摘要

應用AI-AMC機械學習預測與污染來源分析
Keywords / Airborne Molecular Contamination5,Cleanroom4,Machine Learning5,Big Data7

因應市場的需求,半導體製程技術演進快速,電晶體30年內已縮小了1000倍,到了五奈米的技術,而隨著規格及產線環境要求的提升,氣態分子微汙染(airborne molecular contamination, AMC)的控制對於製程良率改善更是有舉足輕重的影響。AMC汙染源普遍來自製程清潔使用後化學品,煙囪排放後由外氣空調箱進入FAB,造成潔淨室環境汙染濃度上升而頻繁更換化學濾網,進而衍生龐大的濾網相關費用。AMC的防治及監測更是需投入大量的物資、人力,因此若能利用現有的資料庫,對多面項數據進行結合、比較甚至預測,將有效提升AMC的防治。
隨著大數據及機器學習的蓬勃發展,本文利用機器學習模型和AMC大數據的結合進行汙染的來源分析並改善,再進一步預測未來24小時內MAU出口的AMC濃度變化,猶如天氣預報,作為及早應對措施之參考,減少警報次數甚至降低運轉成本。
Over the past 30 years, the semiconductor technology has been developing swiftly and exponentially in response to the skyrocketing demand of the market, the size of transistor has shrunk by 1,000 times and delved into five-nanometer scale. With progressively stringent production-line environmental and specification requirements, gaseous molecular pollution(airborne molecular contamination, AMC) control plays a paramount role in the yield enhancement. The source of AMC typically originates from chemicals(solvents) used for cleaning wafers in the processes, after being discharged from the stack, through the air conditioning box into the FAB, resulting in increasing contaminant concentration in the clean room and frequent replacement of AMC chemical filters, which in turn leads to massive cost associated with the filters. The precautions and monitoring of AMC require a tremendous amount of materials and manpower. Therefore, effective control of AMC can be achieved with early preventive measures if the existing database can be combined, compared, and even utilized to predict the trend of AMC down the road.
With the mature development of big data analysis and visible advancement of machine learning, this study used the combination of machine learning model and big data to conduct analysis and prediction, furthermore, foresee the change of the AMC concentration at the MAU discharge in the following 24 hours, just like weather forecast, as a reference for counter-measures to reduce the alarm rate and operating costs.
1. 前言
隨著半導體製程的演進,電晶體規格從1987年的3微米到2021年的3奈米,無塵室生產環境對於AMC潔淨度的要求亦日漸嚴苛。許多文獻指出AMC對於半導體製程的重要影響,如造成導線的腐蝕(MA)[13]、T-topping(MB, NH3)[12]、微影鏡頭的霧化(MA/MC)[14][15]、電性的改變(MD)等產品的缺陷。因此,工廠針對AMC汙染物的防治,每年投入大量成本於監測系統的設置、保養,人力巡檢及採樣,濾網的購買、更換及處理。而透過儀器監測,人工採樣提供大量的AMC數據基礎,若能藉由AI機器學習幫助AMC的預測以及汙染物濃度成因分析,將對警報的減少及汙染物的來源能有更進一步的了解。
2. 文獻探討
2.1 AMC定義
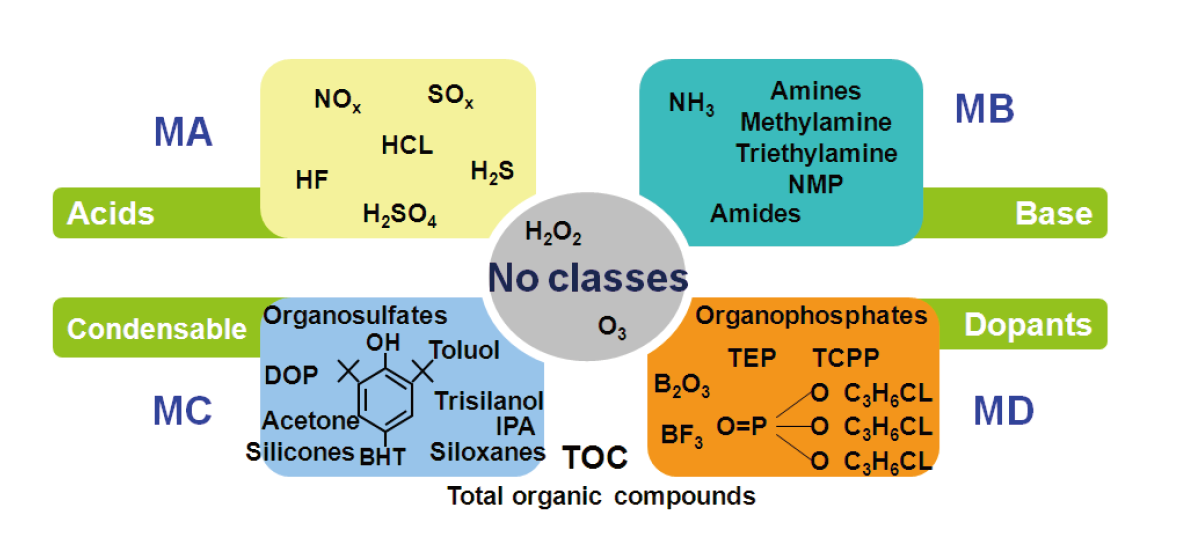
氣態分子微汙染(Airborne Molecular Contamination, AMC)是半導體技術發展需克服的主要問題之一,根據SEMI F21-1102[16]定義,主分四大類:酸性物質(MA)、鹼性物質(MB)、可凝結物質(MC)、載體物質(MD),詳細分類如 圖1所示。另外,在ISO-14644-8[17]定義無塵室相關環境管控,第8部分將AMC分成八類,包括酸、鹼、生物毒性、可凝結、腐蝕性、載體、有機以及氧化。而2015ITRS(the International Roadmap for semiconductor)的良率提升報告[18]中明確指出AMC為良率提升的重要指標之一,並訂定無塵室管控標準以及監測方法幫助半導體製造技術突破。
圖1、AMC汙染源分類表
2.2 AMC迴風路徑
經由了解無塵室迴風路徑,並在各關鍵結點設置監測,可得知汙染物在潔淨室內的濃度分布,如 圖2:Stack/ atmospheric air→penthouse→MAU→MA outlet→mixture of circulating air→L35 FFU→L30→L30 tool FI→L20→mixture of circulating air。而迴風路徑對應濃度分布如圖3。
圖2、潔淨室迴風路徑示意圖
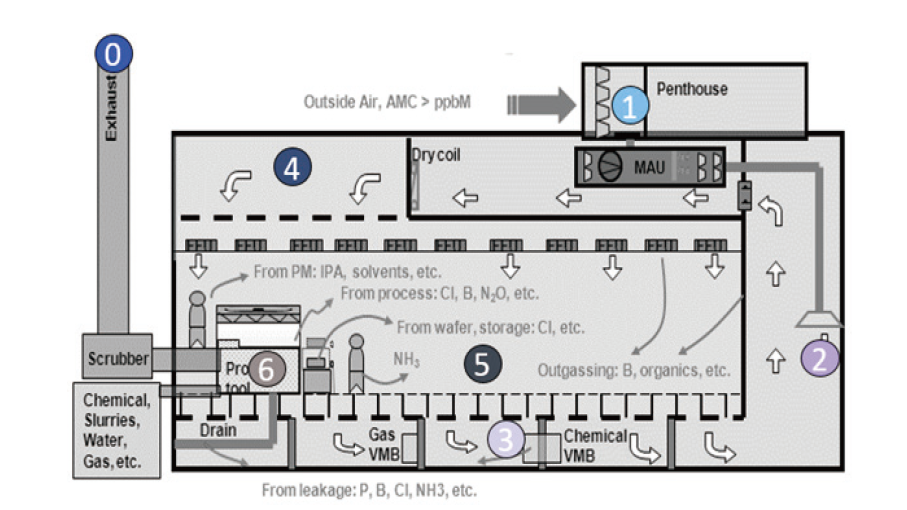
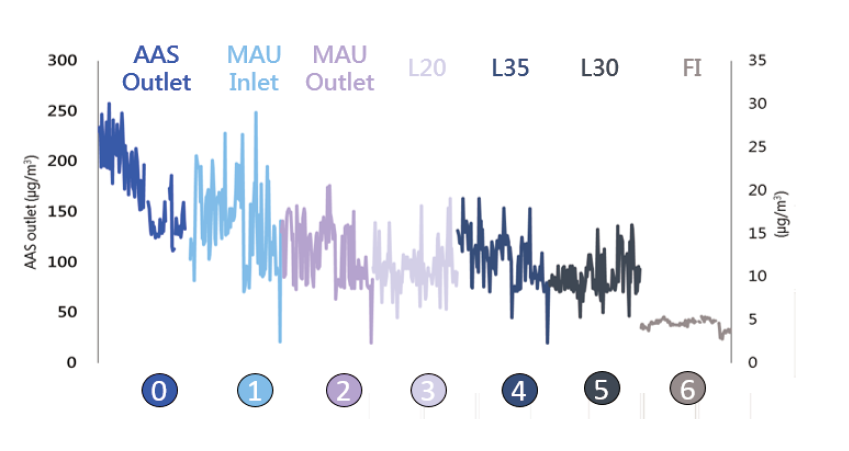
圖3、迴風路徑AMC濃度趨勢圖
2.3 機器學習預測模型
2.3.1 長短期記憶模型(Long-Short Term Memory)
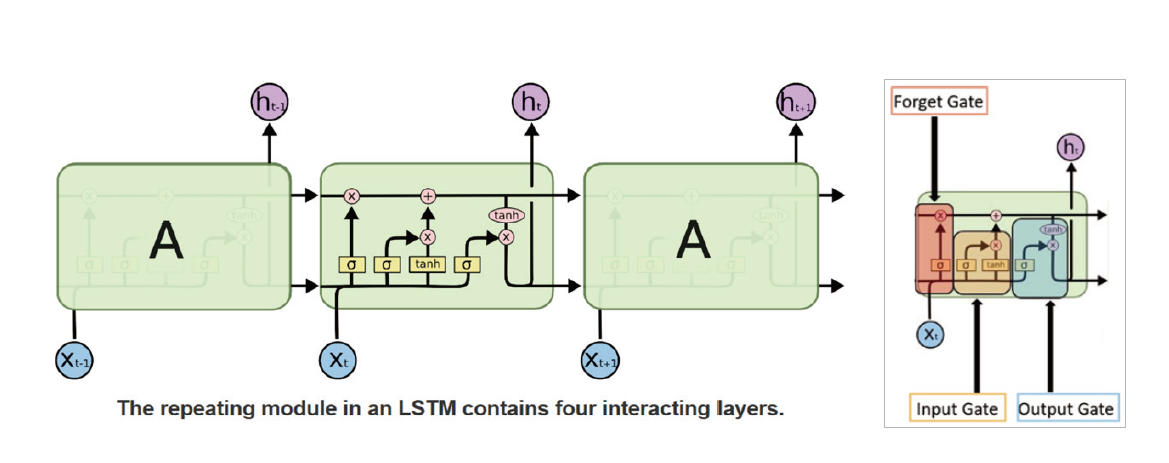
長短期記憶模型(LSTM)為一種特殊的遞迴神經網路(recurrent neutral network, RNN),兩者的區別在於普通的RNN(圖4)單個迴圈結構內部只有一個單元判斷產出資料[2]。而LSTM的單個迴圈結構(又稱為細胞)相比於RNN具有三個單元判斷,結構之間保持持久的單元狀態不斷傳遞下去,用於決定哪些資訊要遺忘或者繼續傳遞下去。
如圖5右,其中Xt為區塊的input,經由forget gate(決定是否遺忘此區塊資料)、input gate(決定是否執行資料產出)、output gate(決定在此區塊計算後的資料是否產出),進而構成資料運作的神經迴路。目前LSTM已在Google語音辨識、Google translator、股價預測及腦波監測等領域應用。
圖4、遞迴神經網路圖解[1]
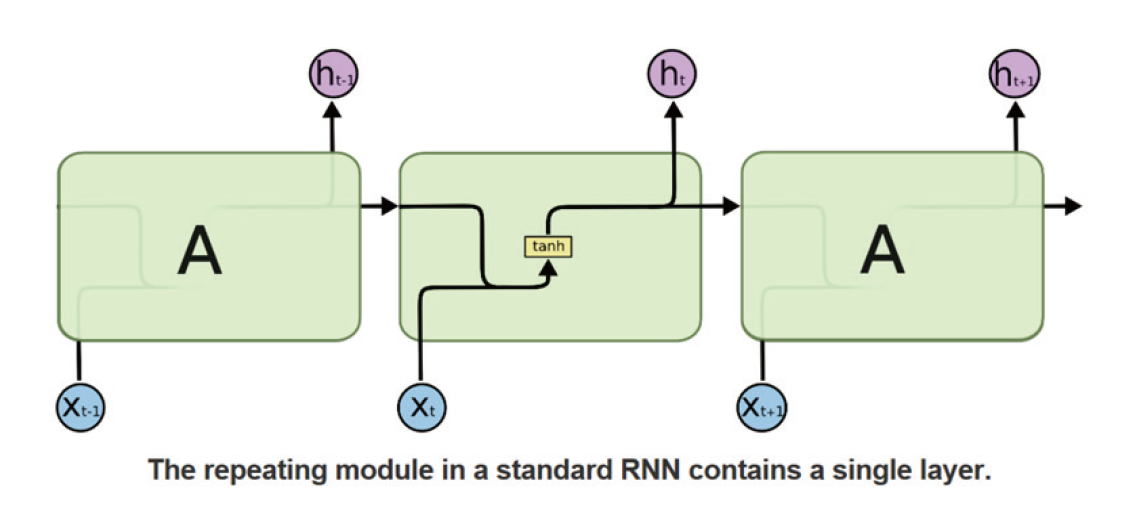
圖5、長短期記憶模型及其組塊結構圖解[1]
2.3.2 線性迴歸(Linear Regression)(圖6)
線性回歸是最基本的機械學習模型之一,透過資料以最小平方法算出已存在的關係並用y=b+ax二元一次方程式呈現,其中y為預測值、x為變數、b為截距而a為斜率,將變數(x)帶入方程式得到預測值y。[4]
2.3.3 極限樹迴歸(Extra Tree Regressor)
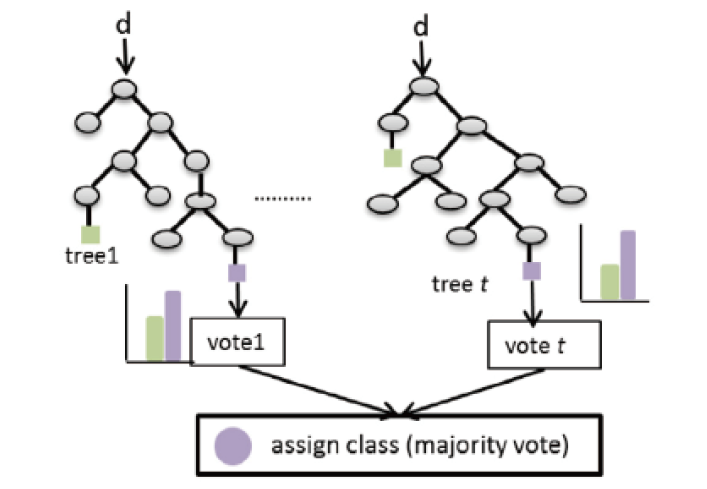
極限樹迴歸是由隨機森林分類Random forest classifier(RF)[5]衍生而來,RF的原理是集合多棵分類樹CART(classification and regression tree),每個CART都是一個分類邏輯,並在bagging(選擇特徵資料)及boosting(對錯誤加強練習)基礎下累積形成具多樣性的「森林」,如 圖7,最後由各個樹得到的結果進行majority vote,而算出預測值。極限樹模型在子模型的選擇更加隨機,各CART的變異性下降,最後再集結大量決策樹形成學習模型。
圖6、Linear regression圖解[3]
圖7、隨機森林分類圖示(d=new data)[5]
2.3.4 支持向量迴歸(Support Vector Regression)
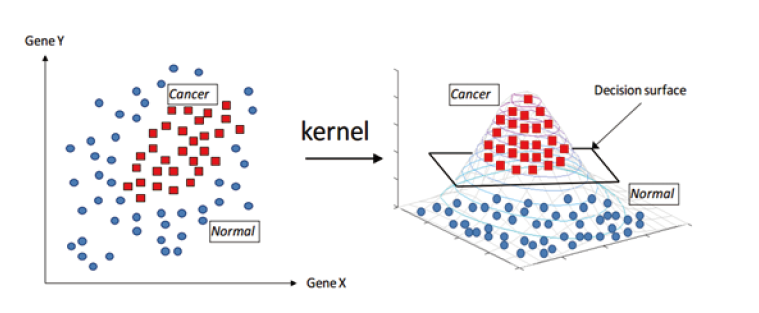
支持向量迴歸是藉由建立一個分類(決策)基準將資料分成兩類,如 圖8,找出與每個點總和距離最小的超平面(「超」的意思為分析的資料不只有二維),以得到最有效的資料分類準則,並由此準則算出預測值。[6]
圖8、一維線性SVR(Source:WikiDoc.Net)
2.4 機器學習模型成效驗證KPI
平均絕對百分比誤差MAPE(mean absolute square error)及均方根誤差RMSE(root-mean-square error)為兩個驗證模型有效性及準確性指標[7]。兩者計算出的數值愈小代表預測結果和實際值愈接近。
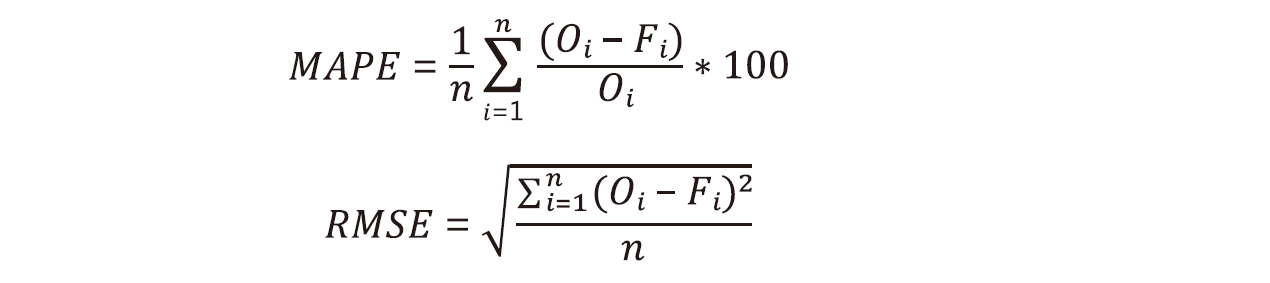
Qi=偵測AMC濃度數值;Fi=預測AMC濃度數值;n=window size(可視為資料量大小)。
2.5 汙染源成因分析
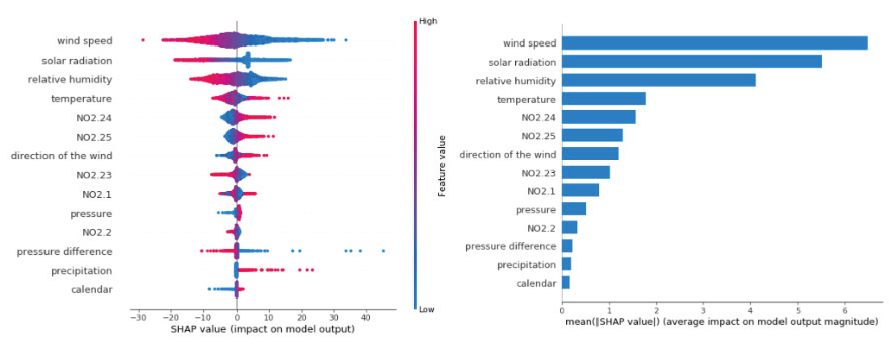
SHAP(Shapley Additive exPlanations value),是種常見的對於機器學習結果解析的方式。通過計算歷史資料的平均來解釋特徵變數(x)對於預測值(y)的相關性,並將結果視覺化列出如 圖9,最大(正或負)相關性其feature value越高,由大到小列出即會如 圖9(右)。[8]
圖9、SHAP成因分析[8]
3. 研究方法
3.1 參數相關性分析
為得到能夠呈現真實現狀的資料,首先針對欲分析參數進行概觀檢視,去除偏離值,避免人為誤差、儀器誤差干擾,最後便能得到「乾淨」的資料組塊進行分析[9][10],如 圖10進行FAB L30 BS tool FI acetone資料分布解析。將資料整理乾淨後,利用heatmap進行對象參數的相關性分析,提供視覺化的資料矩陣決定目標參數,如 圖11。
圖10、FAB L30 BS tool FI acetone資料群分布分析
圖11、heatmap Tag關聯性分析
3.2 濃度預測模型測試
將基本AMC監測數據分成11種不同群類匯入模型訓練,預測目標為三天後MAU出口丙酮濃度,整個時間區間中的80%作為訓練,20%進行預測測試,訓練模型包括線性迴歸、長短期記憶模型、極限樹迴歸、支持向量迴歸,以RMSE、MAPE作為KPI,數值愈低者代表預測與實際數值誤差愈小,愈適合作為AMC訓練模型。
將訓練模型訂定後,匯入更完整的相關參數群(共137tag),並針對參數特性進行上下限訂定,針對PM進行內插法補值,以避免極端離群值影響預測。另外亦新增風量*濃度=質量流速作為虛擬點幫助預測。
3.3 汙染源成因分析與GUI建立
利用SHAP value對模型預測結果進行分析,根據影響因子相關性排序。並將濃度預測以及汙染源成因分析結果結合建立GUI(graphical user interface),透過專家feedback讓模型更加成熟。
4. 結果與分析
4.1 模型訂定
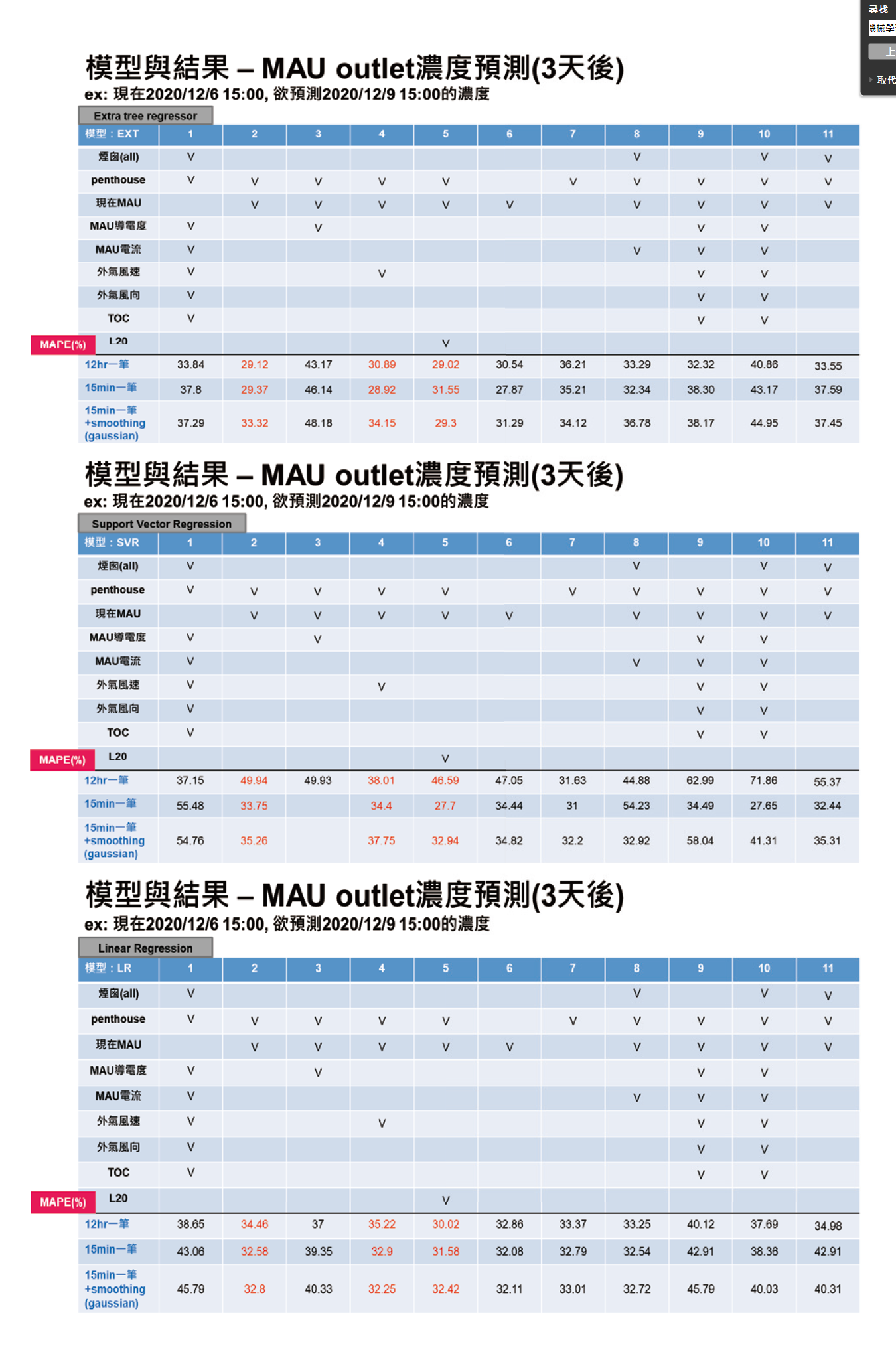
模型預測的結果如 圖12所示,在四種訓練模型中,extra tree regressor的第2/4/5參數群對應的MAPE是最小的,約30.00%,顯示易受多重因子影響(特別是外氣)的AMC適合使用extra tree regressor這種隨機性高模型對不同外氣影響因子形成一個隨機樹,再由多數者決定最終結果。第4參數群,亦與實際情況相符,風速/penthouse/MAU出口分別代表著外氣條件及迴風路徑上下游的關係,因此關聯性相較其他參數群大(MAPE相對小)。而其他MAPE大於35.00%的參數群包含了MAU導電度,推測因其排補水控制邏輯為望目,且丙酮(極性有機化合物)對於MAU無法貢獻導電度,因此多加入此參數後MAPE%的表現較差,也可得到資料群須針對其特性適當篩選以保持資料乾淨度。最後,在包含煙囪的參數群(1/8/10/11)裡,extra tree regressor的MAPE表現亦為最佳(33-40%),代表能有效的將MAU出口(target)和汙染源相關性連接,因此將extra tree regressor設定為預測訓練模型。
圖12、Extra tree regressor/Support Vector Regression/Linear Regression模型預測結果
4.2 預測結果及汙染成因分析
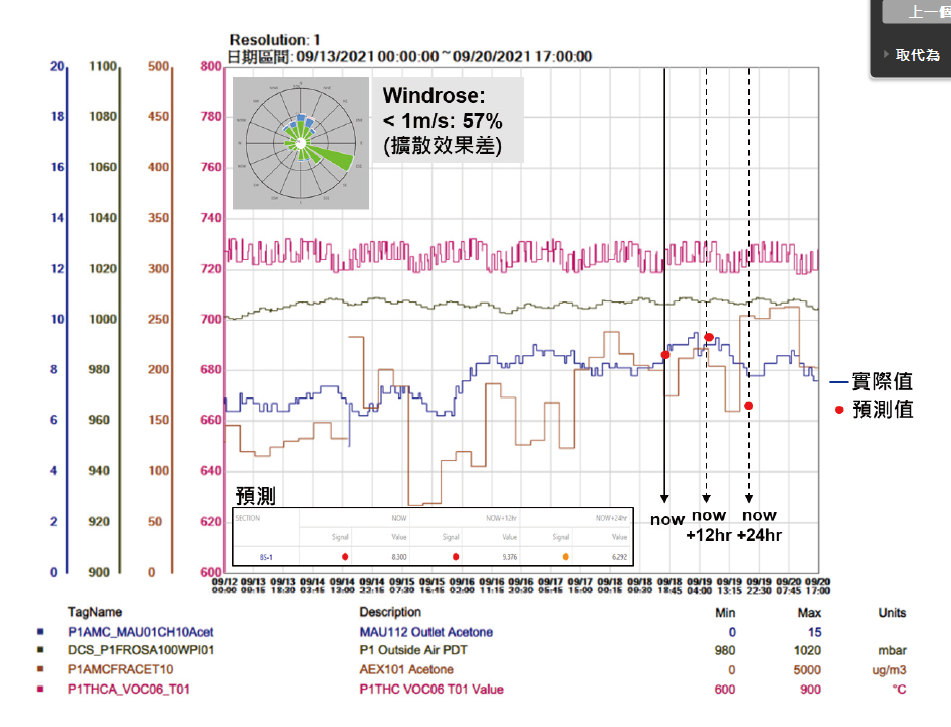
將更多相關參數匯入後(137參數tag),RMSE/MAPE有大幅度的進步,如 圖13,RMSE由2.17降至1.17(整體46%降低),MAPE由29.37%降至12.27%,顯示出將具有相關性的資料規模擴增,是有助於預測準確度的增進。而濃度預測以及汙染成因分析的GUI如 圖14所示,上半部的為預測MAU112出口(主要供給區域為BS-1)在未來24小時的丙酮濃度(單位ug/m3),下半部為汙染源成因分析,將經由SHAP計算過的參數依權重列出前三名。9/18/2021的預測結果顯示現在/12小時後/24小時後數值分別為8.300/9.376/6.292,實際值分為8.300/9.000/7.800,如 圖15所示,趨勢類似,但數值仍有誤差(+12小時 : +4.2% ; +24小時 : -19.3%),可能的原因推測為時間區間仍不足,相較於股價預測文獻[7]蒐集十年的資料量,一年多的資料量相對不足,加上季節效應,需要數年的資料讓模型學習不同大氣條件下的AMC模式。成因分析部分,前三大影響參數分別為大氣壓力、AEX101丙酮出口濃度及VOC06 T01溫度,比對與MAU出口相關性,大氣壓力和VOC06T01較無明顯對應趨勢,而實際上大氣壓力應與MAU出口丙酮濃度呈相反趨勢(秋夏季氣流沉降擴散條件差,冬季東北季風強勁擴散條件佳)。而AEX101位於MAU112鄰進位置,在57%以上時間風速小於1公尺/秒條件下排放丙酮將可能被吸回penthouse,因此分析與結果相符。 在經由AMC預測提供預警功能,幫助提早進行防禦並改善汙染源(例 : Salix bio生物系統風管AEX改至VEX),在alarm rate部分2020年與2021年相比,由1.088%(1491/137015)降至0.582%(1563/268358),46.5%幅度的降低。
圖13、參數完整化前後RMSE/MAPE比較
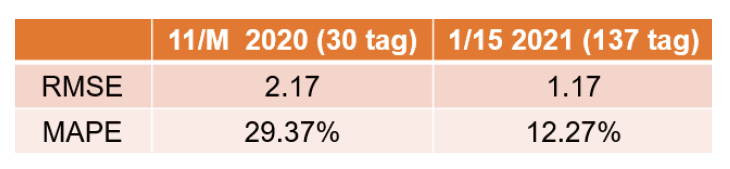
圖14、AMC預測及成因分析GUI
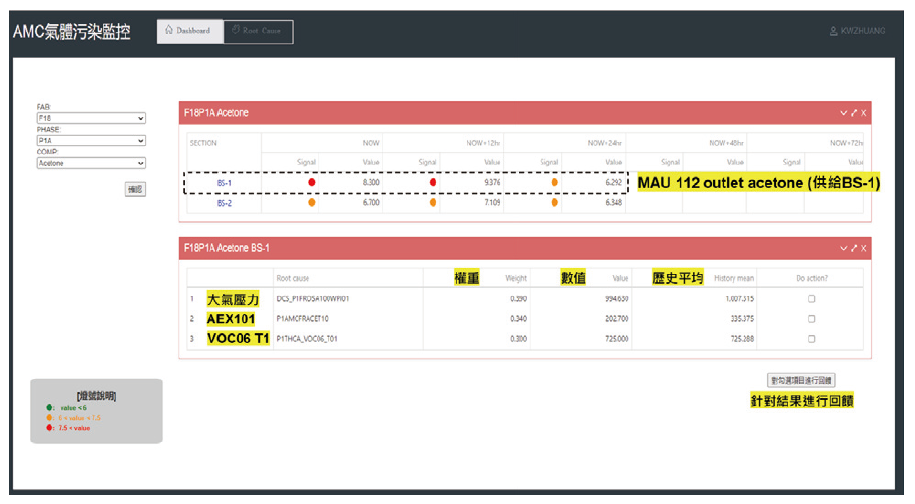
圖15、AMC+12/24h預測值與實際趨勢圖
5. 結論與未來展望
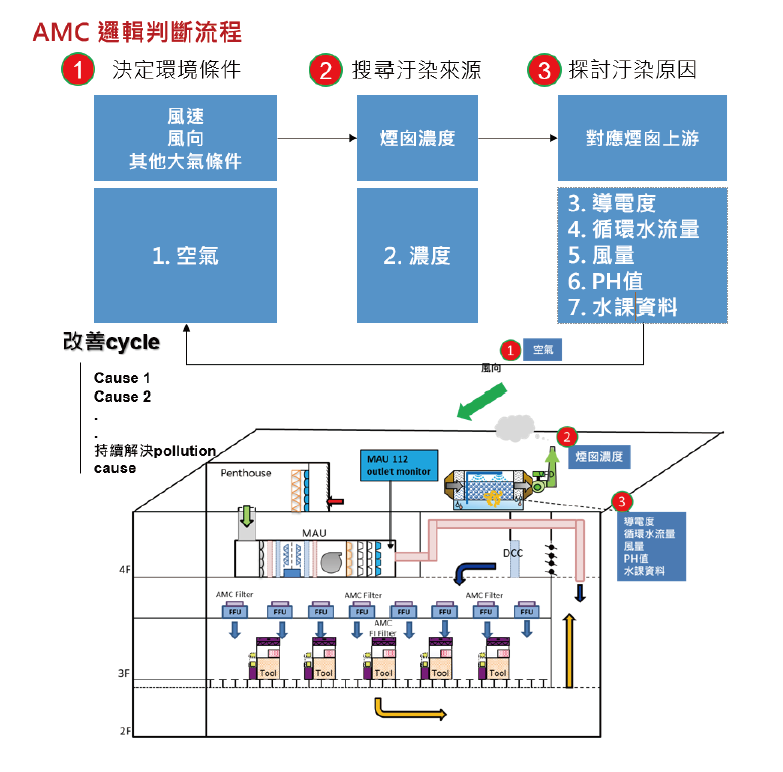
本研究將資料來源經過篩選前處理(共137tag),並使用extra tree regressor進行AMC濃度預測模型訓練,得到RMSE為1.17,MAPE為12.27%,並利用此模型幫助AMC防禦,alarm rate由2020年1.088%降至0.582%,顯示是具有效益的模型,但有以下三個面向須更加精進,第一,相比成熟的機器學習預測資料時間區間短(股價預測約需10年以上資料[7][11]),加上AMC季節效應,仍需更多時間讓模型成熟。第二,汙染源成因分析須將對象參數篩選處理,如 圖16所示,先決定外氣條件再判斷貢獻汙染煙囪來源,最後再判斷煙囪上游相關參數,對於極限樹模型而言,亦能夠根據實際迴風路徑上下游關係,建出接近現實邏輯的隨機樹排列。最後,可加入其他MAU以及compound預測及分析,由不同compound的煙囪排放濃度判斷當下大氣條件影響的範圍,更可以鄰近MAU交叉比對,增進精準度。展望未來,若能將以上提及面相改善,搭配現有自動預警信件發送,將有效減輕人力物資的使用並進一步運轉成本。
圖16、AMC循環改善邏輯判斷流程
參考文獻
- Oinkina, Understanding LSTM Networks, 2015.
- Yong Yu, Xiaosheng Si, Changhua Hu, Jianxun Zhang, A Review of Recurrent Neural Networks: LSTM Cells and Network Architectures, Neural Computation, 31(7), 1235–1270.
- Elle Knows Machines, LINEAR REGRESSION: THE BEGINNER’S MACHINE LEARNING ALGORITHM.
- Dastan Hussen Maulud, Adnan Mohsin Abdulazeez, A Review on Linear Regression Comprehensive in Machine Learning, Journal of Applied Science and Technology Trends, 01 (04), 140-147.
- Mariana Belgiu, Lucian Dra˘gut, Random forest in remote sensing: A review of applications and future directions, ISPRS Journal of Photogrammetry and Remote Sensing, 114, 24-31.
- ALEX J. SMOLA, BERNHARD SCHO¨ LKOPF, A tutorial on support vector regression, Statistics and Computing, 14, 199-222.
- Mehar Vijh, Deeksha Chandola, Vinay Anand Tikkiwal, Arun Kumar, Stock Closing Price Prediction using Machine Learning Techniques, Procedia Computer Science, 167, 599-606.
- María Vega García, José L. Aznarte, Shapley additive explanations for NO2 forecasting, Ecological Informatics, 56 (2020), 101039 .
- Tauno Metsalu, Jaak Vilo, ClustVis: a web tool for visualizing clustering of multivariate data using Principal Component Analysis and heatmap, Nucleic Acids Research, 43(1), 566-570.
- VICTORIA J. HODGE, JIM AUSTIN, A Survey of Outlier Detection Methodologies, Artificial Intelligence Review, 22, 85-126.
- Jigar Patel, Sahil Shah, Priyank Thakkar, K. Kotecha, Predicting stock and stock price index movement using Trend Deterministic Data Preparation and machine learning techniques, Expert Systems with Applications, 42 (1), 259-268.
- Peng Sun, Caroline Ayre, and Matthew Wallace, Characterization of Organic Contaminants Outgassed from Materials Used in Semiconductor Fabs/Processing, AIP Conference Proceedings, 245(2003), 683.
- Decheng Kong, Chaofang Dong, Aoni Xu, Cheng Man, Chang He & Xiaogang Li, Effect of Sulfide Concentration on Copper Corrosion in Anoxic Chloride-Containing Solutions, Journal of Materials Engineering and Performance, 26, 1741-1750(2017).
- Oleg Kishkovich, Anatoly Grayfer, Frank V. Belanger, Contrarian approach to and ultimate solution for 193nm reticle haze, Metrology, Inspection, and Process Control for Microlithography, 6518.
- Jürgen M. Lobert, Philip W. Cate, David J. Ruede, Joseph R. Wildgoose, Charles M. Miller, John C. Gaudreau, Advances in the understanding of low molecular weight silicon formation and implications for control by AMC filters, Metrology, Inspection, and Process Control for Microlithography, 7638.
- SEMI F21-1102 classification of airborne molecular contaminant levels in clean environments.
- ISO-14644-8 Cleanrooms and associate controlled environments– Part 8: Classification of airborne cleanliness by chemical concentration.
- INTERNAIONAL TECHNOLOGY ROADMAP FOR SEMICONDUCTOR 2.0 – 2015 EDITION – YIELD ENHANCEMENT.
留言(0)