摘要



知識係企業之核心競爭力,除了內部知識的傳承外,外部知識的吸收亦是提升企業整體競爭力的重要環節。本文以文件分類於知識管理應用之發想為主題,針對文件分類概念及常見的技術進行說明,並介紹目前新工如何將文件分類應用於外部知識分類及預期達成的效益。
前言
身處知識經濟時代,知識除了是企業的無形資產外,亦是決定企業成功與否之重要因子。有鑑於此,近來知識管理日益受到重視,並廣泛的推行於各企業中。知識管理的應用,除了內部既有資源的管理外,亦包含外部知識的收集及吸收。
以新工為例,過去同仁在新廠設計、規劃等階段常需收集外部新知,過程中需花費時間、精力在過濾大量資訊,相當費力耗時。有鑑於資訊檢索、文件分類等自然語言處理技術漸趨成熟,若能妥善的運用,將有助於協助同仁快速掌握新知,應用於日常工作中。
在自然語言處理技術中,文件分類的目的在於利用機器學習的方式,自動判別文件所屬主題類別,其應用有助於同仁快速且精確找到所需的知識。有鑑於此,文件分類技術於知識管理應用的導入有其必要性。本文透過文件分類於知識管理應用之發想為例,進行文件分類技術之介紹及應用探討。
什麼是文件分類?
文件分類,是依照文件的主題與相關內容,給予該份文件一個合適的主題類別。以每天所閱讀的報紙為例,依照內容可分為「財經」、「娛樂」、「體育」和「社會」等不同類別;這些分類皆是事先已定義好,再根據當天不同的新聞內容大意,給予標示適當的類別。
由於電腦軟、硬體及網際網路等資訊科技發展迅速,資料的數量以及資料複雜性也隨之成長;使用者花費在整理以及尋找所需文件的時間與心力已不可同日而語,因此文件分類已愈趨重要,在知識管理領域中更是不可或缺的工具。若能將收集到的資料文獻,事先分門別類進行歸納與整理,通過將非結構化資料轉化成結構化資訊的加值過程,不僅能幫助使用者有效率的獲取所需的資訊、管理資訊外,更可使得這些有用的資訊重覆被利用。
常見的分類技術大致可分成監督式學習(supervised learning)及非監督式學習(unsupervised learning)兩類,兩者主要區別在於分類資料中是否存在既有的類別資訊。為了讓讀者對文件分類的原理有一個概略性的了解,以下我們針對監督式學習及非監督式學習進行介紹。
監督式學習
監督式學習適用於已知類別的分類問題,意即分類前已有明確定義之主題類別,例如新聞可分成政治、財經、旅遊及運動等主題類別。監督式學習的運作流程可分成三個階段(如 圖一、圖二):
圖一、監督式學習運作流

圖二、監督式學習運作範例
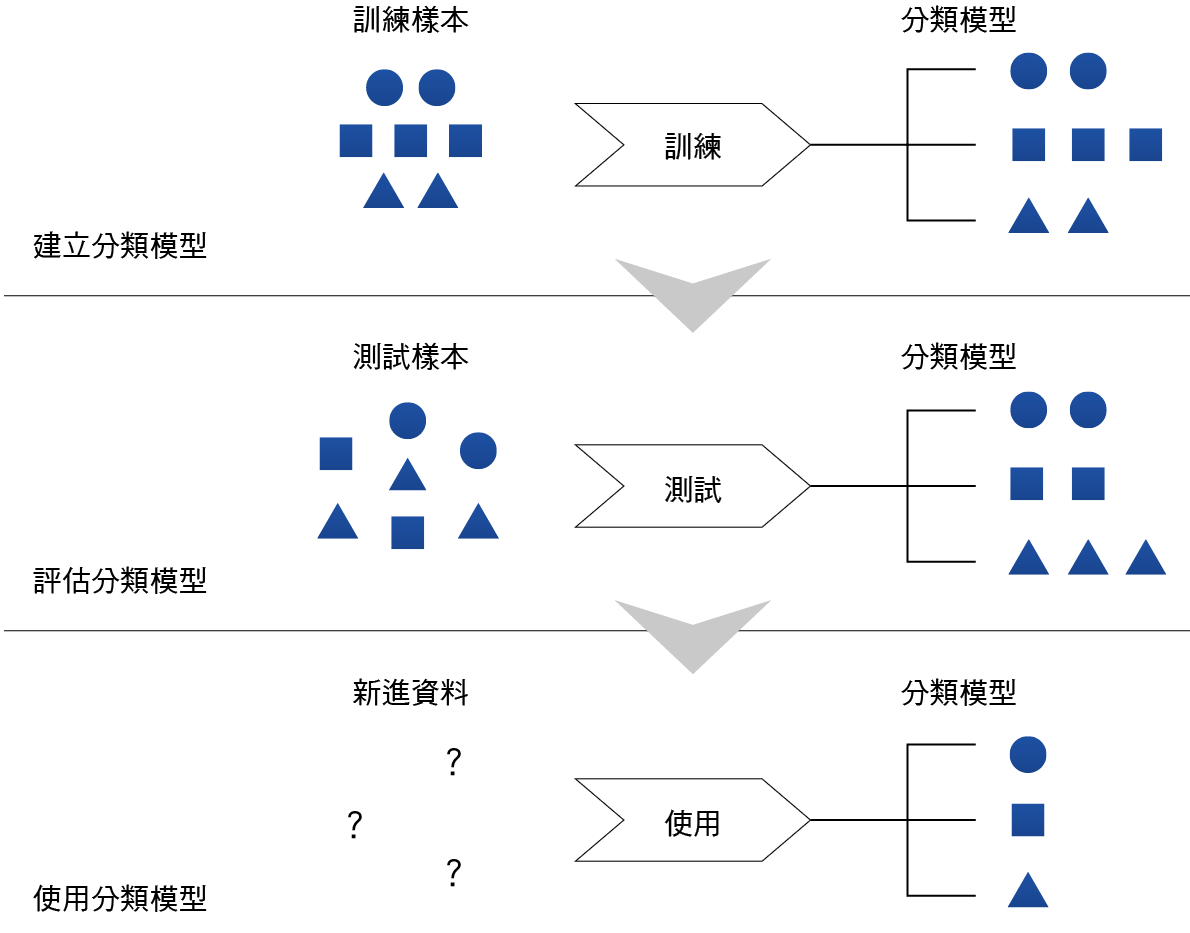
- 建立分類模型:建立分類模型時,通常會將現有已知主題類別的資料分成訓練樣本及測試樣本。分類模型建立係指利用訓練樣本的資料,將資料的分類規則找出來,藉以建立分類模型。
- 評估分類模型:當分類模型建立完成後,此一階段即可利用測試樣本,測試建立好的分類模型是否能夠準確的預測測試樣本所屬的類別。
- 使用分類模型:確認完分類模型之準確度後,便可利用分類模型來找出資料分類的原因,或利用分類模型預測新進資料所屬的類別。
非監督式學習
不同於監督式學習,非監督式學習沒有事先定義好的主題類別。其主要目的在於分析資料間的相似程度,並依相似程度將資料分成數個群集。相較於群集間的資料相似程度,群集內的資料彼此擁有較高的相似度。非監督式學習的運作流程大致可分成四個階段(如 圖三、圖四):
圖三、非監督式學習運作流程

圖四、非監督式學習運作範例
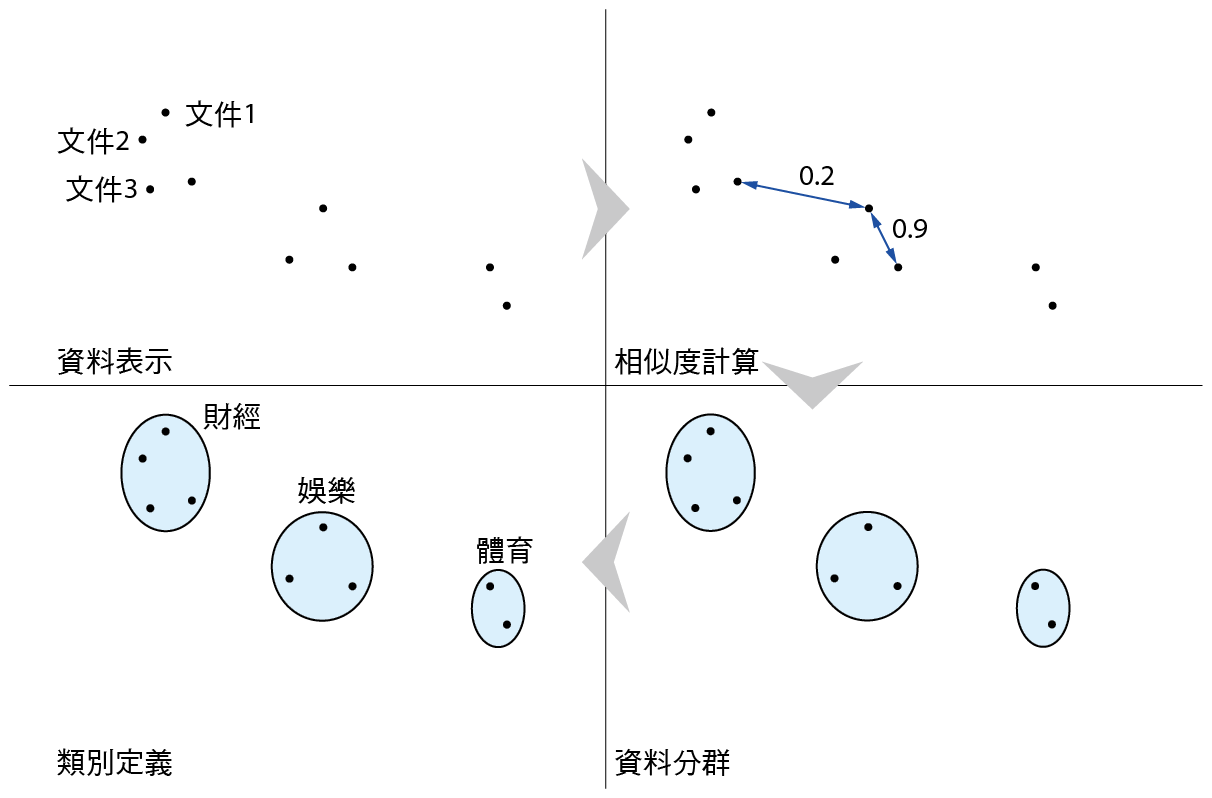
- 資料表示:針對分類主題的特性,挑選出具代表性的特徵,將每一筆資料轉換成多維度特徵空間中的資料點。
- 相似度計算:透過資料點在特徵空間中的距離等評估方式,計算資料點間的相似程度。
- 資料分群:藉由相似程度計算結果,將所有資料分成數個群集,每一個群集中的資料與資料間具有較高的相似程度。
- 類別定義:領域專家根據分群結果進行資料分析,並針對分群結果做進一步的解釋。
綜合上述,監督式學習與非監督式學習的分析比較整理如 表一。
|
監督式學習 |
非監督式學習 |
|
|---|---|---|
|
適用性 |
分類前已有明確的主題類別 |
發掘未知但有用的主題類別 |
|
優點 |
分類準確率較高 建立分類模型效率較佳 |
不需仰賴事先定義好類別的訓練樣本 專家介入需求度較小 |
|
缺點 |
需專家介入,協助定義訓練樣本之主題類別 不同的專家對於同一資料的主題類別定義可能不一致 |
不容易解釋分類過程 |
文件分類應用構思
為了讓讀者更容易體會文件分類能夠帶來的效益,我們提出一個文件分類應用構思,說明目前新工如何運用文件分類提升知識管理之應用層級。目前新工正在發展導入的系統方案主要是應用前述監督式學習的方式,進行期刊文獻之自動收集及分類,整體系統架構規劃如 圖五,包含文獻收集模組、文獻分類模組、文獻瀏覽模組、類別回饋模組及分類優化模組。
圖五、期刊文獻分類系統架構規劃
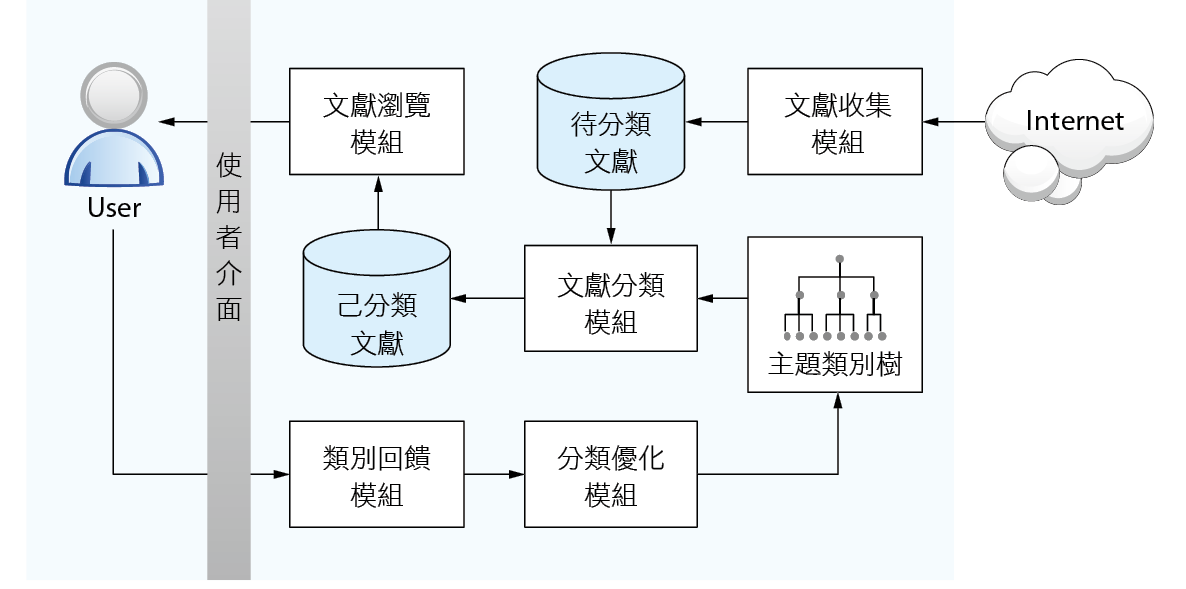
首先,專家針對其專長定義主題及主題類別,並協助提供各類別之相關文件,透過監督式學習法建立分類模型。接著文獻收集模組根據事先設定好之主題及期刊來源,自動從網際網路中收集與主題相關之文獻,並儲存於待分類文獻庫中。文獻分類模組隨後運用自然語言處理及文件分類技術,自動分析各文獻之特徵(例如關鍵字),並決定文獻所屬類別。
文獻瀏覽模組提供文獻分類瀏覽功能,使用者透過瀏覽器即可瀏覽主題相關文獻及文獻分布等資訊。若使用者在瀏覽的過程中發現文獻類別有誤,可進一步透過類別回饋模組提供類別修正回饋。其後,系統利用收集到的回饋資訊,透過分類優化模組將文件分類模型進行修正,藉此提升文獻分類之準確度。
預期將上述系統應用於知識管理中能夠達成的效益如下:
- 加速資訊收集:透過視覺化知識分布及資訊呈現,提供同仁快速且精確的參考資訊。
- 聚焦重點文獻:自動文獻關聯性建立及主題相似文件推薦,協助使用者快速聚焦重點文獻。
- 促進知識交流:藉由新知研讀、評論及心得交換促進知識分享。
初步訪談資料顯示,過去透過Google關鍵字搜尋的文獻收集方式,同仁平均需花費5分鐘過濾1篇文獻,每10篇文獻約有2~3篇真正符合需求。透過前述的文件分類應用,除了文獻收集符合使用者需求外,視覺化的知識分布呈現,更使同仁在短時間內即可存取到主題相關文獻。
從龍捲風科技─中文搜尋引擎的領導者,於2014年底提供之新聞文章與節能主題文獻實測資料顯示,當訓練文件數為200時,透過監督式學習法建立之分類模型準確度達85%,亦即每10篇文獻即有8篇真正符合需求。比較過去關鍵字搜尋方式,同仁收集10篇相關文獻需花費約170分鐘1,導入文件分類應用後,收集10篇相關文獻僅需花費約65分鐘2,省下約62%的時間,且過程中可直接針對主題相關文獻進行瀏覽,不需事先鍵入關鍵字。
結論
本文旨在介紹常見的分類技術,以及文件分類技術於知識管理的應用發想,藉以說明如何運用分類技術於提升知識管理的應用層級。文件分類於知識管理的應用有助於精確的收集到相關的資訊,以及知識收集效率的提升,進而增進同仁核心知識與技術的提升。
新工目前正在發展導入文件分類技術實際運用於新廠建立及廠務運轉等日常工作中,透過專家訪談及工作小組討論,規劃系統發展的方向及目標,將發想有計畫的執行,使之成為未來新廠建立及廠務運轉上一項獲取新知的利器。
註腳
- 收集10篇相關文獻需過濾10/(3/10)= 34篇文獻,每篇花費5分鐘,共需花費34×5=170分鐘
- 收集10篇相關文獻需過濾10/(8/10)= 13篇文獻,每篇花費5分鐘,共需花費13×5=65分鐘
參考文獻
- 曾憲雄、蔡秀滿、蘇東興、曾秋蓉、王慶堯,資料探勘,旗標出版,台北(2005)。
- Changchun, Y., and Li, Y., “A data mining model and methods based on multimedia database”, 2010 International Conference on Internet Technology and Applications, pp. 1-4 (2010).
- Hong, S., Han, X., Tian, L., and Luo, L., “An automatic classification system for the stock comments”, The 9th International Conference onComputer Science & Education, pp. 89-92 (2014).
- Li, C., and Zhou, J., “Semi-supervised weighted kernel clustering based on gravitational search for fault diagnosis”, ISA Trans, Vol. 53, No. 5, pp. 1534-1543 (2014).
- Kotsiantis, S.B., “Supervised machine learning: a review of classification techniques”, Informatica, vol. 31, pp. 249-268 (2007).
- Umamaheswari,U., and Shivaji Rao, G., “An efficient way of classifying and clustering documents based on SMTP”, International Journal for Research in Applied Science & Engineering Technology (IJRASET), Vol. 2, No. 6, pp.18-23 (2014).
留言(0)