摘要

透視巨量資料分析

本文主要介紹巨量資料(Big Data)所使用到的資訊技術,並藉由實際案例的應用探討,了解軟體及硬體的配置,藉此提升對Big Data技術的進一步認識。
前言
2013年,可以說是Big Data在台灣全面引爆的一年,相關的書籍陸續出版,國際軟硬體大廠的研討會與相關課程也是一場接一場,到底Big Data有什麼魅力,引起大家的瘋狂追逐呢?
Big Data 是什麼?
依照維基百科上的定義,Big Data (大數據、巨量資料、海量資料),指的是所涉及的資料量規模巨大到無法透過人工,在合理時間內達到擷取、管理、處理並整理成為人類所能解讀的資訊。
從大家每天所使用到的搜尋引擎(Google、Yahoo)、社群網路(Facebook、Twitter)到感測器(Sensor)所擷取到的資料…等,透過電腦進行篩選、整理、分析所得出的結果,能提供給企業做為經營決策的參考,以開發出更大的價值。
談到Big Data,就必須先了解代表其特性的三個V,分別為:Volume (資料量)、Velocity (資料處理速度)、Variety (資料多樣性),以下就三個特性進行說明 圖一:
圖一、代表Big Data 特性的三個V
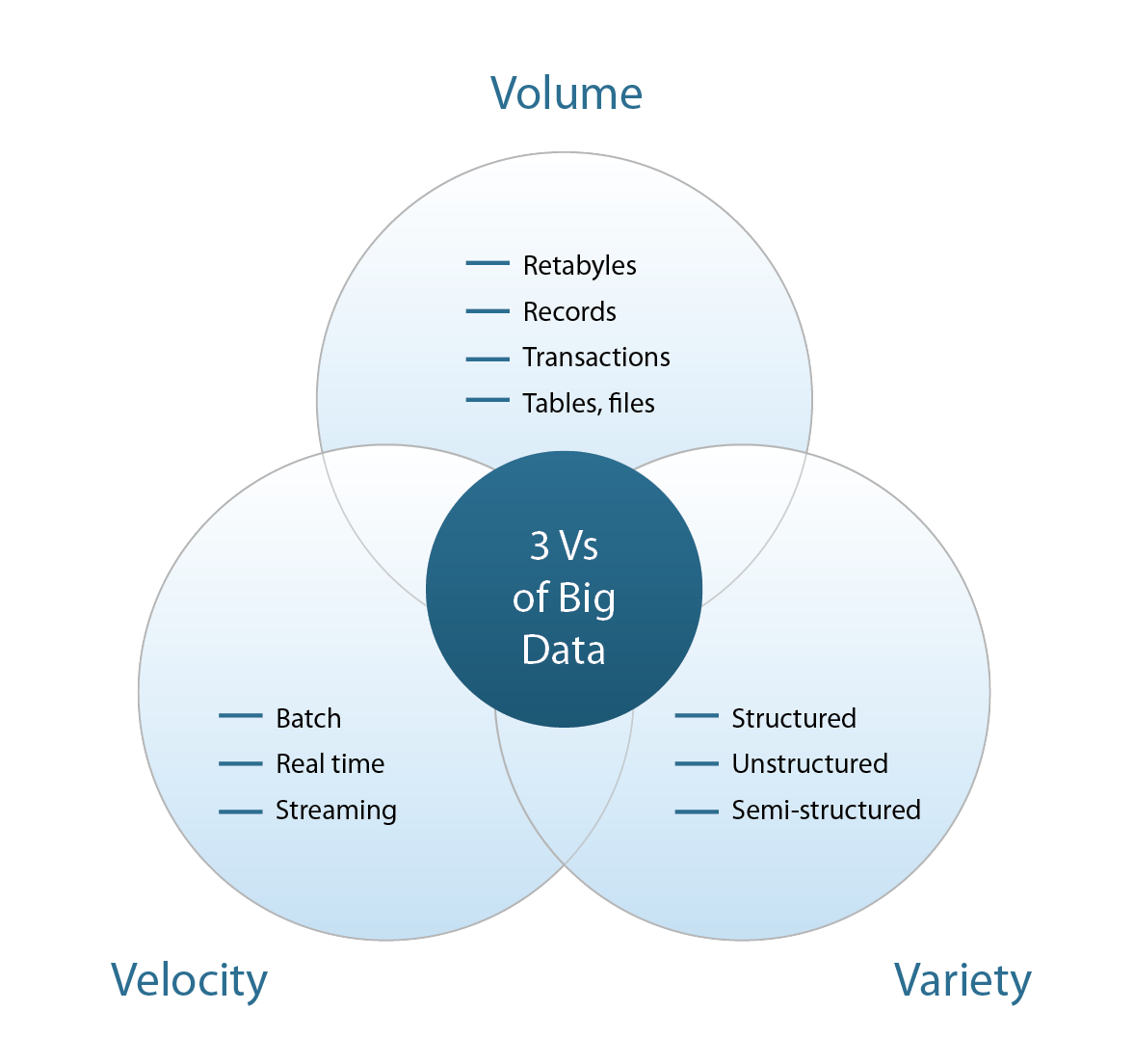
Volume
在目前資料快速成長的狀況下,累積蒐集與需要處理的資料量已經超越大家常見的TB(terabyte)來到PB(petabyte)等級了,在未來幾年可能更會增加到EB(exabyte)甚至ZB(zettabyte)等級。 表一
|
十進制前綴 (SI) |
||
|---|---|---|
|
名字 |
縮寫 |
次方 |
|
千位元組(kilobyte) |
KB |
103 |
|
百萬位元組(megabyte) |
MB |
106 |
|
吉位元組(gigabyte) |
GB |
109 |
|
兆位元組(terabyte) |
TB |
1012 |
|
拍位元組(petabyte) |
PB |
1015 |
|
艾位元組(exabyte) |
EB |
1018 |
|
皆位元組(zettabyte) |
ZB |
1021 |
|
佑位元組(yottabyte) |
YB |
1024 |
Velocity
如高速公路電子收費、捷運悠遊卡的搭乘必須即時完成扣款並顯示餘額,完整紀錄支付交易,對立即性大量資料的分析,資料處理的速度與效率都是相當具有挑戰性的課題。
Variety
過去常被大家拿來分析的資料主要為已經被結構化存放的資料庫資料,在Big Data的世界中,除了文字之外,更包含了半結構化資料如Office檔案與非結構化資料如語音、視訊…等等資料。
Big Data 應用
Big Data在各行各業被廣泛的談論著,從初期在上述所介紹技術上的問題,到目前在各領域上的應用。介紹兩個Big Data應用實例:
全球第二大建築機械製造商小松(註一),利用安裝於機械設備的感測器及GPS定位器,完整蒐集如:位置、運轉時數、運轉狀態,燃料使用情形…等等資料,整理分析後,除了可掌握機器的情況並進行細部設定調整外,也能分析機器使用的模式對於零件損耗率的影響,對於零件準備與維修效率有很大的提升。另外,透過分析出來的資料,主動給予客戶操作及節能的建議,不僅讓客戶學習以適當的操作來提升機械的壽命,也提升了企業的品牌形象。
全球擁有2億7千萬名註冊會員的拍賣網站eBay(註二),每分每秒都在進行著各項商品買賣,目前每天產生的新資料量約有50TB,要處理約100PB的資料,為了達到客戶服務與使用者經驗的提升,必須有效善用這些資料,並透過資料分析歸納,來進行即時網頁操作介面及功能的變更。以eBay網站的規模,僅是些微的選單及連結配置調整,都有可能會大幅影響公司營收,為了進行這樣的分析,eBay儲存了使用者在網站上的所有行為紀錄,如僅瀏覽但沒有購買或已經要下標,結果最後又放棄…等為期兩年份的記錄,過去只儲存約1%的行為紀錄,在進行系統測試時可能又需要2~3個月才能看出結果,現在利用Big Data技術,儲存100%的紀錄並進行分析,只要半天至1週便能揭曉,大幅提升效率。
剖析 Big Data 架構
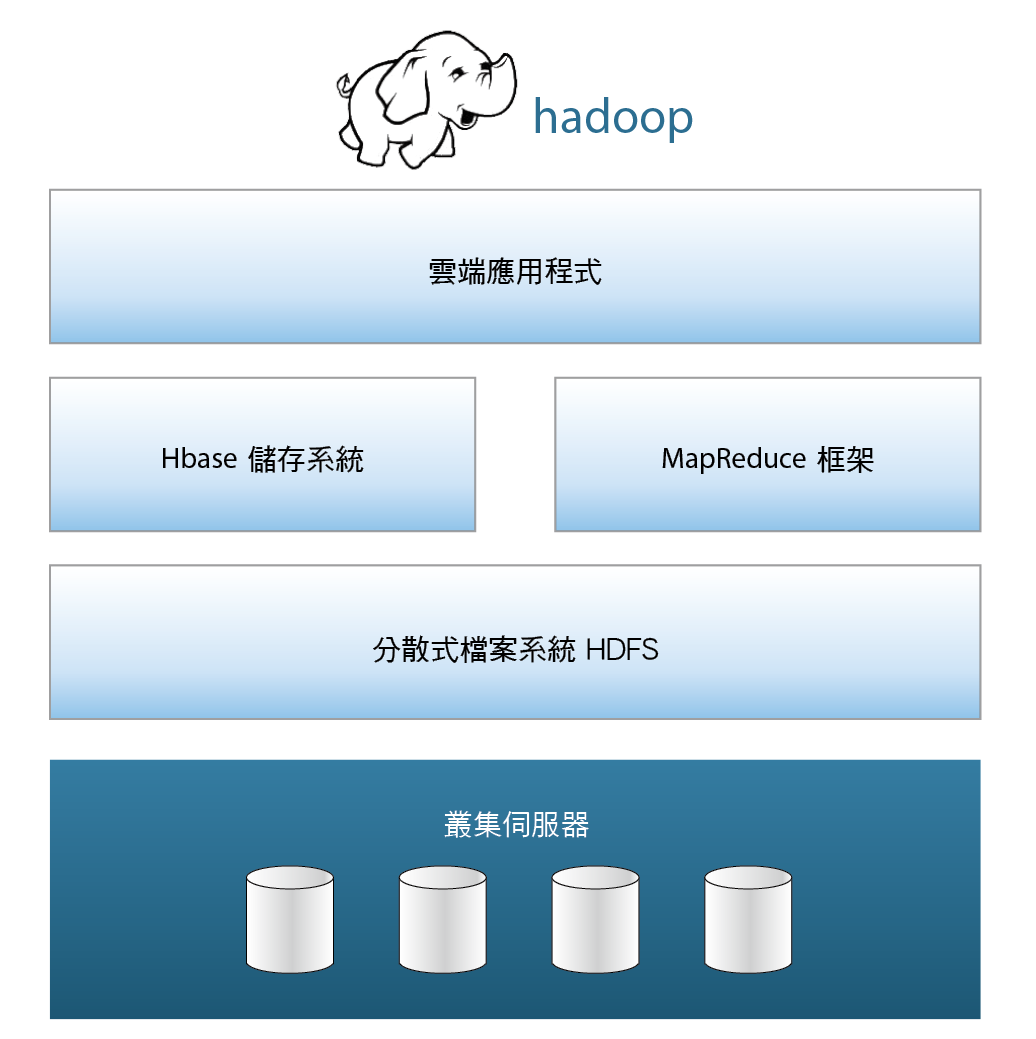
Big Data到底是透過什麼技術做到這些的呢?目前在Big Data發展的主要技術,莫過於Hadoop平台。它是由Apache軟體基金會(註三)所發展的一項開放原始碼計畫,其內容是根據Google所發表的MapReduce及Google檔案系統的論文為架構基礎實作出來的,他包含了MapReduce框架、分散式的檔案系統HDFS (Hadoop Distributed File System)以及儲存系統HBase。主要技術是透過分散式的運算架構將大量資料或運算,切割成一個一個較小的任務,分派給不同的機器來進行運算。 圖二
圖二、Hadoop 組成架構
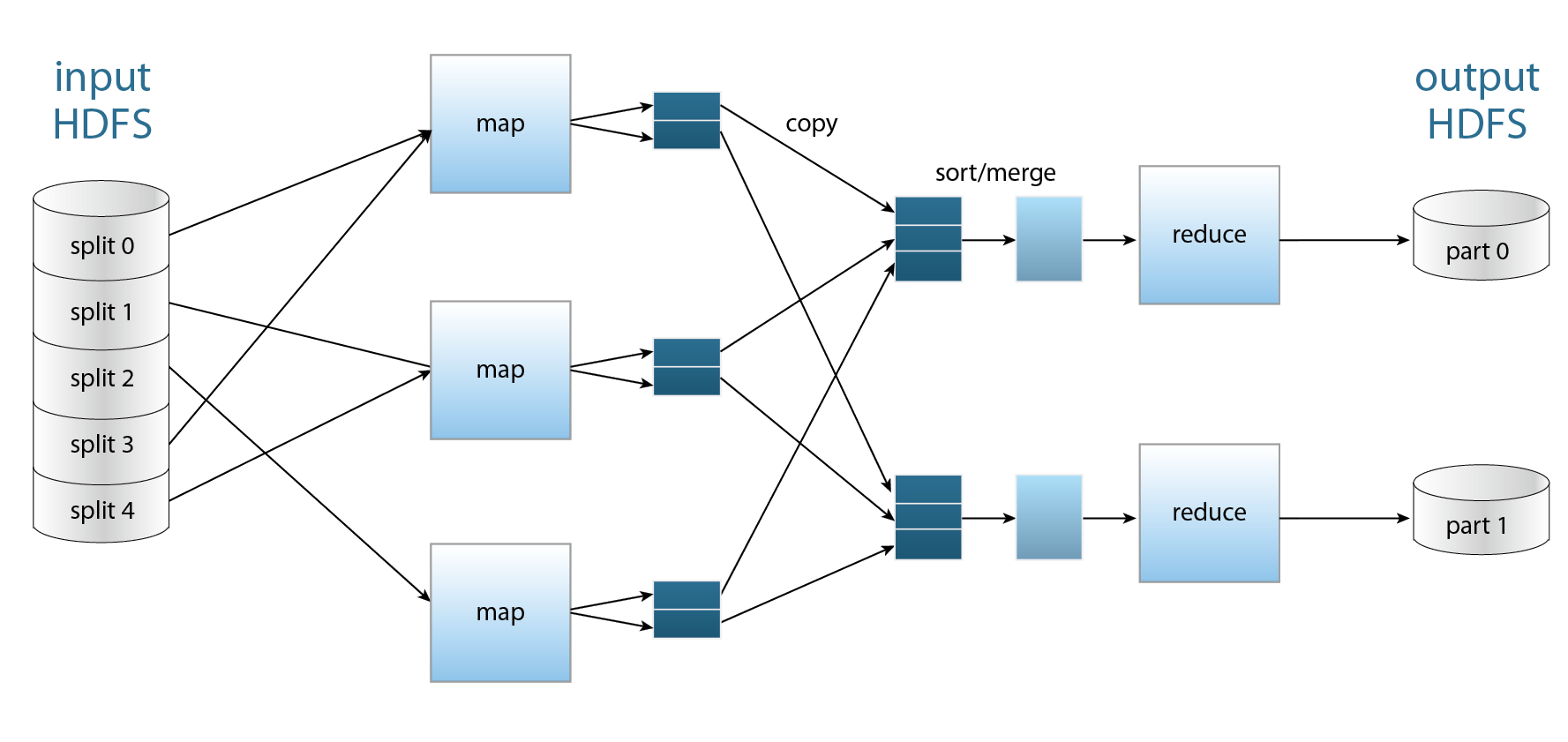
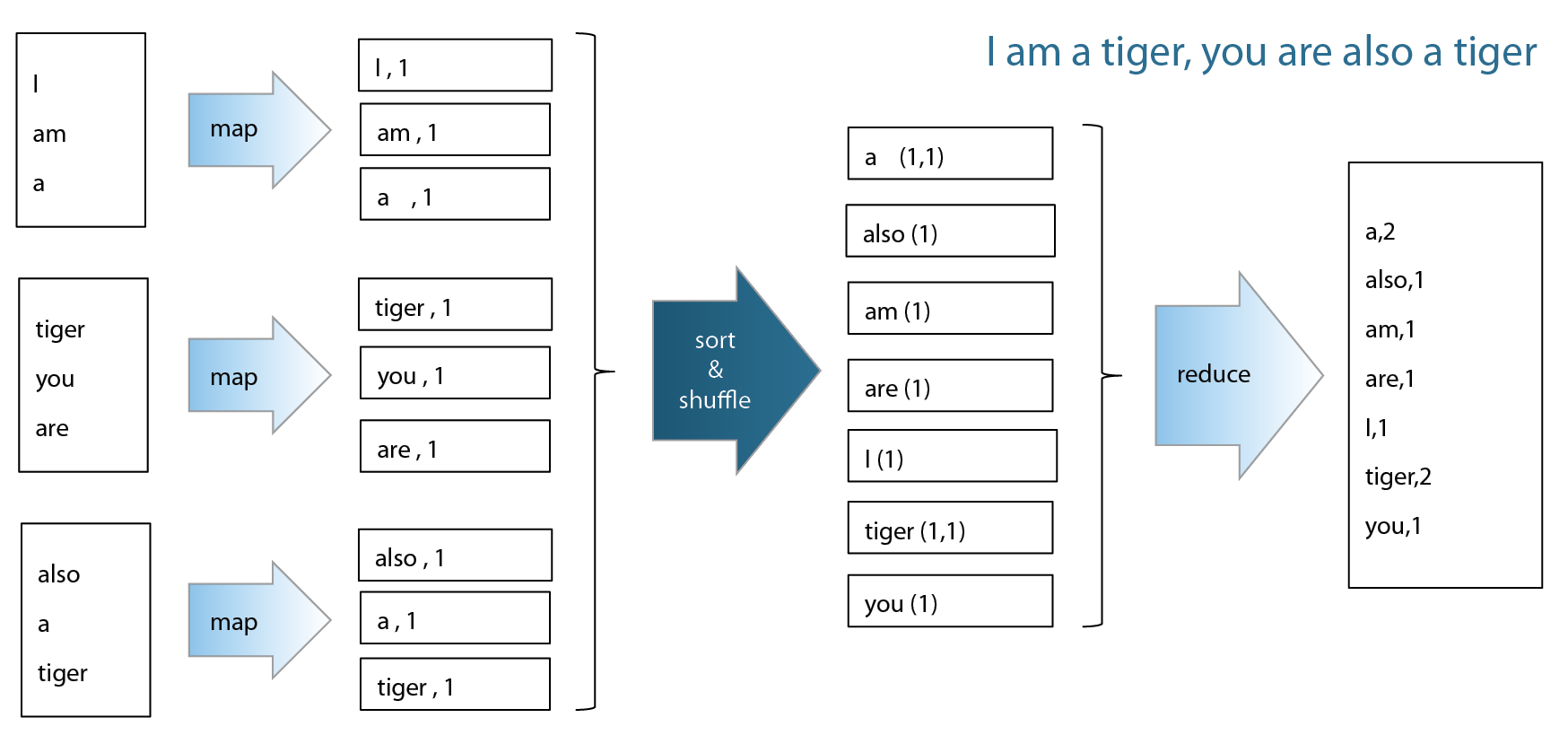
MapReduce的概念,是將問題分解成很多個小問題之後再做總和。透過MapReduce可以用來進行大型資料處理,例如:搜尋、索引製作與排序,大型資料集的資料採礦與機器學習,大型網站的網站存取日誌分析等應用。 圖三、四
圖三、MapReduce 運作流程
圖四、MapReduce 運作範例
HDFS則是在分散式的儲存環境裡,提供單一的目錄系統 (Single Namespace)。在一個超大型分散式檔案系統中,通常會有數萬個節點、數億個檔案、以及數十Peta Bytes的資料量,在這之中,每個檔案被分割成許多區塊(Block)分散儲存於不同的資料節點(DataNode)上,並存放好幾份的副本,當系統偵測到錯誤時,即可從備份的資料執行回復,並可藉由將資料運算端與實體檔案放置於同一台主機來加強資料處理的效率。
Hbase是架構在HDFS上的分散式資料庫,與一般關聯式資料庫 (relational database) 不同,提供需要在隨機且即時的讀寫超大資料集時所使用。HBase使用列 (row) 和行 (column) 為索引存取資料值,並具備高可用性、高效能,以及容易擴充容量及效能的特性。
Big Data在硬體架構上與傳統方式也有所不同,傳統大型主機是垂直式擴充(Vertical Scaling)的設計架構,而Big Data採用的Hadoop雲端運算,則是使用水平式擴充(Horizontal Scaling)的設計架構。
圖五、Processing Big Data, the Google Way

垂直式的擴充,是指不斷提高單一台伺服器的運算能力,例如,盡力讓單一台伺服器配備更多的運算核心,來提升應用程式可以處理的資料量;而水平式擴充則是利用不斷增加伺服器的數量,來提高應用程式可以處理的資料量,而不強調提高單一伺服器的運算能力。所以,採取水平式擴充的設計,隨著應用程式服務的使用者增加,要處理的資料量越來越大,只需要不斷增加新伺服器即可,不需要修改原來的應用程式碼。
由於透過水平方式對伺服器擴充可有效提高系統運算的能力,不需要初期就購買昂貴的大型主機,可以分階段建構數百台普通等級電腦,透過Hadoop整合,就能提供超過單一台大型主機的運算能力,以更低與即時的成本支出,得到更高的運算效能。另外,水平式擴充的架構也提高了系統的容錯能力。當單一台大型主機一旦當機,垂直式主機所執行的應用程式就會完全停擺,無法提供服務。在Hadoop的架構下,則是將程式切割成很多部分分配到多台電腦中執行,即使當中有幾台電腦當機,也能立即將所需要的運算自動分配給閒置的電腦,整體的應用程式服務不會中斷。
最後,運行於Hadoop上的應用程式,則是負責所有的商業邏輯判斷以及各種資料之間的轉換,再透過方便使用的介面將分析完成的資料呈現出來。
結論
Big Data其實不是嶄新的概念,資料蒐集分析早已形之多年,但是為什麼到近期才開始蓬勃發展?主要是因為Hadoop平台的問世,使得分散式的應用程式建構變得容易;此外,電腦的效能提升與儲存設備價格不斷下滑也讓新創公司或中小企業不必花費太多成本就能做到相關的應用,促使Big Data能在最近幾年快速擴展到各個領域。
新工處在建廠過程逐漸累積越來越多的建廠資訊。如果能透過Big Data技術有效運用這些資料,提前發現專案執行上的問題,或是提供必要的關鍵資訊作為專案管理與決策的參考,相信對未來建廠專案的執行與管理一定能有顯著的幫助。
參考文獻
- Wikipedia (http://zh.wikipedia.org/wiki/大數據/)
- 城田真琴, 經濟新潮社, 大數據的獲利模式, 2013
- 宋吉永, 悅知文化, Big Data: 讓你看見真實欲望, 2013
- 麥爾荀伯格, 天下文化, 大數據, 2013
附註
- [註一] 小松製作所(日語:株式会社小松製作所)是一間位於日本的重化工業產品製造公司,該公司在日本重化工業器材製造公司中排名第一,而世界排名則是第二名。(Wiki)
- [註二] eBay是一個可讓全球民眾上網買賣物品的線上拍賣及購物網站。(Wiki)
- [註三] Apache軟體基金會(Apache Software Foundation,簡稱為ASF),是專門為支援開源軟體專案而辦的一個非營利性組織。(Wiki)
留言(0)