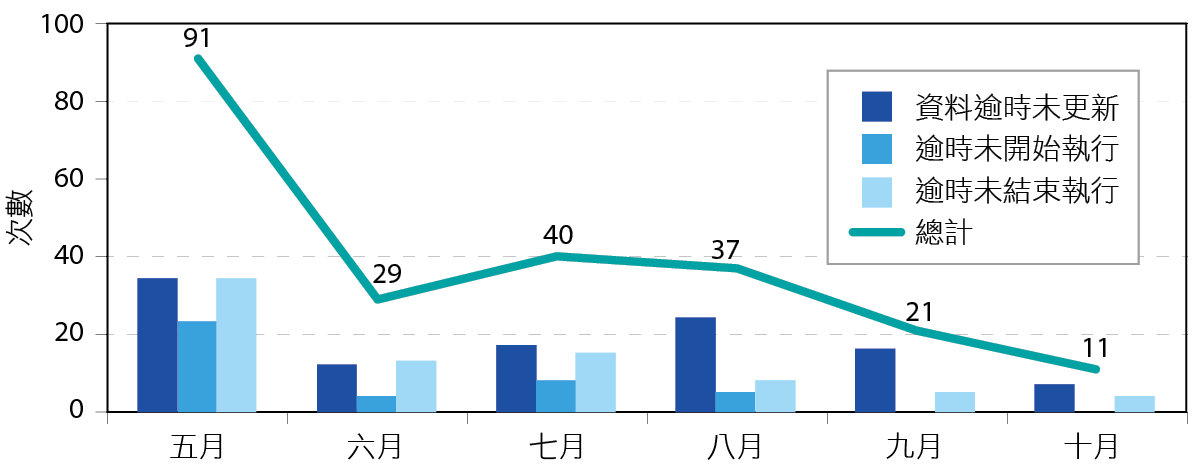
透過我們所進行的異常檢討與持續的改善,健檢平台發出的警報數量由五月的91次逐步減少到九月的21次並下降到十月的11次,如 圖11所示,系統的穩定度得到了有效的提昇,也改善了過去我們被動等待使用者反映異常的狀況以及免除了人工日常點檢的負擔,可將心力放在提昇監控技術層次上。
圖11、健檢系統異常數量統計表
結論
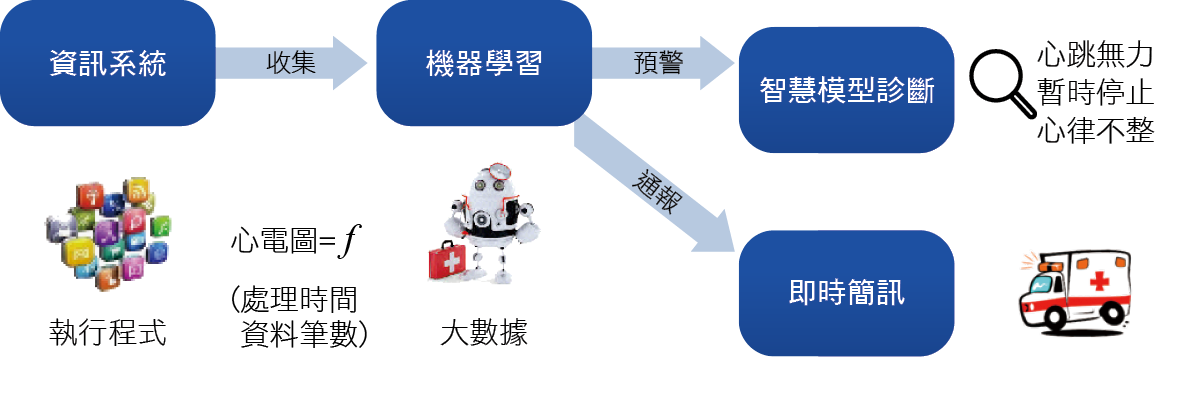
雖然我們的健檢系統有了初步的成果,卻也存在著許多限制與改善的空間,例如警報條件仍然透過人工來設定絕對數值,這樣的方式對於應用程式重急症有很好的偵測能力,但對於緩步惡化的慢性病的偵測能力卻不足。我們思索的解決方案是導入新一代人工智慧技術,透過類神經網路與機器學習等系統的建立,自動分析與發掘各類心電圖異常的偵測模式,不再需要人工來管理與維護警報的設定,就如同駐守著一位經驗豐富的人工智慧醫師「華陀」,能夠由看似正常的心電圖中偵測到細微的病徵,進而開立正確的處方,防堵病情的惡化,其概念如 圖12所示。
圖12、人工智慧心電圖預警平台概念圖
下一步我們將與新廠工程與各廠區進行心電圖健檢雛型系統的分享與討論,透過專家與各廠先進共同集思廣義,定義出跨廠區共同的標準與未來的發展方向,並與所有軟體廠商取得共識並進行合作,逐步導入自動化健檢系統到各廠區,以協助各廠電子化系統持續運轉不中斷,維持廠務與工廠之間資訊傳輸與整合之穩固與通暢。最後,以心電圖概念進行診斷的健檢手法除了可運用在電子化應用程式的偵測外,更可運用在廠務與時間處理相關的各個系統,例如偵測閥件開關時間與流量等關聯是否有變異之診斷與防禦等,這將有助於廠務整體運轉穩定度之提昇。
參考文獻
- NetIQ App Manager, https://www.netiq.com/products/appmanager/
- Design Patterns-Elements of Reusable Object-Oriented Software, Richard Helm, Ralph Johnson, John Vlissides, Baker & Taylor Books, 1998.
- Agile Software Development: Principles, Patterns, and Practices, Martin, Robert Cecil, Prentice Hall, 2002.
留言(0)