摘要





前言
隨著科技不斷進步,資訊串流、大數據分析等智慧工廠相關應用技術已經成為先進半導體廠攻城掠地的的重要指標之一,依循半導體製程世代的演進,機台不斷進化,面對Fab不間斷的拆移機需求,廠務工程師如何維護底層基礎數據,例如:廠務供應分佈總表bluebook[附註1],並即時應用運轉資訊與管理監控警報已成為廠務守護工廠運轉成敗的重要因素[1]。
雖然廠務供應系統已有完整網域監控架構,但運轉警報、要酸訊號及bluebook為各自獨立系統並無互相連動,且往往因為設備系統商不同,造成監控網域各自平行運作,當異常警報觸發時無法執行橫向資訊交換,警報影響範圍及機台相關資訊都需要由人力查閱,導致值班應變時間加長,造成影響範圍擴大[2],故本研究期望藉由監控系統的資訊串流來解決目前運轉數據多而無用的狀況。
文獻探討
系統整合
何謂系統整合?系統整合不是單純地使設備互相連結,亦不是一昧地採用自動化及數位化技術就可以成功,背後的管理深思:重點不是自動化,而是工廠的統一大腦[3]。系統整合有如給予機台與機台間統一的工作站,並將工廠內各式設備連結在一起,舖設神經系統、即時汲取所有資訊,利用網路連結串聯一切工廠大小事,期望實現即時、共享、統一化等數據交流[4],而其中兩點尤其重要:工廠內各項運轉資訊的可視化與數據間因果關係的明確化。
廠務系統中,設備多以及DCS、InTouch等系統對PLC進行監控,在介面上都是各自獨立的系統。由於設備的供應商不同、通訊協定不同等因素,無論在技術或架構上,都沒有整合在一起。一旦各系統之間需要合作及共享資訊時,只能透過各系統產出的報告,實際經由人力分析的實體形式,滿足系統間合作與分享資訊的需求,這時若發生格式差異與更新版次落差的狀況,會造成系統失效與使用者信賴度降低,長期即容易造成現場資訊與資料庫無法同步的狀況發生,使運轉數據無法有效利用[5]。
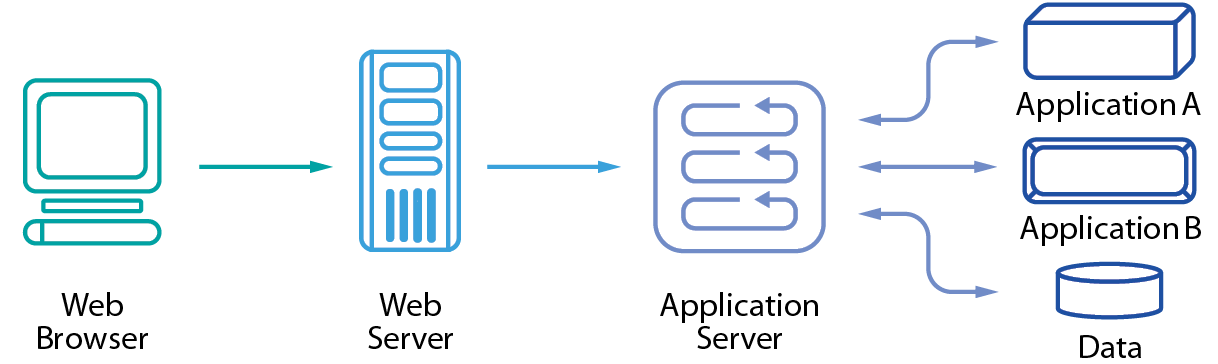
David S.Linthicum 於資訊系統整合提出「入口網站導向整合」技術[6],入口網站導向整合即是將每個系統的使用者介面結合成單一介面,如 圖1。所有系統的資訊可於此入口網站查詢、比對,而資訊間可視化、透明化也讓廠區的連結更加穩固,利用「入口網站導向整合」技術將廠務系統資訊串流,進而達到單一窗口、多工處裡的目標。
圖1、單一入口網站導向整合[6]
基礎數據整合
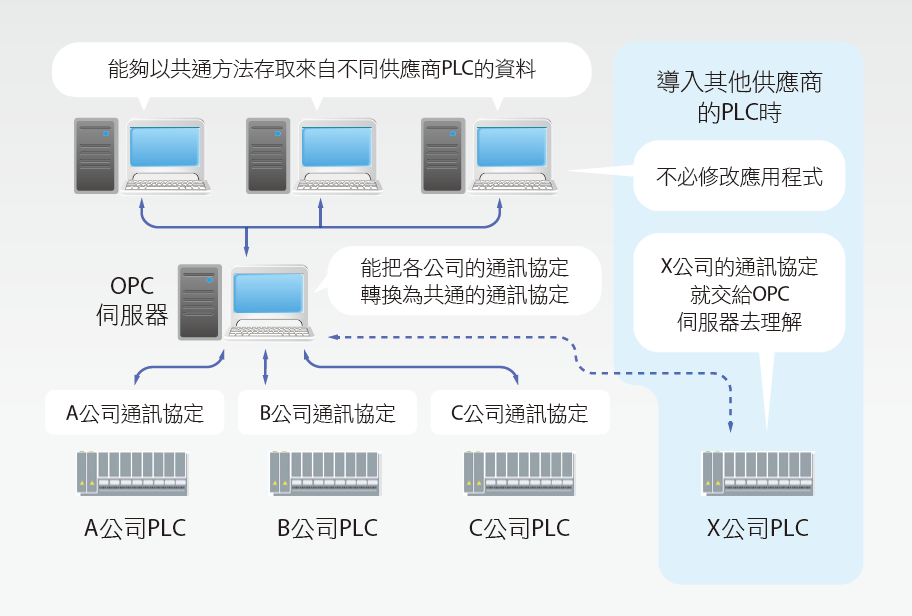
智慧工廠(清威人撰) [3],其中說明自動化廠房管理,設備與設備間資訊串聯的方法與重要性,提及以OPC (Object linking and embedding for Process Control)為基礎,讓一般電腦系統與工業網路系統得以鏈接,OPC的作法就像驅動程式(Driver),過去PC技術尚未成熟時,週邊設備並沒有一套可以完全相容的程式產生,終端的設備要與工業網路互連,就必須針對該網路開發對應的驅動程式,而工業網路規格眾多,要逐一開發太過曠日廢時,如果使用OPC標準,就可以讓所有自動化設備,在同一部伺服器互連,打破以往封閉的通訊環境。
目前廠務各設備監控網域各自獨立,不同設備資料交換會受通訊網域限制,而OPC server可串聯多家通訊協定,打破封閉的通訊網域,為了讓多家PLC與電腦間更容易交換資料而訂定的共同介面,能夠排除不同供應商之間通訊協定差異帶來的隔閡,成為共通介面(同口譯般的存在),如 圖2。
圖2、OPC server整合各廠商通訊協定
數據基礎建置-底層數據(bluebook)正確性及點位(Tag)標準化
數據應用之前,須先討論數據基礎的議題,從數據源頭建立規則開始,以F12P45廠務化學供應系統為例,隨著RD製程不斷演進,廠區設備拆移頻繁,bluebook時常因拆裝機需求而更新,除了硬體管路實際變更之外,廠務與設備機台間的溝通訊號也會重新銜接,目前資料更新方式為負責人手動更新資料,無自動確認機制,往往到後端應用時才發現資料缺損的狀況,造成bluebook的正確率永遠無法達到100%。故於底層資料的建置及更新為後續各種發展必須優先考慮的問題,以運轉管理而言,良好的資料更新模式應包含下列幾種基本概念:
數據專一
字串於資料庫中保持一致性,同一個名稱於不同表裡定義相同。
數據標準化
所有的運轉相關點位(Tag)皆須明確定義字串表示方法,以便日後數據探勘使用。
整體資料需要有架構思維
在數據不斷擴張的狀況下,冷數據與熱數據進行拆分、數據字段的擴展,必須明確定義數據間的分層架構。
工具化與自動化的能力
資料更新工具平台的建立及自動判斷資料可靠度,確保後端進行數據擷取時,能正確的分析判斷。
資料探勘
建立底層數據後,接著如何有效及正確使用這些資訊,可利用「資料探勘(Data Mining)」來進行,此方法是一種專門的程序,可在龐大的資料庫中,將多而複雜的運轉資訊,有效歸納並利用,將數據資訊建立一個預測或分類的模型,亦可以進行識別不同資料庫之相似性,產生的資訊可協助使用者進行更周延的決策。
資料探勘的工具是利用資料以建立一些模擬真實世界的模式(Model),利用這些模式描述資料中的特徵及關係。這些模式有兩種用處,其一為瞭解資料特徵與關係的關聯模式(Association Model),以提供決策時所需資訊,例如幫助Fab SP2供應需求的快速排點;其二為資料特徵預測,從bluebook清單中預測出特定警報最可能直接影響特定類型Tool,可快速縮小查詢範圍,增加應變速度,或是時間與供應系統的運作關係,例如在F-Charter上來建立系統健康模式,用來預測設備的健康程度。
資料探勘的方法共可區分為五種模式:
分類 (Classification)[7]
根據變數的數值做計算,再依結果作分類。從已分類的歷史資料中部份取樣,經由實際的運作測試,研究資料分類的特徵及規則,根據這些特徵建立模式,對其他未分類或是新資料做預測。
趨勢分析(Trend Analysis)
用現有的數值來預測未來的數值,其分析數值與時間皆有相關,用於預測事件及未來發展趨勢,並作出適當的分析與判斷。
分群(Clustering)[8]
將資料分組,目的是找出各組之間的差異及同組中成員的相似性,使群內差異小,群外差異大。
關聯(Association)[9]
在同一個事件中找出隱含在其中比對條件,更確切的說,關聯規則通過量化的數字描述某一事件出現對於後續行為的影響。
循序特徵(Sequence Pattern)[10]
循序特徵與關聯關係很密切,不同的是循序特徵中,相關項目是以時間來區分,找出某段時間內可預期的行為特徵。
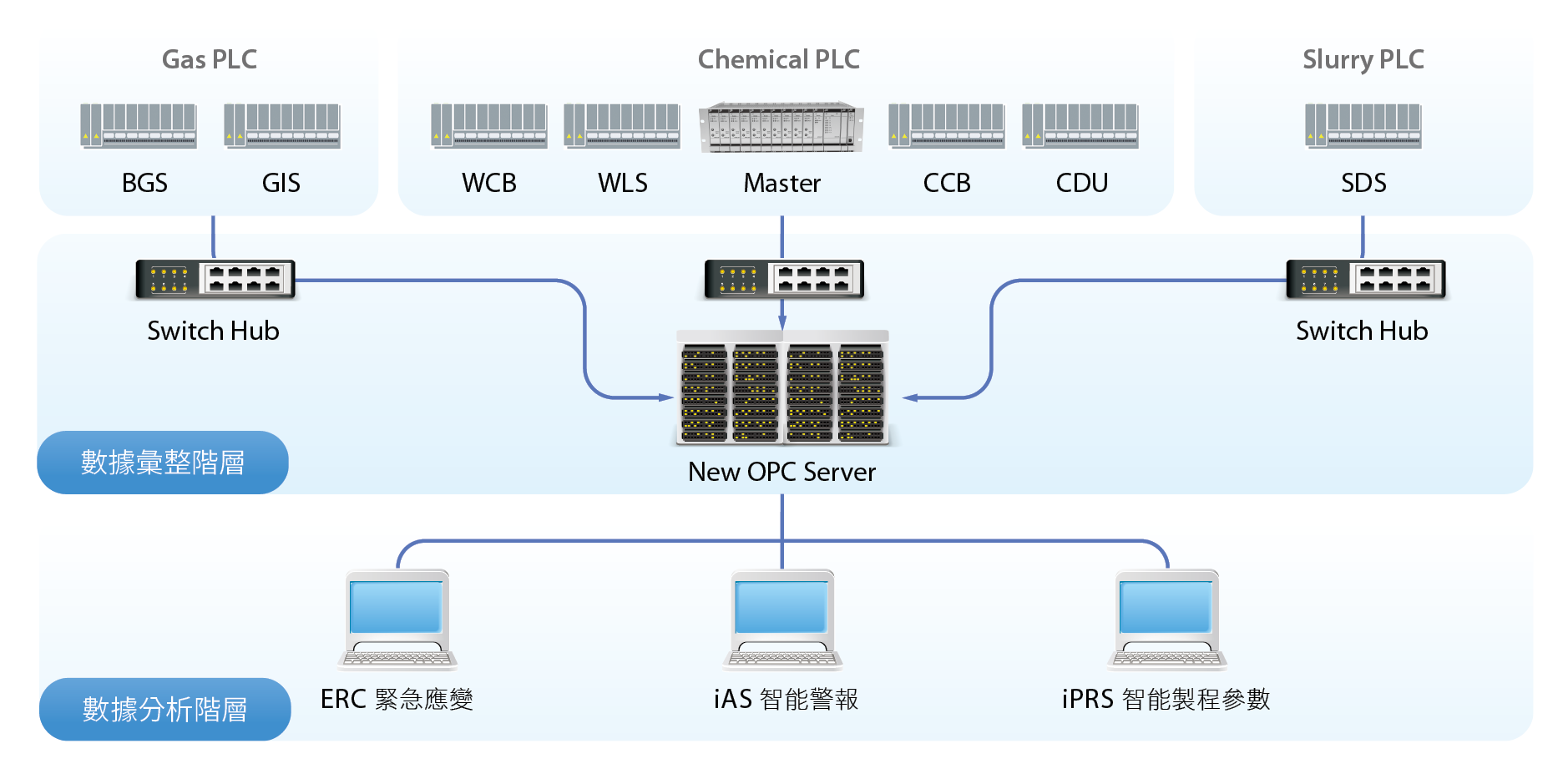
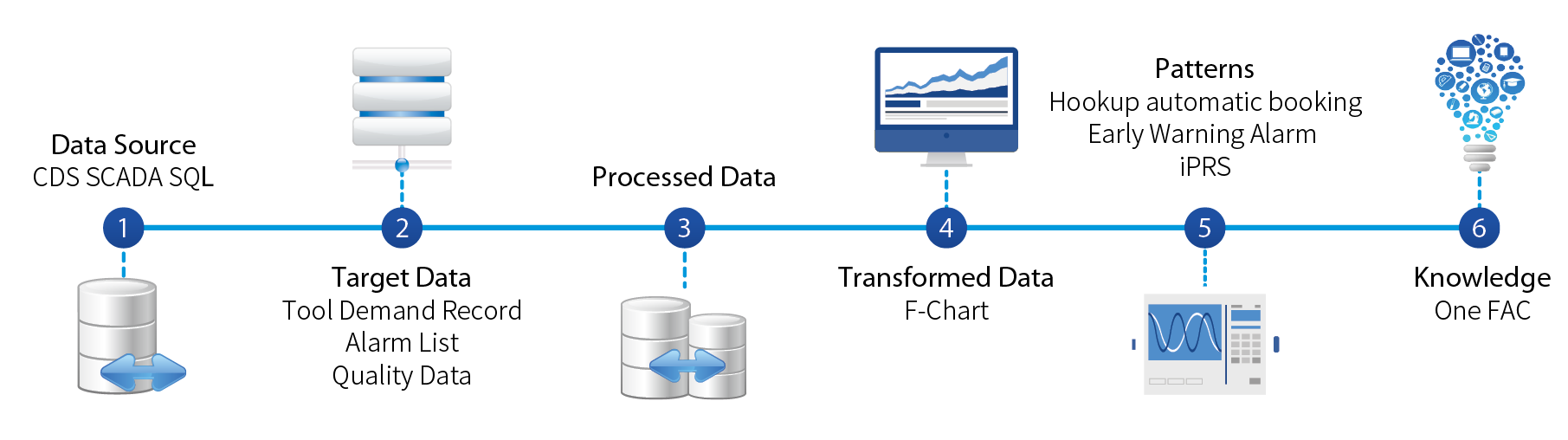
本研究利用OPC server建構基礎數據的儲存/轉換工作站,如 圖3,確保單一資料串流入口,打造統一的運作大腦,明確定義數據間分層架構關係與命名標準,確保底層資料的正確性,數據應用部分則以五種分類模式進行資料探勘,建構統一的數據串流中心(OPC server),藉由底層數據的正確性及標準化,汲取所有資訊,實踐工廠活動的可視化與資訊間因果關係明確化。
圖3、OPC整合系統架構
計畫方法
通訊協定整合方法
利用OPC為基礎,負責收集廠內所有可編程邏輯控制器PLC資料,依照分析種類分層管理,藉此突破InTouch擴充點數限制,及DCS反應速度過久的問題。以F12P45為例,目前運轉點數已達85%(51000/60000),Local InTouch除了運轉需求之外已無法再負擔額外監控點數需求,勢必需要另創「大腦」,負責整合各家廠商PLC資訊並加以活用,即藉以OPC系統達到「整合數據」及「預處理」的目的。
OPC server網域架構如 圖3所示,於資料彙整階層「大腦」直接與設備PLC進行資料交換,破除以往數據應用採人工餵點的方式,降低人力耗費與提升數據正確性,資料分析階層分別由四個工作站進行資料應用,依序為緊急應變、Hookup、智能警報、參數監控(iPRS)。
基礎數據建置方法與應用 (bluebook & Tag)
底層資料-Bluebook模組化增建點位:在化學供應系統中,bluebook即為底層資料重要的一環,在供應系統發生異常警報或ESH緊急應變處理時需要正確的Bluebook才能即時確認受影響範圍,異常狀況隨時可能發生,故建立Bluebook更新預警機制有其必要性,尤其是拆裝機頻繁的RD Fab。機台拆裝機時SP2 EMO的訊號線需解離或銜接,因EMO訊號設計為B接點,在進行訊號解離作業時必定會觸發Tool EMO alarm,如 圖4,可藉此警報做為Bluebook更新預警,Tool EMO alarm觸發後需確認機台是否再拆裝機,機台名稱是否修改。
圖4、SP2訊號接線圖
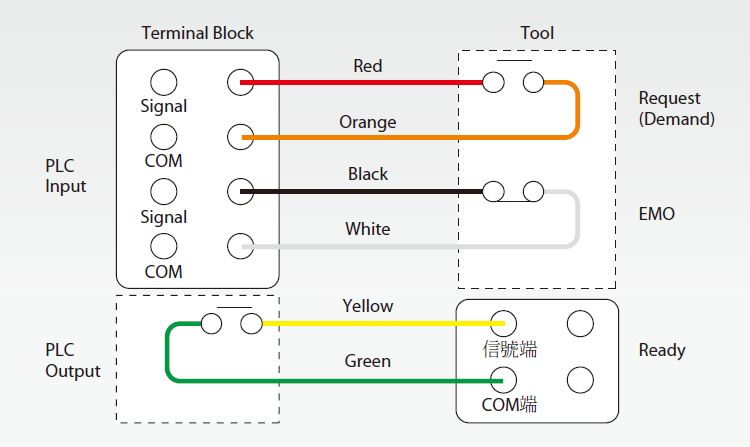
此更新預警機制可確保機台拆裝機時Bluebook會被更新。現行Bluebook是建置在各課公用資料碟上的Excel進行管控,無法直接與SCADA連動,Bluebook建置於SCADA server上,即可直接連動alarm,例如觸發Tool EMO alarm將同時觸發Bluebook更新確認警報,若未更新確認,警報系統會持續發報直到更新確認。
以即時更新bluebook為基礎,於Hookup排點即可利用此資訊進行擴充需求的確認,並強化系統使用率的控管,進而發展自動排點功能 圖5。
圖5、系統hookup使用率及自動排點功能
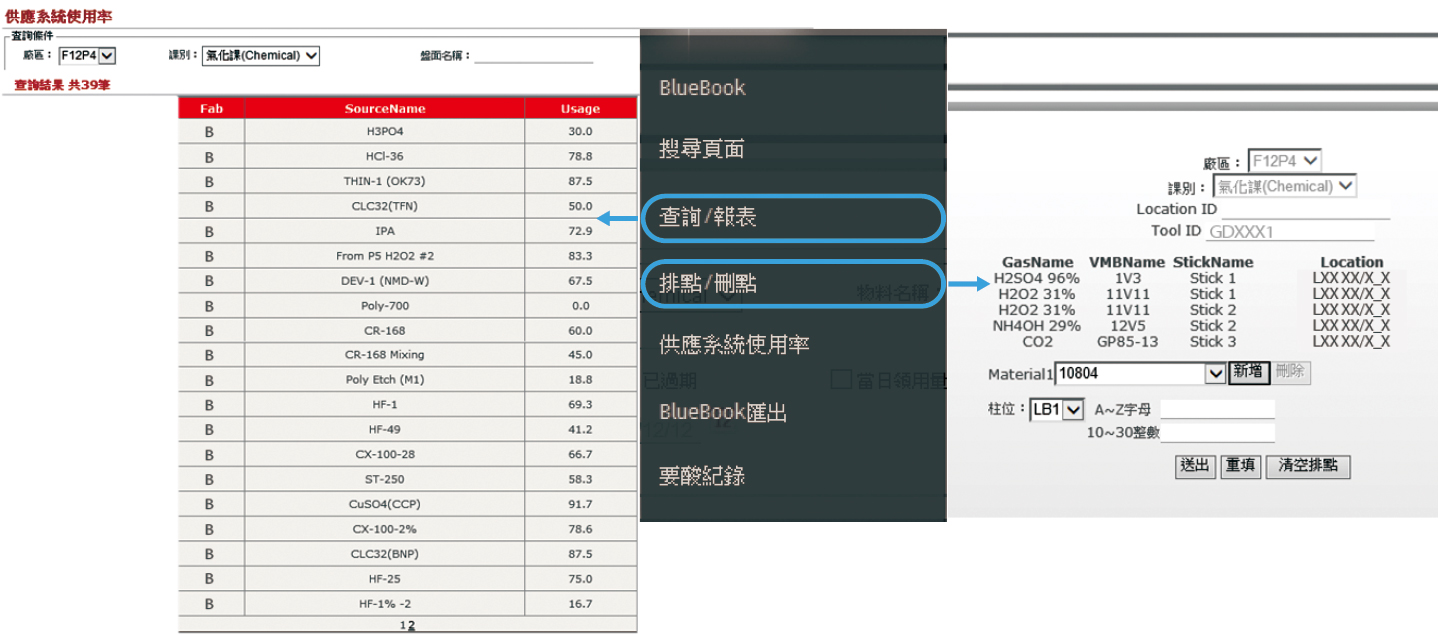
建立自動排點系統不僅可即時掌握使用率及各區域空點數量,於設備提出廠務需求時(FR),輸入機台資訊(Location ID)及需求chemical點數後,系統將自動完成排點及精準計算SP2距離,可大大減少排點作業時間;於新建廠時,RD Fab tool的Hookup自動排點系統資訊結合Hierarchy data將可快速精準地完成SP1 VMB佈點。
Bluebook建置是否完整目前亦有檢查機制,一為FHM Matching(%):Barcode System所自動產出的資料如Supply ID欄位亦會與Bluebook Supply Tool欄位比對,來檢查資料是否完整,資料完整度與iFag (插旗系統)啟動FAB Wet Particle量測有關。二為Bluebook(%):使用Hookup QC Report來比對該機台在Bluebook中的電、機、水、氣、化資料是否完整。
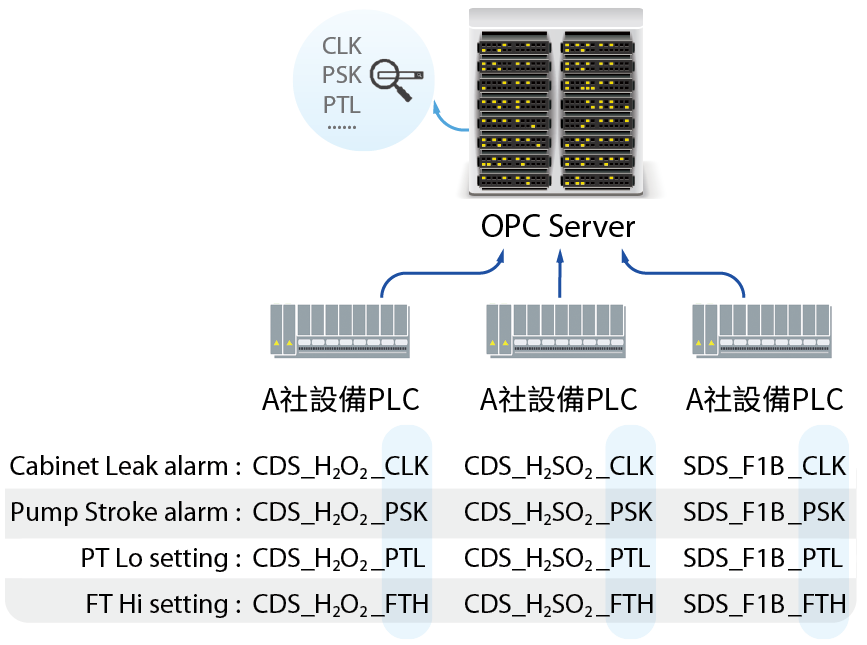
點位(Tag)標準化 – iPRS參數
系統運轉參數的設定決定系統如何運作,目前各廠區皆以人力建立系統的參數PRS表,確定各系統參數設定是否合宜,對於新建廠或製程技術轉移時特別重要。但PRS資料量大,且經手人又多,以人工方式難以維護。要自動化即時汲取所有資訊,首先底層數據(PLC Tag名稱)要先標準化,制定命名規則,將相同Tag名稱統一,如 圖6。標準化的Tag資訊儲存在Server後,利用入口網站導向整合,將各廠資訊串流並建立形成iPRS系統。iPRS系統可協助各廠區進行參數管理,功能包含系統參數查詢、每日參數變更管理、跨廠區參數比對。
圖6、Tag標準化
系統參數查詢
iPRS提供完整的廠務系統參數資訊,如 圖7,任何參數皆可進入網頁查詢,並且每日更新。使用者可於網頁平台花費1分鐘的時間查詢,省去過去人力抄表的麻煩。
圖7、iPRS系統參數查詢 (資料來源:OneFAC iPRS網站)
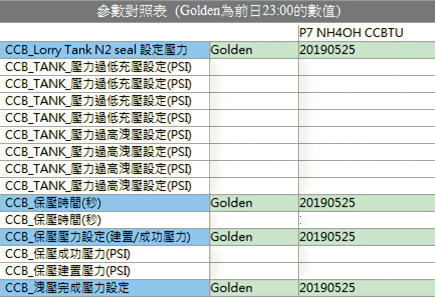
每日參數變更管理
iPRS每日會定期擷取現場資訊並更新比對前一天的參數值,若有差異就啟動提醒機制,使用者可快速查詢差異,如 圖8。
圖8、iPRS每日參數變更管理 (資料來源:OneFAC iPRS網站)
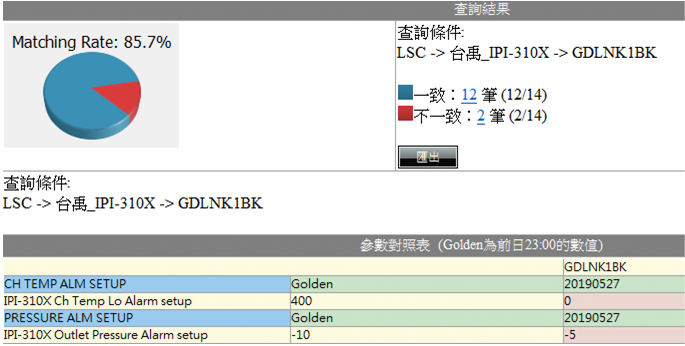
跨廠區參數比對
跨廠比對可將不同廠區、系統的相同參數項目列表呈現,讓使用者可以一目瞭然比對差異,進而執行參數最佳化設定,如 圖9。
圖9、iPRS跨廠區參數比對 (資料來源:OneFAC iPRS網站)

資料探勘 (Data mining) 方法
資料探勘方法如下圖所示,藉由正確的基礎數據,在大量的資料中找出共同的規則及模式,如 圖10。
圖10、Data mining 運用於化學供應系統流程關係圖
分類
化學供應監控系統中,根據同種類的訊號進行計算(流量、壓力、pump做動次數…),分類及分析特徵(瞬間用量、pump切換...),再根據這些特徵建立模式,未來新系統進來時,便以特徵進行分類,對接下來可能發生之行為,進行預警,及統計分析,如 圖11。
圖11、CTU供應每月及每日transfer效能盒鬚圖
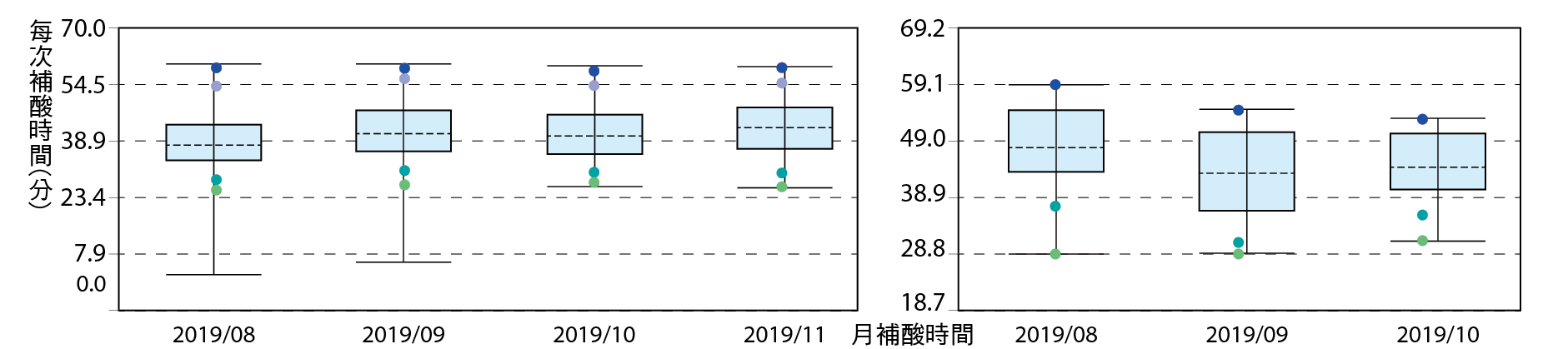
趨勢分析
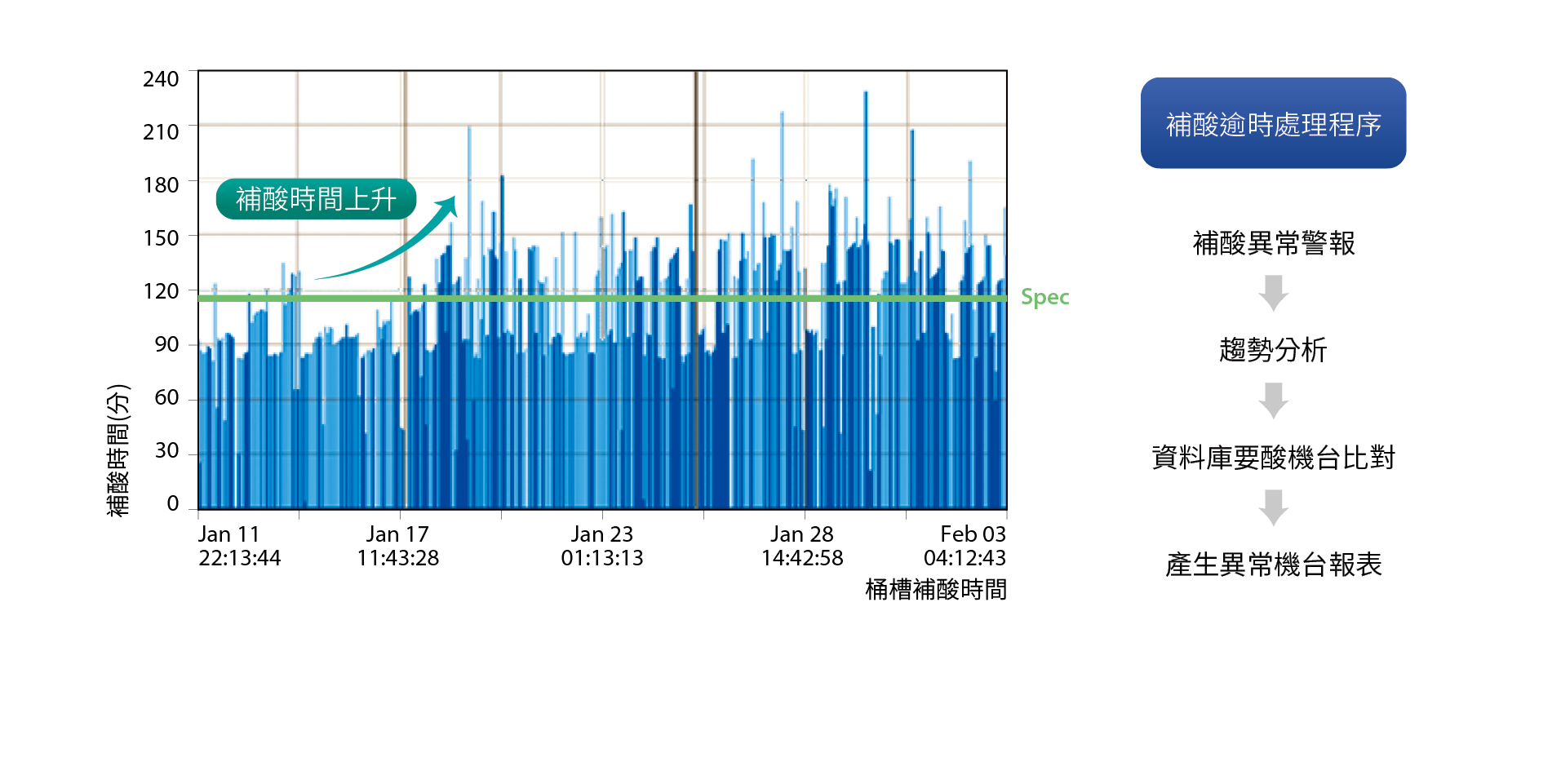
系統長期供應趨勢為依據每季用量成長幅度來評估下一季因產能增加而所需的擴充容量(Capacity),或將去年的總量與今年總量作比較,進行趨勢推論,且找出差異分析其原因,並有效的因應變化。短期趨勢可依據每周或每天的使用變化量,可針對短期變異進行應變措施,如 圖12。
圖12、補酸趨勢分析與逾時處理程序圖
分群
在同一種化學供應系統中,將bluebook 進行樹狀層級的分類,同一枝幹之資料歸類為群組使其階層化,於釐清設備影響範圍時可快速收斂目標,並對應設備需求紀錄(tool demand record),判斷影響狀況,進行故障診斷與應變決策。
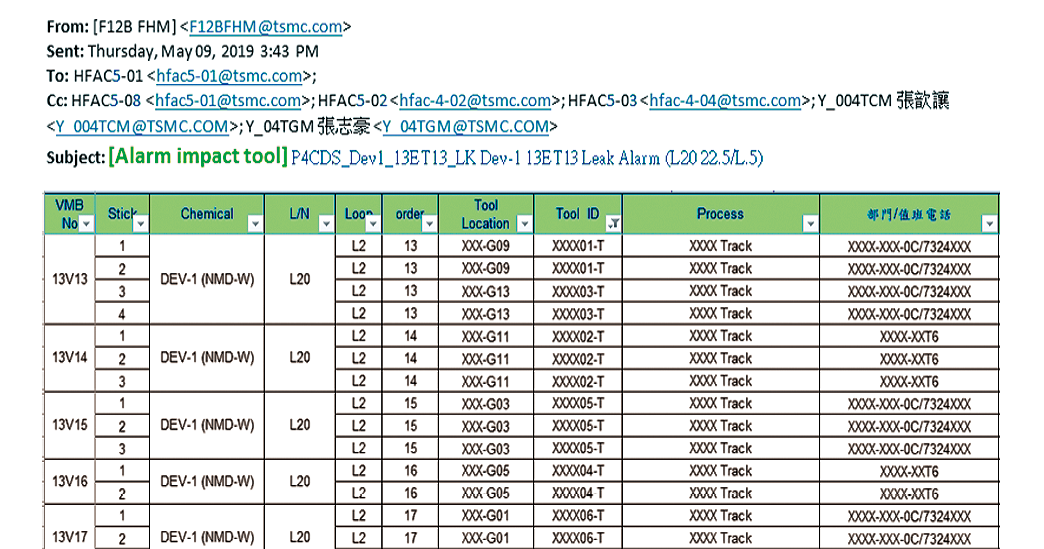
緊急應變第一時間「影響範圍」攸關全廠生產,若底層資料維護正確,搭配即時通報系統顯示廠務供應機台到VMB供應分佈狀態、影響範圍、設備機台資訊、相關對應窗口並引導工程師緊急應變處理,可大幅縮減應變時間,將事件影響降至最低,如 圖13。
圖13、異常事件發生,Mail自動通報影響範圍
關聯
關聯行為套用於系統警報前後級關係中,例如化學供應系統壓降往往跟pump效能異常或CDA/N2來源異常同時發生,亦或是Drain pump 逆止效能不佳造成Drain box 排液時間花費過長,皆為前後級關係,故將同類型數據以關聯的觀念討論,於系統上將具有前後級關係的指標連結,可增加事件判斷的速度。
循序特徵
以關連方式產生出來的指標,搭配時間區段尋找特徵行為,使原本無法由監控發現的數位訊號(僅On/Off),轉換為類比指標(analog)。例如在供應系統壓降事件發生前,有30%的機率在過去一個月中有頻繁的pump stroke情形,即是將關連因子,以固定時間區段來分析,達到歸納真因的目的。
以上述五種模式進行資料探勘與持續擷取資訊,並對新資料進行推理與規則建立,如 圖14,提升系統工具化與自動化的能力,及建立機器學習的基礎。
圖14、建立規則並利用資料探勘進行系統預先診斷[1]

結果與分析
依本研究規劃的硬體架構,以OPC server統一各介面語言後,建立bluebook正確性及Tag標準化,並利用Data mining的資料建立後,歸納出5種結果。
「分類」特徵應用 - iPRS應用探討
根據Tag標準化發展出的iPRS系統可利用參數比對功能進行系統管理,系統參數依其重要性可歸納進行分級管理。
第一級參數
影響供應品質相關參數如品質監控範圍設定值,有變更可能造成品質差異,故定義為完全不可更動參數。一但變更iPRS會立即提醒。
第二級參數
監控系統穩定運轉的警報設定值,會影響系統穩定度不可隨意更動,但如特殊狀況操作時可以暫時更改於操作後復歸,變更後一定時間內未復歸iPRS會發出提醒。
第三級參數
系統PM操作時可依情況有所變更之參數,於PM前後比對參數設定差異並蒐集每次設定值可歸納整理PM落實度。
參數的分級可以看到第一級參數為影響供應品質參數,廠務供應系統的首要目標就是維持供應品質,故第一級參數為進行新廠區或跨廠區製程技術轉移的重要參數。可運用第一級品質相關參數定義供應品質指標,此指標不受系統差異影響可直接複製,即使各廠區參數設定不同但品質指標必須相同。以下為化學供應系統供應品質指標。
供應品質量測控制範圍
在研發製程階段會定義製程物料品質控制範圍,後續會依照產線製程良率將控制範圍縮小至最佳,以確認供應品質相同。所以各廠區設定必需一致,透過iPRS系統可一覽各廠區設定值,若有變更也可立即通知。。
供應壓力、流量
供應系統的供應壓力與流量會影響製程的物料用量,必須穩定輸出,依照製程不同,廠務依其需求設定壓力與流量範圍確保穩定供應。
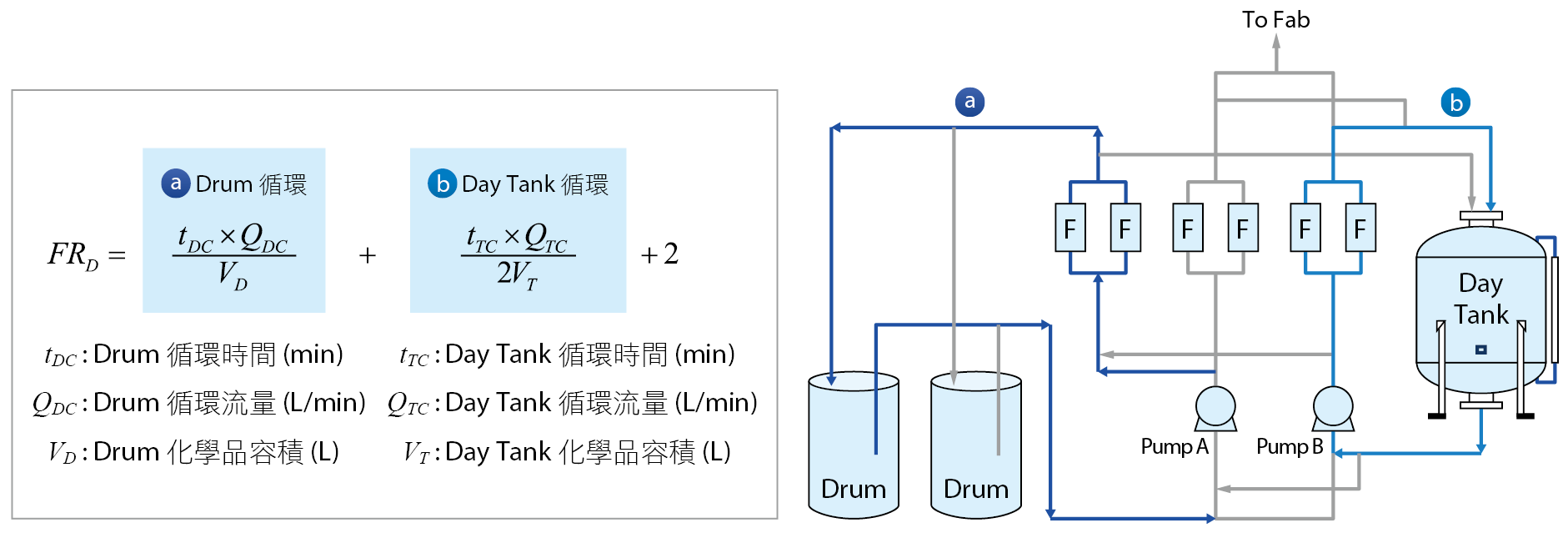
循環過濾值
廠務系統具有對原物料循環過濾的能力,去除原物料中的不純物,為達到相同的過濾效率,每一單位物料過濾時間應該要相同。受限於各系統硬體差異,不單只是設定相同循環參數,須將外在因素納入考量,為此新增一循環過濾計算公式,包含桶槽容量、循環時流量、時間的計算結果,如 圖15。循環過濾值可將過濾效率數字化,各廠可參照iPRS依研發製程廠的循環過濾值去設計與設定循環模式,達到相同的過濾效率。
圖15、循環過濾值計算公式
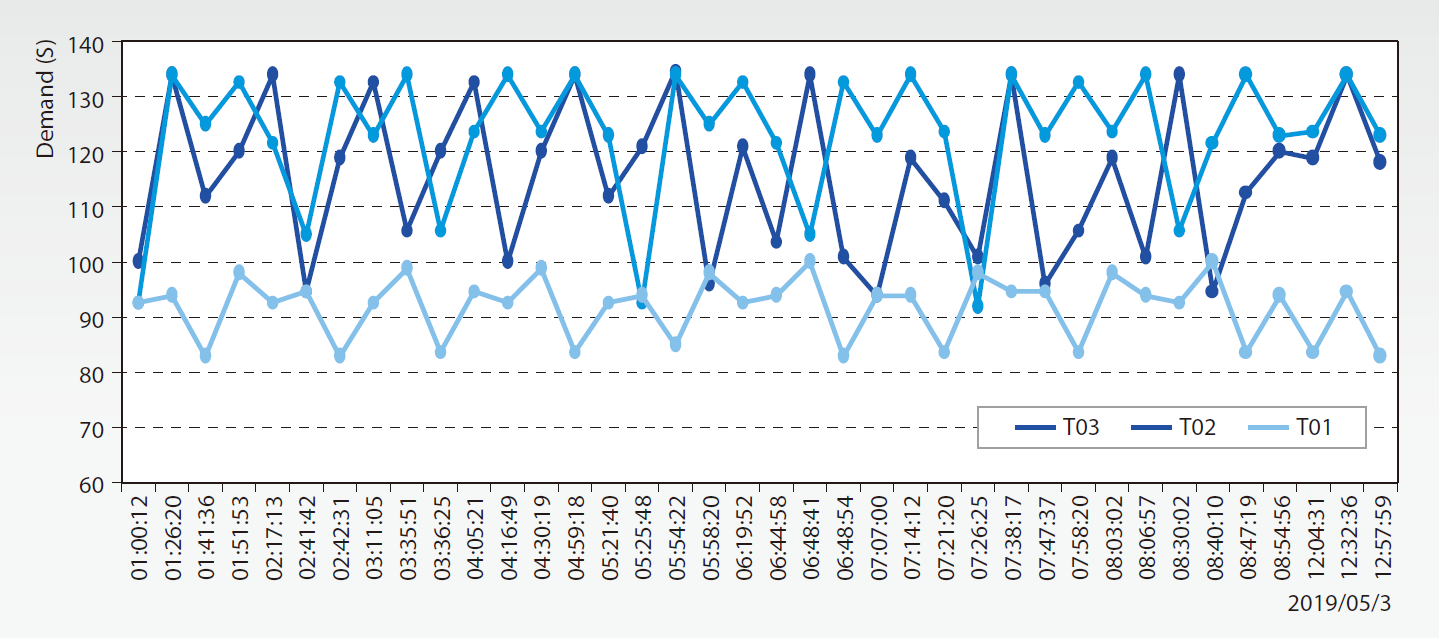
「趨勢分析」 - 設備各機型要酸模式分析 :
各機型要酸模式分析,如 圖16。提供新建廠設計參考,精準規劃系統Capacity,即時正確的Bluebook SP1/2排點。要酸trend chart與用量異常alarm連動列出,值班人員可即時精準分析確認異常機台。
圖16、Tool Chemical要酸模式及用量分析
「分群」- 分群定義VMB階層
Alarm緊急應變相關資訊:Alarm發生時立即mail相關資訊
- Leak alarm:立即mail影響機台
- Pressure Lo:立即mail出口壓力trend chart及該時間點機台要酸紀錄
- 用量異常:立即mail出口流量trend chart及該時間點機台要酸紀錄
- 排酸異常:立即mail WLS收酸trend chart及WLS廢液排放分佈圖
「關聯」特徵應用-關鍵字查詢
利用關聯分析結果,以輸入關鍵字Tool ID/chemical 方式收尋資料庫,可立即列出相關資訊,如 圖17,非系統負責人值班時也可簡單快速的查詢相關資訊,盡可能在系統異常時,迅速找到問題解答,緊急應變每一秒都是關鍵,建立關鍵字查詢,縮短值班應變時的決策時間,避免錯失搶救黃金時間。
圖17、關鍵字查詢功能
「循序特徵」Data mining 應用目標
SCADA紀錄了諸多運轉資訊,但往往只有直接影響供應的警報資訊會被關注並分析應變方針,例如:品質相關項目及壓力資訊等,部分priority 300以下的警報被淹沒在龐大的資料庫中,時間周期到點後被刪除,這些資料若沒經過運算分析是沒有價值的,而每次分析龐大資料需耗費龐大的人力資源,以自動化取代人力運算,資訊只要經過Data mining就有機會變成Data money,如 圖18。
圖18、Alarm data mining示意圖
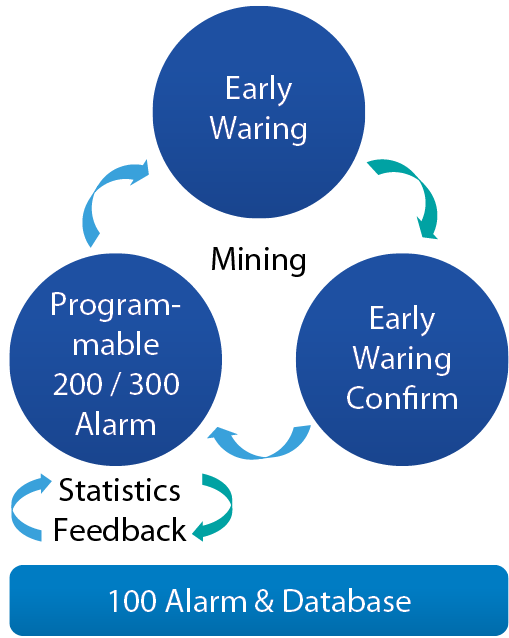
發生直接影響生產的100 alarm前,大多會先觸發等級200 或300以下的alarm,若可預先監控頻率周期,可避免100 alarm發生,例如1%HF供應濃度異常OOS alarm發生前一個月,mixing tank發生濃度異常的次數增加,補償的次數也增加,若建立Data mining機制,分析警報頻率的周期趨勢,便有機會預先發現問題先行改善,避免停線異常或人員操作MO造成損失。
結論
本研究以OPC整合各系統PLC通訊協定,突破目前SCADA擴充點數上限之限制,利用bluebook更新預警機制達到底層資料正確性,並結合FHM Barcode資料與Hookup QC Report來檢查資料完整性;以此方法整合上下層關聯,提升資料可靠度,克服以往無法整合零散資訊的問題,且於系統架構上,跳脫原本認知框架,期望以此新架構與OneFAC進行資料交換,解決現今上下游資料不同步,無法即時更新之窘境。
未來發展方向
在邏輯線徑越來越小的趨勢下,每片晶圓的產值大幅提升,不論在供應品質或是穩定度上,廠務最重要的課題是不影響Fab生產,藉由此套Datamining模式,可提早預防「供應中斷、品質異常、ESH事件」的發生,亦可將「已經發生的問題快速收斂與解決」,系統不斷更新學習,將更多系統表現模式化(Modeling),發現更多資料的關係與特徵,及發掘更多未知的關鍵報告,亦可建立未來機器學習的雛形。
參考文獻
- 鄭書湧,以專家系統應用在廠務監控系統之研究-以廢氣處理系統為例。國立成功大學,2013。
- 徐嘉立,全面廠務服務方案之研究-以半導體產業為例。國立清華大學,2014。
- 清威人,智慧工廠,經濟新潮社出版,2018。
- Long Hu, iRobot-Factory: An intel-ligent robot factory based on cogni-tivemanu-facturing and edge com-puting, 2018.
- JaehyeongLee, Design and Applica-tions of Agile Factory AaaS Archite-cture Basedon Container-based Virtualized Automation Control Unit, 2019.
- David S. Linthicum, “Enterprise Appli-cation Integration”, Addison-Wesley Professional, 2000.
- Berry, M., and Linoff, G. Data Mining Technique: For Marketing, Sales, and Customer Support. New York: Wiley Computer Publishing, 1997.
- Macqueen J., Some Methods for Classification and Analysis of Multi-Variate Observations. Proc. of, Berke-ley Symposium on Mathematical Statistics and Proba-bility. P.281-297, 1967.
- Agrawal, R., Imielinski T. & Swami, A. “Mining Association Rules Between Sets of Itemsin Large Data bases,” In proceedings Of the ACM SIGMOD Conference on Management of Data, Washington DC, USA, 1993.
- R. Agrawal. and R. Srikant, “Mining SequentialPatterns,” The 11th Interna-tional Conference onData Engi-neering, Taiwan, 1995.
留言(0)